目录
前言:
堆排序(以排升序为例)
步骤(用大根堆,倒这排,排升序):
1.先把要排列的数组建立成大根堆
2.堆顶元素(82)和最后一个元素交换(2)
3.无视掉交换后的元素(82),对(2)进行向下调整
翻译成代码
mian方法:
heapSortUp方法:
siftDown方法:
堆排序时间复杂度分析:
前言:
本文章以升序为例进行讲解(实际上两种排列时间复杂度都一样,只是比较方式和建立大小堆恰好相反)
文章涉及:
1.向下调整算法
2.建堆的方式及其时间复杂度
3.堆排序步骤和时间复杂度分析
注意:如果1,2点还不了解,建议学习完之后在来学习堆排序,才能明白下边讲的是什么。
这里有小编自己写的链接,详细介绍了堆的创建以及向下/向上调整算法:优先级队列(堆)
堆排序(以排升序为例)
如果是排升序,要建立大根堆,反之亦然。
排降序,建立小堆
为什么?
看完他的原理,就知道了。
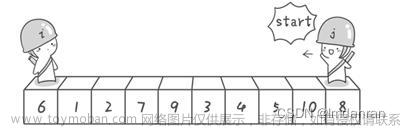
以数组array={
4,6, 82, 7, 8, 9, 3, 2
}
为例
步骤(用大根堆,倒这排,排升序):
1.先把要排列的数组建立成大根堆

2.堆顶元素(82)和最后一个元素交换(2)

3.无视掉交换后的元素(82),对(2)进行向下调整
此时又变成了大根堆(无视已经排好的82):

此时的82已经被排号了
其是堆排序的整体思路已经讲完了,接下来就是循环执行2,3点
3和9换位置,然后无视排好的82,9,对3进行向下调整:

在向下调整完之后,又是一个大根堆,我们继续,循环这个逻辑,最终的结果就变成了:

这时,就是一个升序的数组了。
翻译成代码
mian方法:
public class Test {
public static void main(String[] args) {
int[] arr = new int[]{4,6, 82, 7, 8, 9, 3, 2};//要排的数组
BigHeap bigHeap = new BigHeap();//这个是我自己写的大根堆
bigHeap.init(arr);//把数组传入对象
bigHeap.creatHeap();//先建立起大堆
bigHeap.heapSortUp();//进行堆排序
}
}heapSortUp方法:
1.我的堆,底层使用elem的数组实现的!!!!!
2.useSize是堆的容量
3.swap的两个参数都是数组的下标
public int[] heapSortUp() {
int endIndex = useSize - 1;//最后一个下标的位置(也就是容量减1)
while (endIndex > 0) {//如果等于零,就不用交换了
swap(0, endIndex);//顶元素和最后一个元素交换
endIndex--;//最后一个下标--,就可以起到无视排号数,的作用
siftDown(0, endIndex);
}
return elem;
}siftDown方法:
public void siftDown(int parent, int end) {//parent end都是有效下标
int child = 2 * parent + 1;//默认是左孩子
while (child <= end) {//调整到最后一个子节点,为止
//先判断是否有右孩子
if (child + 1 <= end) {//如果有判断谁大,大的当左孩子
if (elem[child] < elem[child + 1]) {
child++;
}
}
//左孩子在和父节点进行比较
if (elem[child] > elem[parent]) {//如果孩子节点大,那么父子交换位置
swap(child, parent);
} else {
break;//如果父节点已经是最大的就不用调整了,这棵树就是大根堆
//因为我们会从后往前,把这棵树(数组)一次遍历调整完
}
//下面继续往往下面调整
parent = child;//当前的父亲,变成自己的孩子
child = parent * 2 + 1;//孩子变成孩子的孩子
}
}堆排序时间复杂度分析:
其实很简单,上面我们一共说了三个方法:
1.main
2.heapSortUp
3.siftDown
我们从main方法切入,实际上执行堆排序的程序就是这两步:
public static void main(String[] args) {
int[] arr = new int[]{4,6, 82, 7, 8, 9, 3, 2};
BigHeap bigHeap = new BigHeap();
bigHeap.init(arr);
//这两步:
bigHeap.creatHeap();//先创建大根堆
bigHeap.heapSortUp();//堆排序,内部实现等一下看
}学了堆我们都直到,建堆的时间复杂度是O(N)
然后在加上heapSortUp的时间复杂度,不就是堆排序的时间复杂度了吗?
具体看一下,heapSortUp:
public int[] heapSortUp() {
int endIndex = useSize - 1;
while (endIndex > 0) {
swap(0, endIndex);
endIndex--;
siftDown(0, endIndex);
}
return elem;
}useSize和siftDown是我们要计算的时间复杂度,其他都是常量不用管
useSize实际上就是所给数组的长度嘛,就是N咯,
学了siftDown就是向下调整算法,向下调整算法和向上调整算法的时间复杂度都是logN(以2为底)-----》至于怎么算的,可以看小编文章前言部分的链接
所以堆排序的时间复杂度==O(useSize)+O(siftDown)*O(creatHeap)=N+N*logN文章来源:https://www.toymoban.com/news/detail-857270.html
然后取得最高阶,则时间复杂度就是O(N*logN)文章来源地址https://www.toymoban.com/news/detail-857270.html
到了这里,关于为什么堆排序的时间复杂度是O(N*logN)?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!