| 序号 | 内容 | 链接地址 |
|---|---|---|
| 1 | Java面试题 | https://blog.csdn.net/golove666/article/details/137360180 |
| 2 | JVM面试题 | https://blog.csdn.net/golove666/article/details/137245795 |
| 3 | Servlet面试题 | https://blog.csdn.net/golove666/article/details/137395779 |
| 4 | Maven面试题 | https://blog.csdn.net/golove666/article/details/137365977 |
| 5 | Git面试题 | https://blog.csdn.net/golove666/article/details/137368870 |
| 6 | Gradle面试题 | https://blog.csdn.net/golove666/article/details/137368172 |
| 7 | Jenkins 面试题 | https://blog.csdn.net/golove666/article/details/137365214 |
| 8 | Tomcat面试题 | https://blog.csdn.net/golove666/article/details/137364935 |
| 9 | Docker面试题 | https://blog.csdn.net/golove666/article/details/137364760 |
| 10 | 多线程面试题 | https://blog.csdn.net/golove666/article/details/137357477 |
| 11 | Mybatis面试题 | https://blog.csdn.net/golove666/article/details/137351745 |
| 12 | Nginx面试题 | https://blog.csdn.net/golove666/article/details/137349465 |
| 13 | Spring面试题 | https://blog.csdn.net/golove666/article/details/137334729 |
| 14 | Netty面试题 | https://blog.csdn.net/golove666/article/details/137263541 |
| 15 | SpringBoot面试题 | https://blog.csdn.net/golove666/article/details/137192312 |
| 16 | SpringBoot面试题1 | https://blog.csdn.net/golove666/article/details/137383473 |
| 17 | Mysql面试题 | https://blog.csdn.net/golove666/article/details/137261529 |
| 18 | Redis面试题 | https://blog.csdn.net/golove666/article/details/137267922 |
| 19 | PostgreSQL面试题 | https://blog.csdn.net/golove666/article/details/137385174 |
| 20 | Memcached面试题 | https://blog.csdn.net/golove666/article/details/137384317 |
| 21 | Linux面试题 | https://blog.csdn.net/golove666/article/details/137384729 |
| 22 | HTML面试题 | https://blog.csdn.net/golove666/article/details/137386352 |
| 23 | JavaScript面试题 | https://blog.csdn.net/golove666/article/details/137385994 |
| 24 | Vue面试题 | https://blog.csdn.net/golove666/article/details/137341572 |
| 25 | Ajax面试题 | https://blog.csdn.net/golove666/article/details/137421929 |
| 26 | Python面试题 | https://blog.csdn.net/golove666/article/details/137385635 |
| 27 | Spring Cloud Alibaba面试题 | https://blog.csdn.net/golove666/article/details/137372112 |
| 28 | SpringCloud面试题 | https://blog.csdn.net/golove666/article/details/137345465 |
| 29 | RabbitMQ面试题 | https://blog.csdn.net/golove666/article/details/137344188 |
| 30 | Dubbo面试题 | https://blog.csdn.net/golove666/article/details/137346834 |
| 31 | Elasticsearch面试题 | https://blog.csdn.net/golove666/article/details/137348184 |
| 32 | Oracle面试题 | https://blog.csdn.net/golove666/article/details/137350452 |
| 33 | Android面试题 | https://blog.csdn.net/golove666/article/details/137358253 |
| 34 | Kafka面试题 | https://blog.csdn.net/golove666/article/details/137358607 |
| 35 | ZooKeeper面试题 | https://blog.csdn.net/golove666/article/details/137359255 |
| 36 | Kubernetes面试题 | https://blog.csdn.net/golove666/article/details/137365540 |
| 37 | Flink面试题 | https://blog.csdn.net/golove666/article/details/137369555 |
| 38 | Hadoop面试题 | https://blog.csdn.net/golove666/article/details/137370194 |
| 39 | Hive面试题 | https://blog.csdn.net/golove666/article/details/137371835 |
| 40 | Hbase面试题 | https://blog.csdn.net/golove666/article/details/137381853 |
| 41 | Spark面试题 | https://blog.csdn.net/golove666/article/details/137382815 |
| 42 | Golang面试题 | https://blog.csdn.net/golove666/article/details/137395486 |
| 43 | Solr面试题 | https://blog.csdn.net/golove666/article/details/137420799 |
1. HBase 基础概念
1.1 解释 HBase 是什么以及它与其他 NoSQL 数据库的比较
HBase 是什么?
HBase 是一个开源的非关系型分布式数据库(NoSQL),它是由 Apache 软件基金会维护的。它构建在 Hadoop 文件系统(HDFS)之上,提供了对于大规模数据集的随机实时读/写访问能力。
HBase 是基于 Google 的 BigTable 论文设计的,并提供了类似的功能:通过使用 Hadoop 的数据存储和处理能力,HBase 能以水平扩展的方式在廉价机器集群上储存巨量数据。它通常被用于实时查询和分析面向列的大数据。
HBase 特点
- 水平扩展:只要新增节点就能提供更多存储和处理能力。
- 面向列的存储:能够高效地处理不同列的大量数据,并支持动态列模型。
- 强一致性:不像某些 NoSQL 数据库使用最终一致性,HBase 提供行级别的强一致性。
- 易于集成:和 Hadoop 生态系统中其他项目(如 Hive、Spark 等)有良好整合。
- 支持自动分片:表数据自动在 RegionServers 之间分片。
HBase 与其他 NoSQL 数据库比较
-
与 Cassandra:
Cassandra 提供了更高的写吞吐量和最终一致性模型,支持多个数据中心,更适合需要跨地理位置灾备能力的环境。相比之下,HBase 提供了强一致性并且依赖 Hadoop 生态。 -
与 MongoDB:
MongoDB 是一个文档型数据库,优秀的支持复杂的文档结构和丰富的查询语言。HBase 更加侧重于大型扫描操作和紧密整合与 Hadoop 生态的批量数据处理。 -
与 DynamoDB:
DynamoDB 是 AWS 提供的一种托管性 NoSQL 数据库服务,主要优点包括易于使用和管理。相较之下,HBase 更适合那些想要完整控制其基础设施的用户,同时还需要处理更大规模的数据集。 -
与 Couchbase:
Couchbase 提供许多为企业应用定制的特性,如全文搜索和SQL-like查询语言(N1QL)。HBase 更适合与 Hadoop 紧密耦合,用于大数据存储和处理的场景。
HBase 的选择取决于具体的应用场景,比如需求对于强一致性的重视程度、对集群大小的要求、以及对 Hadoop 生态其他组件(如 Spark、Hive等)整合的需求。在对于大数据读写性能拥有特殊需求,且已有的 Hadoop 基础设施的情况下,HBase 可能是一个理想的选择。
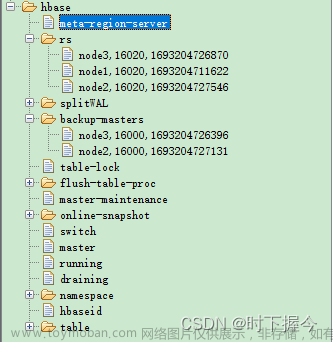
1.2 描述 HBase 的架构和核心组件
Apache HBase 是一个分布式的、可扩展的、支持列式存储的非关系型数据库。它建立在 Hadoop 文件系统(HDFS)之上,利用 Hadoop 的分布式存储和计算能力,提供类似于谷歌 Bigtable 的数据存储服务。以下是 HBase 的主要架构和核心组件:
核心组件
-
HMaster:
- HBase 的主节点负责管理和协调集群。
- 它执行诸如分配 region、处理节点的加入和离开以及负载平衡等任务。
- HMaster 确保集群的运行状态,它也会执行 DDL(Data Definition Language)操作,例如创建和删除表。
-
RegionServers:
- 是工作节点,负责管理表的 region(区域/分片),处理读写请求和数据存储操作。
- 一个集群会有多个 RegionServers,用于保证数据的高可用性和负载分散。
-
Region:
- HBase 表被水平划分为多个 region,是表存储的基本单位。
- 每个 region 由一个 RegionServer 管理,随着数据量的增长,region 可以被分裂(split)并重新进行负载平衡。
-
HLog(WAL,Write-Ahead Log):
- 在写入数据前先写入日志的机制,用于确保在发生故障情况下能够恢复数据。
- HLog 记录所有对数据的更改,是系统的重要组成部分,保证了数据修改操作的持久性和原子性。
-
Store:
