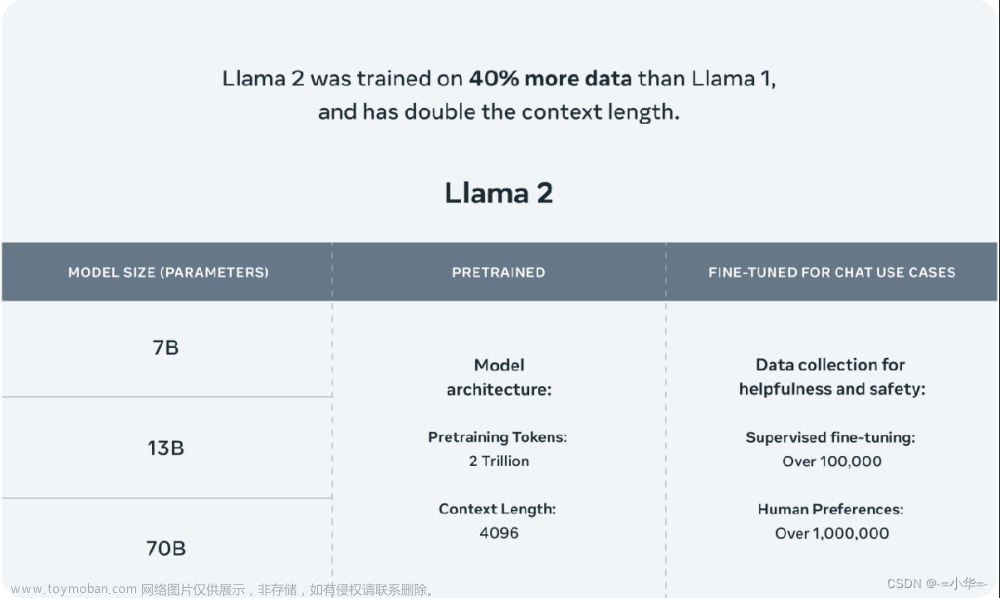
与同类大语言模型对比,它不仅对硬件的依赖更小,性能却更高。关键是完全开源,使得对模型在具有行业特性的场景中,有了高度定制的能力。
Gemma模型当下有四个版本,Gemma 7b, 2b, 2b-it, 7b-it 。通俗来说,2b及精简小巧,覆盖了现代流行的语言,对硬件依赖小。7b是常规型的,要有的基本都有了,硬件上最低需要8gb内存(显存)。后缀带it的版本,可适用于nvidia较新显卡,支持int8(fp8), tensorrt核心。但我的40hx硬件被阉割太厉害,连fp16都跑不起来,就没测试了。
安装环境:
我的硬件环境是虚拟机环境,40hx显卡直通,linux系统,远程访问。软件环境需要目标是ollama及open-webui。ollama是大语言模型的一个运行环境,open-webui是基于openAI及ollama的一个前端界面。目前ollama只支持nvidia的GPU加速,别的显卡就不讨论了。
安装过程:
-
虚拟机安装,这边需要注意的是,显卡必须直通,CPU必须在主机直通模式。不然GPU加速就不能成功。
-
安装常用的软件,wget curl git nvidia-toolkit
-
确认环境:nvidia-smi看一下显卡是不是正常驱动,cat /proc/cpuinfo 看一下AVX是否加载。这二点决定了GPU加速
-
在linux上运行:(要科学)
curl -fsSL https://ollama.com/install.sh | sh
然后等待安装完成,安装完成后,执行 ollama run gemma:2b 或者 ollama run gemma:7b 等模型下载完毕后,就进入字符界面,你就可以跟机器交流了。按ctrl-d可退出。
- 远程访问:
因为我是在服务器上安装的,操作需要在PC上,所以需要做一下远程
sudo nano /etc/systemd/system/ollama.service (我是ubuntu系统debian类似,其它系统查看services配置方法)
在nano中,[Service]下面加一行 Environment=“OLLAMA_HOST=0.0.0.0:11434”
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算文章来源:https://www.toymoban.com/news/detail-857358.html
据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算**文章来源地址https://www.toymoban.com/news/detail-857358.html
到了这里,关于google最新大语言模型gemma本地化部署_gemma对服务器要求的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!