本次本人用到的软件汇总:百度网盘下载
1.下载:
https://github.com/ollama/ollama/releases
2.配置环境变量
我的电脑-右键-属性-系统-高级系统设置-环境变量-【系统环境变量】新建
变量名:OLLAMA_MODELS (固定变量名)
变量值:E:\Ollama\Lib (写自己要存放的路径)
先配置好这个变量,这个是ollama的存储路径。
不配置也可以,不配置的话就会放到默认位置,建议还是修改下存储路径,方便后续使用。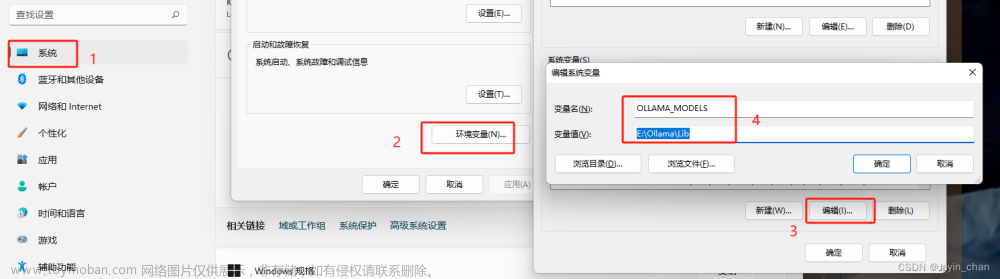
3.安装
直接install即可。
安装完成后,cmd查询下:ollama --version
如果查询不到,重启下电脑即可。
我这里是因为我直接把ollama给关了,所以出现了警告,不过也同样可以看到ollama客户端的版本。
ollama的其他命令可以通过ollama help来获取
4.下载并运行模型
-
谷歌最新开源gemma:
- 最低条件:
2B版本需要2G显存
7B版本需要4G显存
7B的其他版本需要更大
- 最低条件:
-
打开命令提示符窗口下载运行模型:
-
访问:https://ollama.com/library选择自己想要的模型,复制下载命令即可.
-
这里选择拉取gemma7b版本来试试:
ollama run gemma:7b -
全量版模型拉取运行命令
ollama run gemma:2b-instruct-fp16ollama run gemma:7b-instruct-fp16
-
-
ollama命令:
- 查看已有模型:
ollama list
- 查看已有模型:
-
下载完成后即在运行(只下载的话,就用
ollama pull去拉取即可)
-
接下来可以直接在命令行窗口进行问答
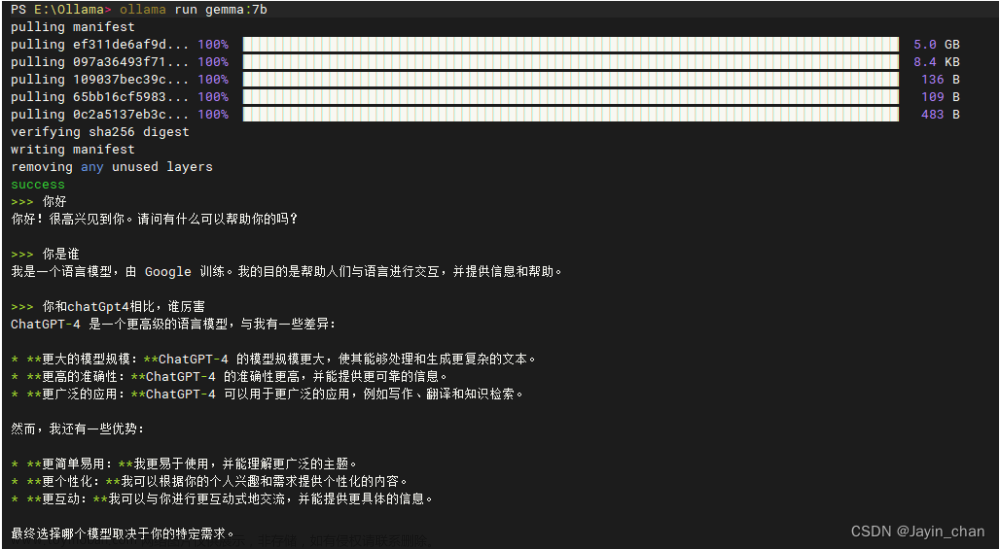
-
拉取的模型可以在存储目录blobs下看到