- 是 RegionServer 中的一个组件,用于管理存储。每个 region 包括一个或多个 store。
- Store 对应于表中的一个列族(column family),包含了保存数据的文件和索引。
-
MemStore:
- 是一个内存中的缓冲区,用于暂存还未刷新到硬盘的数据。
- 当 MemStore 超过一定大小时,数据会被刷新到硬盘上,形成一个新的 HFile。
-
HFile:
- 是基于 HDFS 的文件格式,用于持久化存储 region 的数据。
- HFiles 存储了实际的键值对(key-value)数据,支持快速查找。
-
ZooKeeper:
- HBase 使用 ZooKeeper 作为协调服务,用于集群中各个组件的状态同步和原子性操作保证。
- ZooKeeper 负责 master 和 region server 的状态跟踪,以及集群配置等。
架构概览
-
Client:
- 客户端通过 HBase API 与集群进行交互,实现数据的 CRUD 操作。
- 它与 ZooKeeper 通信来查找 region 所在的 RegionServer 的位置等信息。
-
Meta Table:
- 跟踪和记录所有 region 的位置信息,是 location lookup table。
HBase 的强大之处不仅在于它能够处理大量的数据,同时也在于它的高度可靠性、扩展性以及基于HDFS所提供的容错能力。
1.3 讲述 HBase 中的表、行、列族和列限定符
HBase 是一个开源的、非关系型的、分布式的列式存储系统,它建立在 Hadoop 文件系统(HDFS)之上,提供了类似于传统数据库的能力来存储非结构化和半结构化的大量数据。HBase 使用表(Table)、行(Row)、列族(Column Family)和列限定符(Column Qualifier)等概念来组织数据。
表(Table)
一个 HBase 表是存储数据的容器,类似于关系型数据库中的表。每个表由行和列组成,并且可以存储巨量的数据。在 HBase 中,表是水平分布式的,意味着随着数据量的增长,它可以被自动切分成区域(Regions)并分散存储在集群的多个节点上。
行(Row)
在 HBase 表中,每一行数据由唯一的行键(Row Key)标识。行键是字节串,HBase 会按照字典顺序来存储这些行。行是 HBase 中数据检索的主要方式,你可以根据行键快速访问到行中的数据。
列族(Column Family)
列族是 HBase 表中的一个高级数据容器,它存储了具有相同前缀的列限定符。在 HBase 中,所有列都归属于某个列族,而列族在表创建时就必须定义,并且不可轻易更改。列族内的每一列都可以有自己独立的版本(Version)和时间戳(Timestamp)。
列限定符(Column Qualifier)
列限定符描述了数据在列族中的具体列位置。在 HBase 中,列被表述为 ColumnFamily:ColumnQualifier 的格式,其中列限定符指出了该列的类型或名称。列限定符加上列族构成了一个特定的列。与传统数据库的区别在于,HBase 的列限定符可以是动态的,并不需要预先在表结构中定义。
版本和时间戳(Version and Timestamp)
HBase 利用时间戳版本机制来存储数据的历史变更。每当列中的数据被更新时,HBase 将根据写操作发生的时间,创建该数据的一个新版本。默认情况下,每个列存储的版本数量有限制,超出限制的旧数据会被自动删除,但这个参数是可调的。
HBase 的使用场景
HBase 非常适用于快速随机访问大量稀疏表数据的应用场景,特别是当数据模型需求无法用传统关系型数据库有效解决时。其典型用例包括搜索引擎、日志和事件数据分析、实时数据处理、NoSQL 数据存储等。
总结来说,HBase 中的表、行、列族和列限定符提供了一种灵活的方式来存储和处理海量数据。通过合理地设计表结构,我们可以依托 HBase 来构建可伸缩的大数据应用。
2. HBase 数据模型
2.1 讨论 HBase 的数据存储模型和物理存储结构
Apache HBase 是一个开源的、分布式的、大规模的列式存储 NoSQL 数据库,它基于 Google 的 Bigtable 架构构建,用于存储大量的结构化数据,并能够提供实时读/写访问权限。HBase 架构的设计使其特别适用于快速随机访问大量的稀疏数据集。下面将分别讨论 HBase 的数据存储模型和物理存储结构。
数据存储模型
HBase 将数据存储在一个称为表(Table)的结构中,表由行(Rows)和列(Columns)组成。其数据模型主要特点如下:
-
行键(Row Key):
- 每行数据通过唯一的行键来标识。
- 行键决定了数据在 HBase 中的分布。
-
列族(Column Families):
- 列被组织成列族,列族是物理存储和访问控制的基本单元。
- 列族中的列是动态定义的,即在使用时可以随时添加新的列。
-
列限定符(Column Qualifiers):
- 在列族中,实际的数据是通过列限定符来标识的,列限定符可以为任意字符串。
-
时间戳(Timestamps):
- 每次更新都会附带一个时间戳,时间戳可以用于检索数据的历史版本。
-
单元格(Cells):
- 表格中的每个数据单元称为单元格,单元格由行键、列族、列限定符和时间戳唯一确定,并存储一个数据值。
物理存储结构
HBase 以文件的形式将数据存储在 Hadoop 文件系统(如 HDFS)上。物理存储的组织方式有以下几点:
-
HFile:
- HBase 数据存储在 HDFS 上的文件格式称为 HFile,HFile 是存储行数据的实际物理容器。
-
区域(Regions):
- 表被水平拆分成多个区域,每个区域包含行键的一个范围。
- 区域是分布式和负载均衡的基本单元,区域会被自动分配到区域服务器。
-
数据块(Blocks):
- HFile 被进一步划分为数据块,提高随机读取的效率。
- 数据块在 HFile 中通过索引进行管理,便于快速查找。
-
WAL(写前日志,Write-Ahead Log):
- 所有写入操作首先记录在 WAL 中,确保数据在发生故障时可恢复。
- WAL 是 HBase 系统的持久化和故障恢复的关键。
-
MemStore:
- 每个区域服务器上有 MemStore 结构,用于缓存最近写入的数据,在达到一定大小后持久化到 HFile。
-
StoreFile 和 Compaction:
- MemStore 数据持久化后变为 StoreFile,随着时间的推移,会进行合并(Compaction)操作以优化查询效率和存储空间使用。
表格存储特性
- HBase 的存储模型是稀疏的,这意味着不存在的列并不占用任何存储空间。
- 支持数据压缩和分区,高效地查询大数据集。
- 通过合适的行键设计实现数据分布的均衡,优化读写性能。
总的来说,HBase 的数据存储模型和物理存储结构为大规模数据的存储和实时访问提供了强有力的支持,这使得 HBase 成为高可扩展性、高性能和高可用性应用的理想选择。
2.2 描述 HBase 中的行键设计和列族优化
在 HBase 中,行键(Row Key)设计和列族(Column Family)优化对于确保高性能和可扩展性至关重要。以下是一些关于行键设计和列族优化的最佳实践:
行键设计
-
长度和格式:
- 行键应足够短,避免过长,因为它们会在每个存储单元中重复,并且会影响存储和性能。
- 使用固定长度的行键可以优化 I/O 操作和内存使用。
-
避免热点:
- 行键设计应避免数据热点,即避免某一部分节点比其它节点承载更高的读写压力。
- 可以通过散列行键前缀、使用反转时间戳或加盐(Salting)等方式随机分布写操作。
-
有序性:
- 如果需要的话,设计有序的行键以支持范围扫描,但需注意避免因此产生热点。
- 按时间戳降序存储数据可以使最新数据总是保持在表的前面。
-
二进制比较:
- HBase 是按字典顺序存储行键的,行键是以二进制方式比较的,因此确认你的行键设计能够有效支持二进制比较。
列族优化
-
数量:
- 列族的数量应当保持在最小。过多的列族会消耗更多内存,并同时增加内存压力和并发问题。
- 普遍推荐的列族数量是不超过 2-3 个。
-
设计:
- 类似访问模式的列应该放在同一个列族内。HBase 按列族为单位进行 I/O 操作,所以相关数据放在一起能优化性能。
-
存储和压缩:
- 可以为每个列族独立设置存储策略和压缩算法。
- 压缩可以减少存储空间和 I/O,但也会导致更高的 CPU 使用。适当选择压缩算法(例如:Snappy、GZIP)。
-
版本管理:
- 列族内的列可以配置多个版本。确保为每个列正确设置版本数量,以避免无用数据占用太多空间。
-
TTL 和数据清理:
- 可以为列族或列设置 TTL(Time To Live),用于自动清理过期数据。
-
内存优化:
- COLUMN_FAMILY_MEMSTORE_FLUSH_SIZE 设置影响列族存储在内存中的大小,直到触发 MemStore Flush 到磁盘。适当配置可提高写入性能。
结合使用
在表设计阶段应同时考虑行键设计和列族优化,因为它们共同决定了 HBase 在数据读写时的性能表现。良好的设计可以减少全表扫描,优化读/写路径,从而达到高性能和可伸缩的目标。
在实践中,设计和优化过程通常需要结合具体的应用场景和数据访问模式进行。而测试和调整可能是一个持续的过程,随着数据量和访问模式的变化,可能需要对行键和列族进行调整来保证性能。
2.3 解释 HBase 的多版本并发控制(MVCC)
HBase 的多版本并发控制(MVCC)是一种用于管理并发访问和快照隔离的机制。HBase 是一个分布式、可扩展的大数据存储,它借鉴了 Google 的 Bigtable 架构。在 HBase 中,数据(行)是按照键值对形式存储的,每个键包括行键、列族、列限定符和时间戳。MVCC 允许系统在不锁定表的情况下进行高效的读写操作,确保了一致性和隔离性。
MVCC 的原理
当数据被写入 HBase 时,每个单元(cell)都会附上一个时间戳。HBase 通过这些时间戳来管理数据的不同版本。MVCC 在此基础上提供了以下能力:
-
快照读取:读操作可以获取到写操作开始之前的数据快照,即使在写操作正在进行中,读操作也不会看到未提交数据。这使得读操作不会被写锁定阻塞。
-
隔离级别:HBase 通过 MVCC 提供了 “读已提交”(read-committed)的隔离级别。在这个级别下,读取操作只能看到已经提交的数据版本。
-
写操作:每个写操作在提交之前都会获得唯一的 MVCC 版本号。这个版本号比其他现有版本号高,并用于所有单元的新版本。提交完成后更新版本号,以此保证其他操作可以看到这个版本。
-
检查时间戳:版本号用于解决读写冲突。当读操作发生时,它将看到小于或等于其自己 MVCC 版本号的数据单元的最新版本。
-
垃圾回收:HBase 利用时间戳和 MVCC 可以进行有效的垃圾回收。当每个单元都不再可见时(即它已经过时或超出了版本限制),它可以安全地删除。
读写操作的并发控制
- 写操作会被分配一个 MVCC 读写点(read-write point),该点是在操作开始时获得的全局递增的事务 ID。
- 读操作通过 MVCC 能够安全地读取那些小于它自己读点(read point)的提交点(commit point)的数据。
用户指定时间戳
HBase 允许用户在写入数据时指定自定义时间戳。这为应用提供了额外的灵活性,比如重放日志或批量加载历史数据。
总结
MVCC 是 HBase 能够提供快速、一致和并发操作的关键特性之一。它为用户访问历史数据版本提供了简单的抽象,并且补充了 HBase 强大的读性能。通过这种控制机制,HBase 能够在高吞吐量的情况下同时支持大量的读和写操作,这对大规模应用来说非常重要。
3. HBase 操作和 API
3.1 讲述如何在 HBase 中进行数据的增、删、改、查操作
HBase 是一个基于列的分布式数据库,与关系数据库相比,它的数据增加、删除、更新和查询(CRUD)操作有些不同,但依然可以通过 HBase Shell 或客户端 API 来完成。以下是如何在 HBase 中执行这些操作的简介:
在 HBase 中添加(增)数据
数据在 HBase 中以行的形式存储,而行是由列族和列限定符(列名)组成的。插入数据通常是指为某个行键(Row Key)的列分配一个值。
在 HBase Shell 中,可以使用 put 命令添加数据:
put 'table_name', 'row_key', 'column_family:column_qualifier', 'value'
通过客户端 API,例如在 Java 中:
Table table = connection.getTable(TableName.valueOf("table_name"));
Put p = new Put(Bytes.toBytes("row_key"));
p.addColumn(Bytes.toBytes("column_family"), Bytes.toBytes("column_qualifier"), Bytes.toBytes("value"));
table.put(p);
在 HBase 中删除数据
在 HBase 中,删除操作可以具体到行、列族、列限定符,甚至是列的一个版本。
使用 Shell 删除某行的数据:
delete 'table_name', 'row_key', 'column_family:column_qualifier'
在 Java 中进行删除:
Table table = connection.getTable(TableName.valueOf("table_name"));
Delete d = new Delete(Bytes.toBytes("row_key"));
d.addColumn(Bytes.toBytes("column_family"), Bytes.toBytes("column_qualifier"));
table.delete(d);
在 HBase 中更新数据
HBase 中的更新操作与插入操作类似,都是使用 put 命令。如果 put 命令的行键和列限定符已经在表中存在,则原有的值会被新值覆盖。
在 HBase Shell 更新数据:
put 'table_name', 'row_key', 'column_family:column_qualifier', 'new_value'
在 Java 中用相同的 Put 实例更新数据:
Put p = new Put(Bytes.toBytes("row_key"));
p.addColumn(Bytes.toBytes("column_family"), Bytes.toBytes("column_qualifier"), Bytes.toBytes("new_value"));
table.put(p);
在 HBase 中查询数据
查询可以分为两种:获取某一行的数据(get),或者扫描(scan)多行数据。
使用 Shell 获取单行数据:
get 'table_name', 'row_key'
使用 Java API 查询:
Get g = new Get(Bytes.toBytes("row_key"));
Result result = table.get(g);
使用 Shell 扫描数据:
scan 'table_name'
或者在 Java 中定义扫描器进行数据扫描:
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
// 处理获取的每行数据
}
在使用 HBase 时,考虑在适当时加入过滤器(Filter)可以大大提升查询效率,尤其是针对大量数据的扫描。此外,HBase 的数据操作都是针对特定的时间戳版本,每个值都存储为一个特定版本。默认情况下,获取的是最新的版本,但可以获取更早的版本。
3.2 描述 HBase 客户端 API 的使用和 HBase Shell 命令
Apache HBase 提供了丰富的客户端 API,允许开发者从程序代码中进行数据存取、管理表结构以及执行其他操作。此外,HBase 也提供了一个命令行工具,即 HBase Shell,它允许用户通过简单的命令行语句来操作 HBase 数据库。
使用 HBase 客户端 API
-
初始化
在 Java 程序中,首先需要初始化Configuration对象和Connection对象来与 HBase 集群通信。Configuration config = HBaseConfiguration.create(); try (Connection connection = ConnectionFactory.createConnection(config); Admin admin = connection.getAdmin()) { // 使用 `admin` 来管理表结构 } -
数据操作
使用Table接口来进行数据的 CRUD(创建、查询、更新、删除)操作。Table table = connection.getTable(TableName.valueOf("myTable")); Put put = new Put(Bytes.toBytes("row1")); put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("qualifier"), Bytes.toBytes("value")); table.put(put);使用
Get,Scan,Delete等类来读取、扫描和删除数据。 -
表管理
使用Admin接口来创建、删除、列出和管理表和列族。HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("myTable")); tableDescriptor.addFamily(new HColumnDescriptor("myFamily")); admin.createTable(tableDescriptor);
使用 HBase Shell 命令
HBase Shell 是一个基于 JRuby 的交互式命令行工具。它简化了向 HBase 集群发送命令的过程,无需编写程序即可进行各种操作。
-
启动 HBase Shell
在 HBase 安装目录下用命令行启动 Shell:hbase shell -
表操作
创建、列出、修改和删除表。create 'myTable', 'myFamily' list 'myTable' describe 'myTable' disable 'myTable' drop 'myTable' -
数据操作
对数据执行插入(put)、读取(get)、扫描(scan)和删除(delete)操作。put 'myTable', 'row1', 'myFamily:qualifier', 'value' get 'myTable', 'row1' scan 'myTable' delete 'myTable', 'row1', 'myFamily:qualifier' -
管理操作
执行 HBase 集群管理相关的命令,如状态查看、启动/停止复制等。status version
使用 HBase 客户端 API 或 HBase Shell 可以有效地对 HBase 集群和存储在其中的数据进行管理和操作。选择哪种工具取决于你的具体需求 —— 对于开发应用程序,HBase 客户端 API 提供了更大的灵活性;对于快速原型开发或者进行即时操作,Shell 可能是一个更方便的选择。
3.3 讨论 HBase 中的扫描操作和过滤器的应用
HBase 是一个基于 Hadoop 的列式非关系数据库,它提供了多种丰富的数据库操作,其中「扫描」(Scan)是其核心功能之一。扫描操作用于从 HBase 表中检索一系列的行及其列数据。为了对扫描结果进行细粒度控制,HBase 也提供了一组强大的过滤器(Filters)。
扫描操作(Scan)
-
基本概念:
- 扫描操作允许你选择要检索的行及范围,可以是单行,也可以是一个起始行到终止行之间的范围。
- 扫描操作可以返回这一范围内所有行的全部数据,或只返回指定列族或列限定符的数据。
-
实现方式:
- 在 HBase 中,使用
Scan类来定义扫描操作的参数,如起始行、停止行、时间戳范围和特定列。 - 开发者可以使用
Table接口提供的getScanner方法来执行实际的扫描,并获取迭代器以遍历结果。
- 在 HBase 中,使用
-
优化扫描:
- 指定越精确的列、时间戳和范围,扫描操作通常会更有效率。
- 通过分页、限制每次扫描返回的行数量,可以避免一次性加载过多数据到内存中。
-
使用场景:
- 扫描操作适用于需要读取多行数据的场景,如数据分析、报表生成和数据迁移等。
过滤器(Filters)
-
基本概念:
- 过滤器用于将不需要的数据从扫描结果中剔除,比如根据列值、键值匹配、正则表达式等条件过滤。
- HBase 提供了各种类型的过滤器,如
RowFilter、FamilyFilter、QualifierFilter、ValueFilter等。
-
实现方式:
- 在定义
Scan对象时添加过滤器,可以组合使用多个过滤器来实现复杂的查询逻辑。 - 过滤器在服务端执行,减少了客户端需要处理的数据量。
- 在定义
-
优化使用过滤器:
- 使用过滤器时,如果能在 RowKey 设计时考虑查询模式,可以使过滤更高效,因为 HBase 基于 RowKey 的扫描是最快的。
- 许多过滤器可以通过「过滤器链」结合使用,以更精细地控制返回结果。
-
使用场景:
- 过滤器广泛应用于数据查询、权限检查(例如仅返回用户有权查看的列)和数据清洗等场景。
在开发时,均衡使用扫描操作和过滤器可以提高应用性能,因为它们减少了不必要的数据传输,并允许更精确的数据读取。通过一个精心设计的 RowKey 结构和恰当的过滤器组合,可以显著提升对海量数据集的查询效率。
4. HBase 集群部署和配置
4.1 解释 HBase 集群的安装和配置要点
安装和配置 HBase 集群包含一系列详细的步骤,旨在确保每个组件正常工作,同时满足系统的性能和可靠性要求。以下是执行 HBase 集群安装和配置的要点:
一、系统要求
- Java 环境:HBase 要求安装 Java 运行环境(JRE),推荐安装 Java 开发工具包(JDK)。
-
Hadoop 环境:HBase 运行在 Hadoop 文件系统(HDFS)之上,因此需要有一个已经配置和运行的 Hadoop 集群。确保 Hadoop 的
hdfs-site.xml和core-site.xml配置文件正确配置。
二、下载和解压 HBase
从 HBase 官方网站下载适配 Hadoop 版本的 HBase 二进制包,并将其解压到集群的所有节点上。
三、配置文件
修改 HBase 的配置文件来适应集群环境,这些配置文件通常位于 HBase 安装目录的 conf/ 子目录中:
- hbase-site.xml:这是 HBase 的主要配置文件,用于设置 HBase 集群运行相关的参数,如 ZooKeeper 集群信息、HBase 使用的文件系统等。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode/fullpath</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zknode1,zknode2,zknode3</value>
</property>
<!-- 其他配置 -->
</configuration>
-
hbase-env.sh:设置 HBase 运行所需的环境变量,例如 Java 运行环境、Java 运行参数、日志文件位置等。
-
regionservers:列出所有 HBase 区域服务器的主机名称。
四、ZooKeeper 配置
HBase 依赖于 ZooKeeper,用于管理集群元数据和节点协调:
- 确保有一个运行中的 ZooKeeper 集群。
- 在
hbase-site.xml设置 ZooKeeper 集群的地址和端口。
五、启动 HBase 集群
所有配置完成后,可以使用以下命令启动 HBase 集群:
start-hbase.sh
六、验证安装