5.整合界面UI
-
Ollama WebUI、open-webui等。
需要在docker环境中运行,windows本地docker已经被我搞掉了,只有虚拟机里面才有docker环境。
虚拟机占用内存,破电脑性能一般般,不打算搞了。这个搞起来也还好,就是拉下镜像运行容器就行了。 -
JAN AI:https://jan.ai/ 下载windows版本客户端(开源的)
1)下载安装后修改下数据存储路径(随便要不要改),修改完重启即可。
2)修改ai模型源:
E:\Ollama\JANAI\engines\openai.json
(上一步中的数据存储路径下,找到engines\openai.json进行修改)
{
"full_url": "http://localhost:11434/v1/chat/completions"
}

3)添加模型配置:记得把里面的注释去掉。
E:\Ollama\JANAI\models\底下创建一个文件夹mine-gemma-7b(名字随便,我把models底下其他的文件夹都挪走备份了,方便管理而已)然后在底下创建个model.json文件 文章来源:https://www.toymoban.com/news/detail-857333.html
文章来源:https://www.toymoban.com/news/detail-857333.html
{
"sources": [
{
"filename": "gemma:7b", # 模型名称
"url": "https://ollama.com/library/gemma:7b" # 模型url
}
],
"id": "gemma:7b", #模型ID
"object": "model",
"name": "mine-gemma:7b", #显示在jan中模型名称,随便写不影响
"version": "1.0",
"description": "ollama本地gemma:7b", #随便写不影响
"format": "api",
"settings": {
},
"parameters": {
},
"metadata": {
"author": "Meta",
"tags": [
"General",
"Big Context Length"
]
},
"engine": "openai", # 需要配置
"state":"ready" # 需要配置
}

上述配置弄完之后重启下jan,然后再hub中就可以看到自己加的模型了,点击use即可使用
断网状态下是可以使用的。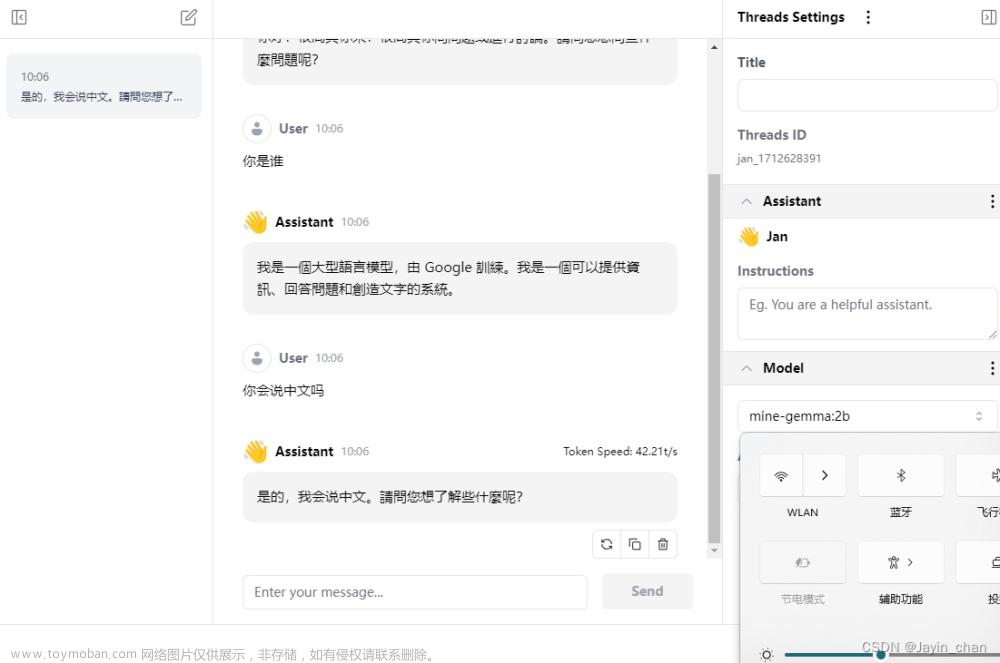 文章来源地址https://www.toymoban.com/news/detail-857333.html
文章来源地址https://www.toymoban.com/news/detail-857333.html
-
chatbox : https://chatboxai.app/zh 下载windows客户端
直接安装完按照下图选中相应模型就可以使用了。
都是自动加载的,如果对界面没啥要求的,推荐直接用chatbox就可以了,啥都不用整就可以用了。
到了这里,关于使用Ollama在本地运行AI大模型gemma的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!