验证 HBase 是否正确安装和启动:
- 使用 jps 命令检查 HBase 相关进程是否运行。
- 访问 HBase 的 Web UI,默认端口为 16010。
七、高可用性配置
为了生产环境的稳定运行,可能需要配置 HBase 为高可用性:
- 配置 HDFS NameNode 高可用性。
- 设置多个 HBase Master 节点来提供热备份。
- 跨机架(rack)分配 RegionServer 实例来避免单点故障。
八、性能优化
调整配置以优化集群性能:
- 为 HBase 和 RegionServer 分配适当的内存和 JVM 选项。
- 根据负载调整 RegionServer 数量和 HBase 表的区域分割策略。
九、安全配置
为了保护数据安全,可能需要在 HBase 上配置安全措施:
- 启用 Kerberos 认证保护数据传输。
- 配置 HDFS 和 HBase 之间的透明加密。
请注意,这些要点仅提供了一个大概的安装和配置流程。在实际部署 HBase 集群时,你需要详细规划和精确配置以满足具体的使用案例和性能需求。始终建议在进行任何生产部署之前,仔细阅读并理解 HBase 官方文档中的指南和最佳实践。
4.2 描述 HBase 集群的启动和停止流程
在 HBase 集群中,启动和停止流程一般遵守下面的步骤,以确保所有组件都能正确地启动和优雅地停止:
HBase 集群启动流程
-
启动 Hadoop 集群:
确保 HBase 所依赖的 HDFS 和 ZooKeeper 服务已经启动并运行。如果在伪分布式或全分布式模式,需要先启动 Hadoop NameNode 和 DataNode。# 启动 HDFS start-dfs.sh # 向 ZooKeeper 提供服务的集群也需要启动 zkServer.sh start -
启动 HBase 服务:
HBase 使用自己的脚本来启动所有相关的进程。# 启动 HBase start-hbase.sh这个脚本会首先启动 HBase Master,然后根据配置在所有 RegionServer 节点上启动 RegionServer 进程。
HBase 集群停止流程
-
停止 HBase 服务:
在停止 HBase 之前,应确保所有客户端请求已完成或暂停。# 停止 HBase stop-hbase.sh此脚本会优雅地关闭所有 RegionServer,让它们完成当前的操作,并随后停止 HBase Master。
-
停止 Hadoop 集群:
一旦 HBase 安全停止,接着可以停止 Hadoop DFS 和其它相关依赖服务。# 停止 HDFS stop-dfs.sh # 停止提供服务的 ZooKeeper 集群 zkServer.sh stop
注意事项
- 始终按照正确顺序启动和停止 HBase,先启动依赖的服务,即先 HDFS 和 ZooKeeper,后 HBase。
- 优雅地关闭 HBase 可以避免数据丢失或者损坏。RegionServer 会尝试将内存中的内容刷新到磁盘,关闭前完成正在进行的操作。
- 在分布式环境中,可能需要登录到每个节点上分别启动或停止 ZooKeeper 服务。
- 应该定期监控 HBase 集群的日志文件,以便在启动或停止时诊断潜在问题。
- 在执行版本升级或维护之前备份 HBase 数据是一个良好的实践。
- 确保使用与集群配置相匹配的用户身份运行启动和停止命令,通常是具有 HDFS 和 HBase 读写权限的用户。
HBase 的启动和停止通常由集群管理员按需手动执行,或者在集群管理工具(如 Cloudera Manager 或 Apache Ambari)的帮助下自动化执行。始终遵循最佳操作实践可以帮助维护 HBase 集群的健康和稳定性。
4.3 讲述 HBase 集群配置参数的调优和优化
调优和优化 HBase 集群配置需要综合考虑硬件资源、数据模型、工作负载特征以及集群的使用模式。以下是一些常见的 HBase 集群配置参数调优和优化策略:
1. 区域大小(Region Size)
- 调整
hbase.hregion.max.filesize参数来控制区域分裂的大小。合理的区域大小有利于负载均衡和性能优化。太大或太小的区域都可能导致性能问题。
2. 区域服务器内存(RegionServer Memory)
- 分配足够的内存给
hbase.regionserver.heapsize,以确保区域服务器能高效处理请求。内存量通常取决于工作负载类型和集群大小。
3. MemStore 大小
- 配置 MemStore 大小
hbase.hregion.memstore.flush.size和hbase.regionserver.global.memstore.size.lower.limit。MemStore 是 HBase 中用于存放新写入数据的内存结构,配置得当可提高写入性能。
4. HFile 块大小
- 通过
hbase.hfile.block.cache.size参数配置块缓存大小,块缓存用来存储经常访问的数据,能有效减少磁盘 I/O。
5. 压缩和编码
- 启用压缩
hfile.block.compress以减少磁盘占用和I/O需求。常见的压缩格式包括 GZIP、Snappy 和 LZO。 - 启用数据块编码(如
PREFIX_TREE和DIFF)可以提高扫描性能。
6. 写前日志(WAL)
- 施行
hbase.regionserver.wal.enable参数确定是否启用写前日志(WAL),它关键于数据的持久化和恢复。
7. Split 和 Compaction 策略
- 定制分裂和合并的策略
hbase.hregion.majorcompaction和hbase.hregion.min.compaction.size,以控制如何整理 HFile 文件,并减少碎片。
8. 客户端配置
- 在客户端配置缓冲区
hbase.client.write.buffer大小对写入吞吐量进行优化。 - 通过
hbase.client.scanner.caching设置客户端扫描的批次大小,以减少扫描操作的网络交互。
9. I/O优化
- 如果使用 Hadoop,尝试适当调节 HDFS 参数来优化底层文件系统,比如
dfs.replication来设置合适的副本因子。
10. JVM 参数
- 对 HBase 服务(Master 和 RegionServer)调优 JVM 参数,如堆内存设置
-Xms和-Xmx,和垃圾收集器的配置,以优化 RegionServer 的性能。
11. 监控和日志
- 启用监控和日志记录,以获取集群性能的实时信息,并帮助识别问题。
警示
- 在做任何重大调整前进行集群备份;不同的环境可能需要不同的设置。
- 逐个参数调整,并监控每次更改的效果。
- 在非生产环境中测试配置更改以评估其对性能的影响。
这些是调优 HBase 集群参数的一般建议,但每个 HBase 集群都是独特的,请结合你的应用实际需求和集群运行特性进行细致调整。通过调试和性能评估,可以进一步调优特定配置。
5. HBase 数据管理
5.1 讨论 HBase 中的数据导入导出工具和方法
HBase 提供多种工具和方法来实现数据的导入和导出,以方便数据的备份和迁移,或实现与其他系统的数据交换。以下是一些常见的数据导入导出工具和方法:
HBase Shell
导出数据:
- 通过 HBase Shell 的
scan命令可以扫描和导出表数据。 - 使用重定向将
scan命令的输出存入文件。
导入数据:
- 可以写脚本来解析数据文件,并使用
put命令将数据导入到 HBase 表中。
HBase Import/Export
HBase 自带的 import 和 export 工具可以导出数据到 Hadoop 文件系统(HDFS)并从中导入数据。
# 导出数据
hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir>
# 导入数据
hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
Data Definition Language (DDL) Operations
- 可以通过 DDL 操作在 HBase 中创建表结构的定义,并根据这些定义将数据导入进来。
Bulk Load
- 利用 HBase 提供的
CompleteBulkLoad工具,可以快速地将大量数据批量导入 HBase 表中。 - 首先使用
HFileOutputFormat2对大数据集进行 MapReduce 处理,生成 HBase 需要的HFile格式数据。 - 然后通过
CompleteBulkLoad工具将这些数据加载到 HBase 表中。
Apache Sqoop
- Sqoop 是连接 Hadoop 和关系数据库的工具,支持将数据从关系数据库导入到 HBase 以及反向操作。
- Sqoop 使用
import命令可以将关系数据库表导入到 HBase 中,export命令可以将 HBase 表数据导回到 RDBMS。
Third-party Connectors
- 比如 Apache NiFi 或 Apache Camel 等工具,提供了一种方法来自动化数据的导入导出流程。
REST API
- HBase 提供了 REST API 可用来远程调用进行数据的增、删、改、查操作,从而实现数据导入导出。
每种方法都各自针对不同的使用场景和需求。在选择工具时,需要考虑数据的规模、导入导出的频率、以及目标来源和目标目的之间的兼容性等因素。Bulk Load 往往用于初始导入大量数据到新表中,而 Import/Export 工具则适用于定期的数据备份和恢复。而 Sqoop 则是在 HBase 与传统的 SQL 数据库间进行数据迁移的良好选择。
5.2 描述 HBase 表的分区和分区键的设计策略
HBase 是一个面向列的非关系型分布式数据库,它建立在 Hadoop 生态系统之上。HBase 表中的数据是按照行进行分区的,每个分区称为一个 Region。在 HBase 中,一行数据是由它的行键(Row Key)唯一确定的,因此行键在HBase的分区策略中扮演着核心角色。
分区策略
HBase中的表会水平划分成多个 Region。每个 Region 包含了一段连续的行。HBase 会自动按照 Row Key 的字典顺序来分区:
- 每个 Region 被分配给集群中的一个 RegionServer 节点。
- 当一个 Region 的大小到达一个阈值(默认为 10GB)时,该 Region 会被分裂(split)成两个新的 Regions。
分区键的设计
在设计 HBase 表的行键和选择分区键时遵循以下原则是很重要的,因为它们会影响数据的分布和查询性能:
-
均衡分布:
- 好的行键设计应确保数据在 RegionServer 之间均匀分布。
- 避免 “hotspotting”,即过多的读写操作集中在少数几个 Regions 上。
-
扫描优化:
- 尽量设计连续的键来优化表扫描的速度。
- 具有相似前缀的键将会存储在一起,可以加快顺序读取。
-
反转域名:
- 对于以网址作为键值的情况,可以使用反转的域名作为前缀进行行键设计,这样相关的网址更可能在同一 Region 中。
-
散列前缀:
- 可以在行键前添加一个散列值作为前缀以保证行数据的均匀分布。
-
避免使用时间戳作为前缀:
- 时间戳或自增ID作为行键的起始值会造成新数据不断堆积在表的末端,可能导致 Region 的无均匀分裂和热点。
-
使用盐值:
- 使用随机前缀(如盐值)可以使得键值更加均匀的分布在不同的 Region 中,但这可能会牺牲扫描操作的效率。
-
使用复合行键:
- 有时候可以考虑将多个字段组合起来作为复合行键,但需要确保键值的组合不会造成极不均匀的数据分布。
分区键设计的例子
假设我们有一张基于用户ID的表,表中包含了每次点击的记录。为了避免“热点”,可以在用户ID前加上一个散列值:
String userID = "user123";
int hashPrefix = (userID.hashCode() & Integer.MAX_VALUE) % 10;
String rowKey = hashPrefix + "_" + userID + "_" + System.currentTimeMillis();
这里,我们使用用户ID的散列值的后10位作为前缀,然后加上用户ID和当前时间戳来生成行键。这样可保证行键在 Region 中均匀分布,同时时间戳确保每个键都是唯一的。
设计分区键时还要考虑数据访问模式,确保行键设计能提高数据库的读写性能,而不仅仅只是为了均匀分布。
5.3 解释 HBase 中的压缩和编码技术
HBase 作为一个用于存储和管理大规模数据的分布式非关系型数据库,提供了多种压缩和编码技术,用于降低存储空间的使用量、加快数据的读写速度以及提高系统的整体性能。
压缩(Compression)
压缩技术在 HBase 中被用于减少存储数据所需的空间。数据在写入 HBase 时被压缩,并在读取时解压缩。下面是一些常见的压缩算法:
1. GZIP
- 一种广泛使用的压缩算法,提供很好的压缩率,但在压缩和解压时 CPU 消耗较大。
2. Snappy
- 由 Google 开发的压缩算法。提供合理的压缩率,与 GZIP 相比,它在解压缩速度方面特别快。
3. LZ4
- 同样以速度为优势的压缩算法,提供高速的压缩和解压性能。
4. BZIP2
- 提供更高的压缩率,但在性能上比 GZIP 要慢,适用于对磁盘空间敏感的场景。
压缩可以在创建或修改列族时进行设置,如:
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("myTable"));
HColumnDescriptor columnDescriptor = new HColumnDescriptor("myColumnFamily");
columnDescriptor.setCompressionType(Algorithm.SNAPPY);
tableDescriptor.addFamily(columnDescriptor);
编码(Data Block Encoding)
编码不仅可以减少存储用量,还可以优化读操作的性能。编码通常作用于数据块(Data Block)级别。以下是在 HBase 中常用的编码技术:
1. Prefix Tree Encoding
- 适用于 RowKey 有共同前缀的场景,它将前缀仅存储一次,并用更短的引用来替换后续相同的前缀。
2. Diff Encoding
- 仅存储相对于前一个键的差异,减少了存储冗余信息的需求。
3. Fast Diff Encoding
- 对 Diff Encoding 的优化版本,更适合读操作更频繁的使用场景。
编码通常适用于那些具有多个相同前缀或重复字段的数据。需要注意的是,开启编码可能会增加 CPU 的使用量,因为需要在读取数据时进行解码。
编码可以在列族定义时设置:
columnDescriptor.setDataBlockEncoding(DataBlockEncoding.PREFIX);
选择压缩和编码
压缩和编码的选择取决于多种因素,如具体的使用场景、性能需求和资源使用。在决策时需要权衡 CPU 和 IO 的使用:
- 对于读写操作较为平衡的场景,Snappy 或 LZ4 是不错的选择。
- 当磁盘空间是主要限制时,GZIP 或 BZIP2 可能更合适。
- 对于行键设计中具有共同前缀的应用场景,Prefix Tree 或其他编码技术可能提供更多优势。
在不同的应用场景和数据特征中,不同的压缩和编码策略将对 HBase 数据库的性能产生直接的影响。在真实使用中,应在样本数据集上测试不同的配置,以量化它们对读写性能的影响,并基于此来做出最佳选择。
6. HBase 高级特性
6.1 讲述 HBase 中的协处理器(Coprocessor)和其用途
HBase 协处理器(Coprocessor)是一种高级功能,它提供了在服务器端执行自定义代码的能力。类似于触发器(trigger)或存储过程(stored procedure)的概念,协处理器运行在 HBase RegionServer 进程中,可以拦截来自客户端的读写请求,并在数据被实际读或写入 HBase 表之前或之后执行自定义操作。协处理器通常用于自定义业务逻辑、数据聚合、复杂计算、观察者回调等。
类型
HBase 中有两类协处理器:
-
观察者(Observer):
- 观察者协处理器可以响应表级别和列族级别的事件,例如获取、放置(PUT)、删除和扫描操作。
- 这些协处理器类似于数据库的触发器,可以用于验证或转换数据、实施访问控制、维护二级索引等。
-
终结点(Endpoint):
- 终结点协处理器用于在表上实现自定义 RPC (远程过程调用)协议。
- 它可用于执行一些不能由标准 HBase API 提供的复杂操作或聚合功能,比如多行交叉行扫描的计算。
如何使用
要使用协处理器,你必须定义一个继承自 Observer 或 Coprocessor 接口的类,并实现其方法。然后,你需要将这个类部署到 HBase 服务器上,并在表描述符或者表的创建脚本中进行注册。
以观察者协处理器为例:
public class MyObserver extends BaseRegionObserver {
@Override
public void prePut(final ObserverContext<RegionCoprocessorEnvironment> e,
final Put put, final WALEdit edit, final Durability durability)
throws IOException {
// 自定义的前置处理逻辑
}
@Override
public void postPut(final ObserverContext<RegionCoprocessorEnvironment> e,
final Put put, final WALEdit edit, final Durability durability)
throws IOException {
// 自定义的后置处理逻辑
}
}
在 HBase 表中注册:
hbase> CREATE 'myTable', 'myFamily', CONFIGURATION =>
{'COPROCESSOR'=>'hdfs://path/to/MyObserver.jar|com.mycompany.MyObserver|1001|'}
用途
协处理器可以用于多种场景:
- 二级索引:创建和维护表的索引,从而加快特定查询的速度。
- 访问控制:在服务器端实现行级甚至单元格级的安全性策略。
- 复杂的数据处理和聚合:在服务器端完成计算,减少网络传输压力。
- 数据完整性:在数据被写入之前进行验证和完整性检查。
- 级联更新:某些操作触发更新关联数据。
- 实时事件响应:对数据变更做出响应并执行相应操作。
注意事项
虽然协处理器非常强大,但它们也带来了额外的复杂性和潜在的风险。错误编写的协处理器代码可能导致整个 RegionServer 崩溃,影响集群稳定性。因此,在生产环境中部署协处理器之前,应进行充分的测试并确保代码质量。
此外,协处理器运行于 RegionServer 中,具有与 RegionServer 相同的权限,因此需要谨慎处理协处理器的安全和权限问题,以避免潜在的安全风险。
6.2 描述 HBase 中的快照功能和数据备份选项
在 HBase 中,快照功能和数据备份选项是维护数据安全和灵活恢复的重要工具。
快照功能
快照是 HBase 表的一个只读反映,它能在不中断服务的情况下捕获表的特定状态。
-
创建快照:
通过snapshot命令创建一个快照。hbase> snapshot 'myTable', 'myTableSnapshot'-
myTable是要备份的表名。 -
myTableSnapshot是快照的名称。
-
-
列出快照:
使用list_snapshots可以列出所有快照。hbase> list_snapshots -
恢复快照:
通过restore_snapshot命令可以将表的状态恢复为快照所捕获的状态。hbase> restore_snapshot 'myTableSnapshot'*注意这将会替换掉当前的表数据,因此在执行该操作前务必谨慎考虑。
-
克隆快照:
使用clone_snapshot可克隆快照到一个新表。hbase> clone_snapshot 'myTableSnapshot', 'myNewTable' -
删除快照:
快照使用完毕后,可通过delete_snapshot删除以释放空间。hbase> delete_snapshot 'myTableSnapshot'
快照的创建和恢复操作在 HBase 集群中是低开销的,因为它们使用的是现有数据文件的硬链接,不需要复制整个表的数据。
数据备份选项
-
HBase 复制:
HBase 内置了数据复制功能,能将数据从一个集群实时复制到另一个集群。这通常用于跨数据中心的复制,并且可以用作灾难恢复。 -
DistCp:
可以使用 Hadoop 的DistCp(分布式复制)工具来备份hbase.rootdir中的所有文件到其他 HDFS 或者云存储系统。 -
Export 和 Import 工具:
HBase 提供了export和import工具,它们可以让你将表数据导出为 Hadoop SequenceFiles 格式,并导入到另一个 HBase 实例。导出表:
hbase org.apache.hadoop.hbase.mapreduce.Export myTable outputDir导入表:
hbase org.apache.hadoop.hbase.mapreduce.Import myTable outputDir
快照和数据备份都是 HBase 数据维护的关键部分。快照提供了一种快速、一致且低成本的表级备份方式,而数据备份则是集群级别的全面保护策略。适当地使用这些功能可以确保你的 HBase 数据即便在系统故障或数据损坏时也能得到及时恢复。在生产环境中,建议将快照和数据备份策略纳入到周期性维护计划中,并且在执行升级或重要变更前创建快照,以便应对可能发生的问题。
6.3 讨论 HBase 与其他系统的集成,如 Hive 和 Spark
HBase 是一个面向列的非关系型数据库,设计用于存储大规模的分布式数据集。尽管它最初是为了搜索引擎优化的需求设计的,但它已经发展成为一个支持广泛用例的灵活数据存储选择,特别是其中需要高吞吐量和低延迟访问的场景。由于其性能特性,HBase 常与其他数据处理系统如 Apache Hive 和 Apache Spark 集成,以实现被动的数据分析和处理。
HBase 与 Hive 集成
Apache Hive 是一个数据仓库工具,它可以让你使用类 SQL 的查询语言(HiveQL)来查询和分析存储在 Apache Hadoop 中的大型数据集。通过集成 HBase 和 Hive,你可以运行 Hive 分析操作直接在 HBase 存储的数据上。
集成步骤:
-
安装
hbase-handler包,这个包包含了需要集成 Hive 和 HBase 必要的 JAR 文件。 -
在 Hive 中创建一个外部表,并指向 HBase 表:
CREATE EXTERNAL TABLE hbase_table_ext(...) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = "...") TBLPROPERTIES("hbase.table.name" = "hbase_table_name"); -
使用 HiveQL 执行查询,这些查询会被转化为 HBase 操作来获取数据。
优点:
- 以人们熟悉的 SQL 方式来查询和分析 HBase 中的数据。
- 结合了 Hive 的强大分析能力和 HBase 的低延迟读/写特性。
HBase 与 Spark 集成
Apache Spark 是一个快速通用的分布式计算系统,它扩展了广泛使用的 MapReduce 计算模型,并提供了高效的数据处理和机器学习功能。
集成步骤:
-
使用 HBase 提供的 Spark 连接器,在 Spark 应用程序中读取和写入 HBase 表:
val hbaseRDD = sc.newAPIHadoopRDD(...) val hbaseDF = spark.read.options(...).format("org.apache.hadoop.hbase.spark").load() -
利用 Spark 的强大的数据转换和分析能力来处理 HBase 中的数据。
优点:
- 允许你通过 Spark 进行复杂的数据处理和分析,比如通过 SparkSQL、MLlib 或 GraphX。
- 可以利用 Spark 流(Spark Streaming)或 Spark Structured Streaming 处理实时数据,然后将结果存储到 HBase 中。
注意事项:
- 考虑到 HBase 和 Hive 或 Spark 集成时的性能优化,因为这些整合通常涉及网络通信和数据转换。
- 确保所有系统版本兼容,特别是在使用对应的连接器或 API(如 HBase 的 Spark 连接器)时。
- 在结合使用这些工具时,还要注意查询的优化,避免产生大量的小文件和过多的 HBase 扫描。
集成 HBase 与 Hive 和 Spark 允许开发者利用这些系统的特点来构建强大的实时或批量数据管道。这些集成增加了在存储和分析大规模数据集时的灵活性,使得构建复杂的、针对大数据应用程序的解决方案更加容易和强大。
7. HBase 性能优化
7.1 解释 HBase 中读写性能优化的方法
HBase 是建立在 Hadoop 分布式文件系统(HDFS)之上的列式数据库,专为处理大量数据而设计。由于其独特的存储结构和数据访问模式,优化 HBase 的读写性能需要考虑不同于传统数据库的因素。以下是几种提升 HBase 读写性能的方法:
读取性能优化
-
预分区(Pre-Splitting):
创建表时预先分区可以避免随着数据增长引发的热点问题。将表分散到不同的 RegionServer 上,有助于负载均衡和读取性能的提高。 -
数据本地性(Data Locality):
优化 HBase 和 HDFS 间的数据本地性,减少跨节点 I/O,以便 RegionServer 更快访问数据。 -
合理使用缓存:
合理利用 BlockCache(读缓存),确保热数据常驻内存中,减少读取时的磁盘 I/O 操作。 -
固定和小的列族数量:
减少列族数量,避免为每个列创建不必要的列族,因为每个列族都会有自己的存储文件和内存缓存。 -
滤镜和投影(Filter and Projection):
精确指定需要返回的列数据和使用过滤条件可以减少网络传输的数据量。 -
避免全表扫描:
除非必要,否则牢记避免使用全表扫描操作,它们会极大影响性能。
写入性能优化
-
批量操作(Batch Processing):
使用批量插入或更新操作可以减少网络开销,提升写入效率。 -
客户端的写缓冲区(Write Buffer):
应用端的写缓冲区可以批量发送请求到服务器,减小写操作的延迟。 -
WAL禁用:
对于不需要保证数据强一致性的场景,可以关闭 Write-Ahead Log(WAL)来加速写入操作。但需要明白这会影响数据的容错性。 -
使用合适的压缩算法:
对列族数据使用压缩,减少 I/O 和存储占用,同时注意压缩与性能之间可能存在的平衡。 -
避免热点(Hotspotting):
合理设计行键以避免数据不均匀分布导致的热点。 -
并发写控制:
调整并发写入线程数和 RegionServer 配置以平衡负载。
除了上述优化措施,还要定期进行数据的维护工作,如合并小文件、平衡 Region 分布、定期执行合并和压缩操作等。监控工具如 HBase 自带的 UI 界面、JMX 或第三方监控解决方案(例如 Prometheus)同样重要,可用来跟踪性能指标,并对集群状况做出快速反应。
7.2 描述 HBase 集群的资源管理和负载均衡
HBase 集群的资源管理和负载均衡涉及在 RegionServer 之间分配表的 Region 以优化性能。由 HBase 状态协调服务(主要是 HMaster 和 ZooKeeper)来管理这些任务。以下是集群资源管理和负载均衡的主要方面:
HBase Master - 资源管理
- HMaster 是 HBase 集群的主管理节点,负责监控所有 RegionServer 的状态,处理元数据变化,并执行系统级的操作,如创建或删除表。
- HMaster 提供了集群管理的接口和视图,包括进程监控、故障切换以及运行时配置更改。
ZooKeeper - 集群协调
- ZooKeeper 负责在 HBase 集群中处理各种协调任务,如管理集群状态、维护元数据信息、实现分布式锁等。
- ZooKeeper 是保持集群状态一致和服务发现的必要部分,每个 RegionServer 都会与 ZooKeeper 集群通信,注册其状态。
Region 分配
- HBase 会将每个表分割成多个 Region,每个 Region 包含表的一个子集。
- Region 被动态分配给集群中的 RegionServer,HMaster 负责初始化 Region 分配、处理 Region 服务器上下线等事件。
负载均衡
- 负载均衡器(Load Balancer)是 HBase Master 的一部分,它负责在多个 RegionServer 之间进行 Region 的分配,从而确保整个集群的负载均衡。
- 当 RegionServer 加入或离开集群时,或当 Region 数量改变导致负载不均时,负载均衡器会重新进行 Region 的分配。
负载均衡策略
- HBase 提供了多种内置负载均衡策略供选择,例如基于表的负载均衡、基于地域的负载均衡等。
- 开发者可以通过修改
hbase-site.xml配置文件中的相关属性来调整负载均衡策略。
读写请求分发
- 客户端请求会通过 HBase 客户端库被分发到相应的 RegionServer 进行处理,这得益于每个 Region 的定位信息是由 RegionServer 维护并且存储在 Meta 表中。
- RegionServer 之间的通讯同样由 ZooKeeper 协调。
性能监控工具
- HBase 配备了 HBase UI 和 监控 API 来监控集群的各个方面。
- 通过 HBase UI 和监控工具,如 Hadoop’s JMX-based Hadoop Metrics system、Ganglia 或 Prometheus,管理员可以观察和调整集群性能。
正常情况下,HBase 集群会自动处理 Region 分配和负载均衡。但是,在集群运行状况变化或规模扩展等情况下,管理员可能需要介入以确保资源分配的最优。管理HBase集群的资源和负载均衡是一项持续的任务,需要足够的监控和维护。
7.3 讲述 HBase 表和区域拆分、合并策略
HBase 是一个分布式的、可扩展的大数据存储系统,设计用于存储非常大的表,并且能够在 commodity hardware 上线性扩展。HBase 表的存储是通过区域(Region)实现的,而区域分裂(splitting)和合并(merging)是 HBase 中重要的策略,用于平衡集群负载、优化读写性能和管理数据的生命周期。
区域拆分(Region Splitting)
-
默认拆分行为:
- HBase 表自动发生拆分来应对数据增长。
- 当一个区域的大小超过配置的阈值(默认是 10 GB),HBase 会将其拆分成两个新区域。
- 拆分是基于行键的,保证数据的有序性,同时新区域会被均衡地分布到集群中的不同服务器上。
-
预拆分(Pre-Splitting):
- 管理员可以在创建表时预定义拆分方案,创建固定数量的区域。
- 通过预拆分可以减少后续动态拆分,有利于平衡初始写入负载。
-
拆分键:
- 拆分键是用于决定如何拆分区域的行键,它们需要谨慎选择以避免数据倾斜。
-
自定义拆分策略:
- HBase 允许定义自定义的拆分策略,例如根据特定业务逻辑分配行键。
区域合并(Region Merging)
-
过度拆分:
- 在某些情况下,区域可能因为拆分过度而变得太小,这会导致额外的管理开销和性能问题。
-
合并过程:
- HBase 允许合并两个相邻的区域来减少区域数量。
- 超出最小区域大小(默认是 1 GB)的区域将不会被自动合并。
-
手动合并:
- 管理员可以手动触发合并操作来解决区域过度碎片化的问题。
在实际使用 HBase 时,表的拆分和合并策略都需要仔细管理来确保性能和可扩展性。以下是一些建议:
- 预拆分表:在表创建时进行预拆分,特别是对于初始数据加载很大的场景。
- 监控区域大小:定期检查区域大小和分布,确保它们在整个集群中平衡。
- 避免热点问题:恰当设计行键的分布,避免大量写操作集中在某个小区域。
- 自动化维护:设置自动化的脚本或使用 HBase 提供的工具进行区域的维护。
- 考虑行键设计:行键的设计决定了数据如何分布到区域,直接影响到性能和拆分效果。
区域拆分和合并是 HBase 集群管理的核心部分,应该结合具体的业务需求、数据模式和性能目标来设计相应的策略。通过有效的管理,HBase 可以提供稳健的服务,以处理规模较大的数据。
8. HBase 监控和维护
8.1 讨论 HBase 集群监控的工具和指标
监控 HBase 集群对于确保其高性能和稳定性至关重要。HBase 提供了一组工具和指标供系统管理员监控集群运行状况。以下是一些常用的 HBase 集群监控工具和指标:
监控工具
-
HBase Master Web UI:
- HBase Master 提供了一个 Web 界面,通常位于
http://<master-host>:16010/。它显示了集群的运行状态、表的列表和状态、RegionServer 列表等信息。
- HBase Master 提供了一个 Web 界面,通常位于
-
RegionServer Web UI:
- 每个 RegionServer 也有自己的 Web 页面,通常可访问于
http://<regionserver-host>:16030/。它提供了该服务器上区域(Regions)的相关信息和指标。
- 每个 RegionServer 也有自己的 Web 页面,通常可访问于
-
JMX & JConsole:
- HBase 使用 Java 的 JMX 技术来暴露监控指标。可以使用 JConsole 或其他 JMX 兼容工具来连接到 HBase JMX 端口(默认 10101)并监控性能。
-
Grafana + Prometheus:
- 配置 HBase 以将指标导出到 Prometheus,再通过 Grafana 进行可视化和告警管理。
-
Apache Ambari / Cloudera Manager:
- 这些管理平台为 HBase 提供了综合的监控、管理和自动化工具。它们具有用户友好的界面和各种监控功能。
-
Ganglia / Nagios:
- 这些传统的监控系统可以集成到 HBase,提供指标的采集和警告功能。
监控指标
-
请求速率:
- Total Request Count:所有 RPC 请求的总数,包括读写操作。
- Read Request Count:读请求的总数。
- Write Request Count:写请求的总数。
-
延迟:
- 平均读、写延迟:每次读写操作的平均耗时。
-
RegionServer 指标:
- Region Count:各 RegionServer 上托管的区域数量。
- StoreFile Size:存储文件的总大小,反映了数据的存储占用。
-
缓存指标:
- BlockCache Size:块缓存的大小,该缓存可以加速数据读取。
- BlockCache Hit Rate:块缓存命中率,高命中率意味着大多数读取操作无需访问磁盘。
-
内存使用:
- MemStore Size:MemStore 上未刷新到磁盘的数据大小。
-
压缩和压缩比:
- 压缩是提高存储空间利用率和读写性能的重要功能。
-
Garbage Collection(GC)指标:
- GC 时间和频率:较长或频繁的 GC 可能暗示潜在的性能问题。
-
Region 服务器状态:
- 活跃和不活跃的 RegionServer 的数量。
-
复制指标:
- HBase 复制延迟和运行状况。
-
WAL (Write-Ahead Log) 指标:
- Fsync 延迟:日志同步到磁盘的时间。
监控最佳实践
- 定期检查:定期手工检查集群的 Web UI 以了解集群的状态。
- 自动监控:使用自动化监测工具获取实时的集群指标,并设置警报以响应异常情况。
- 日志分析:分析和监控 HBase 日志可以揭示错误和异常,日志收集和聚合工具(如 ELK Stack)会非常有帮助。
- 集群规模:监控数据应根据集群规模调整。对于大型集群,应该设置更精细的监控和长期的数据保留策略。
- 分析瓶颈:分析性能指标以发现瓶颈,进行必要的调优以确保性能达到最佳。
监控 HBase 集群不仅仅是关注它是否运行,同样也要了解它的表现如何,是否需要扩展,以及何时需要优化配置。通过监控工具和指标,可以提高集群的健壮
8.2 描述 HBase 的故障诊断和日志分析方法
在 HBase 中,及时诊断故障和正确分析日志至关重要,可以帮助快速定位问题并找到解决方法。以下是故障诊断和日志分析的一些基本方法:
基本故障诊断
-
检查服务状态:
- 首先,确保所有 HBase 相关服务正在运行。在 HBase 中,包括 HMaster、RegionServers 以及依赖的服务,例如 ZooKeeper 和 HDFS (NameNode 和 DataNode)。
-
使用 HBase Shell:
- HBase Shell 是查看集群状态和进行基本管理的工具。通过
status命令可以获取集群的健康状况和负载信息。
- HBase Shell 是查看集群状态和进行基本管理的工具。通过
-
HBase Web UI:
- HBase 提供了 Web 用户界面用于监视集群状态。通常 Master UI 可以从 http://:16010 访问,它提供了很多有用的信息。
-
检查 Region 分配:
- 确认所有 Region 都已正确分配给了 RegionServers。在 HBase Shell 中使用
list_regions查看分配信息。
- 确认所有 Region 都已正确分配给了 RegionServers。在 HBase Shell 中使用
日志分析方法
-
查看 Master 和 RegionServer 日志:
- Master 和 RegionServers 的日志中记录了重要的信息, 包括错误、异常和其他诊断信息。日志文件位于
$HBASE_HOME/logs目录。
- Master 和 RegionServers 的日志中记录了重要的信息, 包括错误、异常和其他诊断信息。日志文件位于
-
通过关键字搜索:
- 在日志文件中搜索错误 (
ERROR) 或异常 (Exception) 关键字,这是快速定位问题的一个好方法。
- 在日志文件中搜索错误 (
-
分析堆栈跟踪:
- 如果遇到异常,请仔细阅读堆栈跟踪信息,以了解问题的根源。
-
使用日志级别控制:
- 如果需要更多信息,可以临时提高日志级别。可以在
log4j.properties文件中调整日志级别到DEBUG或TRACE。
- 如果需要更多信息,可以临时提高日志级别。可以在
-
诊断工具:
- 利用 HBase 的一些内置诊断命令,如
hbck,可以帮助检查和修复一些不一致的状态。
- 利用 HBase 的一些内置诊断命令,如
-
分析 GC 日志:
- GC (垃圾收集) 日志可以揭示 JVM 的内存回收情况,耗时的 GC 过程可能会导致 RegionServer 响应缓慢。
-
分析网络和 I/O:
- 利用系统工具如
top、iostat、netstat等,来确认 CPU、内存、磁盘 I/O 或网络不是性能瓶颈。
- 利用系统工具如
-
设置日志滚动和归档:
- 确保启用了日志滚动和归档机制,以便重要日志文件不会因为文件过大而被尝试读取或写入时造成性能问题。
-
查阅官方文档和社区支持:
- 对于不确定的错误或异常,查阅 HBase 官方文档或在 Stack Overflow、邮件列表、社区论坛寻求帮助。
综合诊断
解决问题通常需要对整个 HBase 以及底层 Hadoop 生态系统进行综合诊断。围绕问题症状展开调查,并结合日志文件、监控指标和资源使用情况来诊断故障。
在生产环境中,强烈建议设置持续的监控和告警系统(例如使用 Apache Ambari 或 Cloudera Manager),以便在出现问题时及时发现并针对性地进行日志分析和故障诊断。
8.3 解释 HBase 的版本升级和数据迁移过程
HBase 的版本升级和数据迁移是指将运行中的 HBase 集群升级到新版本,并在必要时迁移数据以适配新版本。这个过程需要谨慎规划和执行,以确保数据的一致性和可用性。以下是 HBase 版本升级和数据迁移的一般步骤和注意事项:
版本升级前的准备工作
- 阅读发行说明:了解新版本的功能、改进、修复,以及任何不兼容的更改。
-
备份数据:在进行任何升级操作前,对当前 HBase 集群的数据进行备份,通常可以使用
hbase snapshot命令。 - 审查依赖:确认所有依赖的系统(如 Hive、Spark 等)都与新版本兼容。
- 停止数据写入:在升级过程中,暂停所有数据写入操作,确保数据状态不变。
- 检查配置文件:审核和合并配置文件的更改,特别是任何被标记为弃用的配置项。
执行版本升级
- 按照文档操作:遵循官方升级指南的步骤,逐个升级 HBase 集群中的所有节点。
- 停止集群:先停止所有 RegionServer,再停止 HMaster 服务。
- 升级软件:下载新版本的 HBase,并替换旧版本的服务程序。
-
更新配置:根据新版本的要求更新
hbase-site.xml和其他配置文件。 - 启动集群:首先启动 HMaster,确认服务正常后,再启动所有的 RegionServer。
数据迁移
- 监控数据迁移过程:在 HBase 升级时,可能需要执行数据格式的迁移工作。监控日志以确保数据迁移正确无误。
- 执行数据升级脚本:有时,升级过程中需要运行特定的脚本或工具来更新和迁移数据格式。
验证升级
- 测试功能和性能:在升级后测试集群的功能和性能,确保新版本运行正常并且性能达标。
- 确保数据完整:用已备份的数据对照验证数据完整性,确保数据没有丢失或损坏。
- 监控集群状态:通过例如 Web UI 的集群监控工具检查集群是否正常运行。
版本降级(如有必要)
在遇到不可解决的问题时,可能需要回滚到旧版本。在执行降级前,也应该确保有数据的备份,并按照官方文档提示的步骤来执行。
注意事项
- 如可能,先在一个小型或隔离的环境中测试升级过程,以便了解会遇到的问题。
- 在升级过程中维护良好的通讯和文档记录。
- 了解新版本中新增的优化参数和调整集群配置,以充分利用新功能。
- 考虑到有时版本升级可能导致数据格式的变化,确保了解影响并有相应的迁移策略。
在整个升级和数据迁移过程中保持细心和耐心非常重要。尽管 HBase 设计了平滑升级的能力,升级之前认真规划和准备,仍然是成功升级的关键点。
9. HBase 安全性
9.1 讲述 HBase 的安全性特性,包括 Kerberos 认证和授权机制
HBase 作为一个集群式存储系统,其安全性特性是确保数据安全和满足合规性需求的重要组成部分。以下是 HBase 安全性的几个关键方面:
Kerberos 认证
在 HBase 中,Kerberos 是实现客户端和服务器之间安全认证的标准方式。Kerberos 是一个基于票据的认证协议,可以确保数据在不安全网络中传输的安全性。
- 当配置了 Kerberos 后,HBase 会对所有通过网络传输的数据进行加密,包括客户端和 HBase、HBase 和 Hadoop 文件系统(HDFS)之间的数据。
- 用户和服务需要通过 Kerberos KDC(密钥分发中心)获取有效的票据才能访问 HBase。
使用 Kerberos 认证可以防止窃听和重放攻击,并确保认证过程中的数据不会被篡改。
授权机制
HBase 提供细粒度的访问控制,允许管理员定义哪些用户或组有权限执行指定操作。这些安全控制详细到表、列族甚至列和单元格级别。
- Access Control Lists (ACLs):通过设定 ACLs,可以控制用户对表的读写权限,或对特定数据的访问。
- Cell-level security: HBase 还支持单元格级别的安全控制。用户可以对个别单元格设置不同的权限,从而实现非常精细化的访问控制。
集成安全解决方案
HBase 可以集成 Apache Knox 和 Apache Ranger 等安全门户和管理工具,提供更综合的安全策略和审计功能。
- Apache Knox:提供了一个统一的安全网关,可以使用户通过 Knox 访问 HBase,从而集中管理安全策略。
- Apache Ranger:提供了一个综合的安全管理界面,可以在更细粒度上定义策略、审计访问日志以及监控数据访问行为。
安全模式
HBase 运行时可以配置为安全模式,它会强制要求所有的访问必须通过认证和授权。
在安全模式下,HBase 的 RPC 端口和 Web 端口都会被保护。此外,当 HBase 与 HDFS 集成时,HBase 和 HDFS 间的通信也需通过 Kerberos 进行加密认证。
传输层安全(TLS)
为了确保客户端和服务端的数据传输安全,HBase 支持配置 TLS/SSL 加密。这意味着即使数据传输通过公共网络,信息也是加密的,防止数据在传输过程中被拦截。
配置和管理 HBase 的安全性,确保了企业能够保护重要的数据资产并符合安全合规要求。实践中,应结合 Kerberos 认证、授权机制、传输层安全和其他集成工具来构建综合的安全策略。
9.2 描述 HBase 与 Apache Ranger 和 Apache Sentry 的集成
Apache HBase 集成 Apache Ranger 或 Apache Sentry 的主要目的是为了提供细粒度的访问控制,以增加数据安全性。Ranger 和 Sentry 都是为 Hadoop 生态系统设计的安全管理工具,它们提供策略管理、权限保护和审计功能。
HBase 与 Apache Ranger 集成
主要特性
- 细粒度的访问控制:能够为 HBase 表、列和列族定义访问策略。
- UI 管理界面:Ranger 提供了一个 Web 界面,允许管理员配置和管理安全策略,无需直接操作 HBase ACL。
- 审计日志:Ranger 可以保留用户对 HBase 的访问尝试的详细审计日志,包括访问的时间、操作类型、访问的资源等。
配置过程
- 安装 Ranger 并启动 Ranger 管理服务。
- 在 Ranger UI 中添加 HBase 服务,配置相关的库和仓库细节。
- 设置资源访问策略,指定用户或组、资源路径以及允许的操作。
- 在 HBase 配置中启用 Ranger 插件,通常在
hbase-site.xml文件中添加 Ranger 相关的配置。
HBase 与 Apache Sentry 集成
主要特性
- 角色基的访问控制(RBAC):Sentry 支持基于角色的访问控制,这意味着你可以为用户分配适当的角色,进而控制他们对 HBase 数据的访问。
- 精确到列级别的权限管理:为表的列设定不同级别的权限,比如只读、读写等。
配置过程
- 安装 Sentry 并在 HBase 集群中配置 Sentry 服务。
- 确定运行你的 RegionServer 进程的用户有正确的文件访问权限。
- 在 HBase 配置文件(
hbase-site.xml)中设置 Sentry 相关参数。 - 创建并管理 Sentry 策略文件,定义哪些角色和用户可以访问特定的资源。
- 确保远程过程调用(RPC)在 HBase 与 Sentry 之间进行授权。
- 启用 HBase 的 Sentry 插件,并重新启动 HBase 服务。
系统间兼容性
- 为了确保与 Ranger 或 Sentry 的集成高效工作,重要的是保证你使用的 HBase 版本与安全工具兼容。
- 你可能还需要安装其他 Hadoop 生态系统组件,如 Apache Hadoop 和 Apache Hive,以便 Ranger 或 Sentry 能够全面地进行安全管理。
集成 Ranger 或 Sentry 到 HBase 集群中可以提供强大的安全管理能力,降低不当的数据访问风险。通过集成,企业可以确保满足合规性要求,并在整个集群范围内执行统一的权限管理。
9.3 讨论 HBase 运行在安全模式下的配置和注意事项
HBase 像其他在 Hadoop 生态系统中的组件一样,可以配置为在安全模式下运行,增强其对数据和通信的保护。在安全模式下,HBase 通常结合 Kerberos 鉴权机制来确保对集群的访问是经过身份验证和授权的。下面是在安全模式下配置和运行 HBase 时的一些关键点和注意事项:
配置Kerberos鉴权
-
启用Kerberos:
- 配置 Hadoop 集群以使用 Kerberos 进行鉴权,这通常包括设置 Hadoop 的
core-site.xml和hdfs-site.xml文件。
- 配置 Hadoop 集群以使用 Kerberos 进行鉴权,这通常包括设置 Hadoop 的
-
HBase Kerberos配置:
- 为 HBase 配置 Kerberos 鉴权,需要在
hbase-site.xml中设置 Kerberos 相关的属性。
- 为 HBase 配置 Kerberos 鉴权,需要在
-
服务与用户原则(Principals):
- 为 HBase 主服务以及其他运行各种 HBase 组件的用户定义和配置 Kerberos 原则。
-
生成密钥表文件(Keytabs):
- 为 HBase 主服务和 HBase 用户创建密钥表(keytab)文件,并确保它们在所需的节点上可用。
安全Hadoop RPC通信
-
配置 SASL:
- 通过修改 HBase 配置,确保 HBase 的 RPC 通信是通过 SASL 和 Kerberos 来保护的。
安全ZooKeeper访问
-
ZooKeeper安全:
- 如果 ZooKeeper 用于 HBase,也需要对其进行安全配置。确保只有授权用户能够访问和修改 ZooKeeper 数据。
授权和访问控制列表(ACL)
-
HBase的访问控制列表(ACL):
- 利用 HBase 内置的访问控制能力,可以对表、列簇和单元格级别的数据进行精细控制。
- 这需要配置
hbase.coprocessor.master.classes和hbase.coprocessor.region.classes属性,并启用 AccessController。
数据加密
-
数据在传输中加密:
- 为了保证数据在网络中传输的安全性,配置 HBase 和 Hadoop 使用加密的数据传输通道。
- 需要在
hdfs-site.xml中配置数据加密的相关属性。
注意事项
-
性能影响:
- Kerberos 和加密可能会对性能产生影响,所以在开启安全特性时,要监控性能并根据需要调优。
-
维护和管理:
- 维护周期性更新的密钥表,保证系统的安全性。
-
兼容性问题:
- 确保集群中的其他服务也配置为兼容安全模式,以避免互操作性问题。
-
测试和验证:
- 在实践安全配置之前,先在一个隔离的测试环境中测试安全设置,以确保它们按预期工作。
-
监控和日志审计:
- 配置适当的监控和日志记录策略,为安全事件和异常提供可见性。
保持 HBase 运行在安全模式下需要详尽的计划和持续的管理,这旨在确保数据不受未经授权的访问和攻击。随着安全性所属的重要性,投入必要的资源来配置和维护 HBase 安全特性是非常关键的。
10. HBase 最佳实践和案例研究
10.1 分析 HBase 在不同行业中的应用案例
HBase 作为一个高性能的 NoSQL 数据库,得益于其低延迟和高吞吐量的特点,被广泛应用于需要处理大量数据的行业和场景中。以下是一些不同行业中 HBase 应用的案例:
互联网和社交媒体
HBase 在互联网和社交媒体领域常用于存储用户生成的大量数据和社交关系网络。例如,Facebook 使用 HBase 来支撑其消息平台,因为它可以快速地处理和访问数据。Twitter 使用 HBase 作为其用户数据和推文的存储解决方案。
金融服务
在金融服务行业,HBase 可用于交易数据分析、风险评估、欺诈检测和实时报价。它可以处理高速数据流,并用于存储巨大的历史交易记录,支持快速的数据查询和分析。
电信
电信运营商使用 HBase 储存和分析通话记录(CDRs)、用户行为和网络流量数据。这些数据可以用来进行入侵检测、用户画像、网络优化和个性化服务推荐。
物联网(IoT)
在物联网领域,HBase 通常用来收集和分析来自传感器的大量时序数据。例如,在智能电网中,可以使用 HBase 存储和分析电力使用数据,以优化能源分配和电网运行。
生物科技和医疗保健
HBase 被应用于基因组学和生物信息学,为科研提供快速的基因序列分析和大规模数据集存储。此外,在医疗保健领域,它可以用来管理病人记录、医疗影像存储以及实时监测数据。
电子商务
电子商务平台使用 HBase 来存储商品信息、用户行为和订单数据。由于其快速读写能力,HBase 适合用于购物车数据处理、个性化推荐和实时库存管理。
搜索引擎
搜索引擎使用 HBase 来存储网页内容和用户查询日志。它支持高速的键值操作,适用于索引维护和搜索结果的快速检索。
在线游戏
在线游戏平台使用 HBase 存储玩家信息、游戏状态和事件日志。游戏服务器可以实现对玩家动作的快速响应,并支持海量玩家数据的存储和分析。
大数据分析
多个行业的数据平台集成了 HBase 作为其大数据分析的存储组件,以支持对大数据进行整合和快速访问,支撑数据挖掘和机器学习任务。
在所有这些案例中,应用 HBase 的主要原因是其高度可伸缩性、出色的性能以及对于非结构化或半结构化数据存储和查询的支持。在处理海量、增长迅速的数据集和实时数据分析要求中,HBase 表现出了其重要价值。选用 HBase 还需要考虑因素包括应用需求、资源和技术栈兼容性、以及维护和管理的成本。
10.2 讲述 HBase 部署的设计模式和最佳实践
在部署 HBase 集群时,一个好的设计模式和遵循最佳实践可以确保集群的稳定性、性能和可扩展性。下面是 HBase 部署的一些关键设计模式和最佳实践:
硬件选择
-
内存优先:
- HBase 是内存密集型的,优先考虑具有大内存的服务器。
- 增加 RegionServer 的内存可以提高缓存命中率,从而提高读取性能。
-
强大的 I/O 性能:
- 选择高速磁盘(例如 SSD)以支持快速的写操作和日志同步。
- 使用 RAID 或其他磁盘冗余技术提高数据的持久性和恢复力。
-
网络带宽:
- 良好的网络带宽是保证 HBase 集群成员间同步和通信的关键。
软件配置
-
JVM 配置:
- 合理配置 Java 虚拟机选项,如适当的堆大小、垃圾回收策略等。
- 使用 jmap、jstat、jstack 等工具监控 JVM 性能。
-
HBase 配置文件:
- 优化
hbase-site.xml配置参数,例如 RegionServer 的最大堆大小和适当的内存分配。 - 设置合适的
hfile.block.cache.size和hbase.regionserver.handler.count等参数。
- 优化
-
操作系统配置:
- 调整操作系统层面的参数,比如 max open files 和 swappiness。
- 考虑禁用透明的大页(THP),因为它们可能会导致性能问题。
架构设计
-
Region 布局:
- 合理设计表的 rowkey 以避免 read/write hotspots。
- 使用预分裂 Regions 来更均匀地分配数据和负载。
-
高可用性:
- 部署多个 HMaster 以提供故障切换。
- 在 HDFS 级别实现数据冗余备份。
-
合理的复制策略:
- 使用 HBase 复制功能同步数据到备份集群,特别是在多数据中心部署时。
性能调优
-
MemStore 和 BlockCache:
- 合理配置 MemStore 大小和 BlockCache 大小以优化读写性能。
-
压缩和 Bloom Filters:
- 在适当的列族使用压缩节省空间并减少 I/O。
- 在列族上启用 Bloom Filter 可以优化读取性能。
监控和维护
-
集群监控:
- 使用集群监控工具(如 Apache Ambari、Ganglia、Cloudera Manager)来实时监控集群的健康、性能指标和运行状况。
-
定期维护:
- 定期执行 HBase 的 housekeeping 任务,例如合并小文件和清理 HFiles。
- 定期验证和优化 HBase schema 和 configurations。
安全性
-
安全认证和授权:
- 根据需要配置 Kerberos 或其他安全机制。
- 使用 HBase 提供的 ACL 机制控制对数据的访问。
数据备份与恢复
-
快照和备份:
- 使用 HBase 的快照功能进行数据备份。
- 定期备份 HBase 元数据和 HDFS 数据。
将这些最佳实践应用到你的 HBase 部署过程中,可以帮助创建一个高效、可靠、可伸缩和安全的大数据平台。这些原则和实践可以根据具体的业务需求和操作环境进行相应的调整。安排好周期性的审查和更新可以确保不断优化的运行效率和最新的安全标准。
10.3 描述 HBase 社区的最新发展和趋势
截至我知识更新的时间点(2023年),HBase 社区一直在活跃地发展,并且有着许多新的发展和趋势在推动其进步。以下是 HBase 社区的一些最新发展和趋势:
1. 更紧密的云集成
随着云计算的普及,HBase 社区正在增强与云平台的集成,如 Amazon EMR、Google Cloud Bigtable(一种兼容 HBase API 的服务)、Microsoft Azure HDInsight 和阿里云等。这些云服务正在提供更多用于管理和托管 HBase 集群的工具和服务。
2. 容器化与 Kubernetes
容器化是当前软件开发的一个重要趋势。HBase 也在向容器化方向发展,以利用 Kubernetes 进行集群调度和管理。社区正在工作,以确保 HBase 可以在 Kubernetes 环境中顺利运行。
3. Java 11 支持
随着 Java 9 到 11 的新版本推出,社区正在努力使 HBase 兼容这些最新的 Java 版本,这可能涉及解决 JVM 内部的更改和性能优化。
4. 锁定和并发改进
在并发控制方面,社区正在持续改进 HBase 的多版本并发控制(MVCC)机制和锁定策略,以提升性能和数据操作的一致性。
5. 性能优化
HBase 社区不断寻求新方法来提高数据库的性能,包括读取路径、写入路径和压缩算法的优化。
6. 耐用性和稳定性
为确保面对硬件故障和网络分区等问题时仍然可以可靠地运行,社区持续在提高数据耐用性和集群的稳定性方面投入努力。
7. 大数据和流处理集成
流行的大数据处理工具,如 Apache Spark 和 Apache Flink,与 HBase 的集成不断加深,使得 HBase 可以作为强大的后台服务支持复杂的流数据处理。
8. 查找和索引功能
HBase 社区关注如何提供更高效的数据检索能力,比如通过集成开源搜索平台如 Apache Solr 或 Elasticsearch。
9. 事务支持
尽管 HBase 作为非关系型数据库并未提供完整的事务支持,但社区正在寻求增强其有限的事务能力的方法。
10. 社区增长
随着 HBase 成为越来越多公司基础架构的一部分,社区正变得更加国际化,同时持续吸引新的开发者和贡献者。文章来源:https://www.toymoban.com/news/detail-857019.html
由于大数据和实时处理仍然是业界的热点,也是驱动社区演进的主要因素,因此社区紧跟这些趋势,以确保 HBase 能够满足新兴的工作负载和性能要求。社区的活跃度和开放性直接关系到 HBase 能否持续发展、保持创新,并适应不断变化的技术环境。文章来源地址https://www.toymoban.com/news/detail-857019.html
到了这里,关于Hbase面试题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!