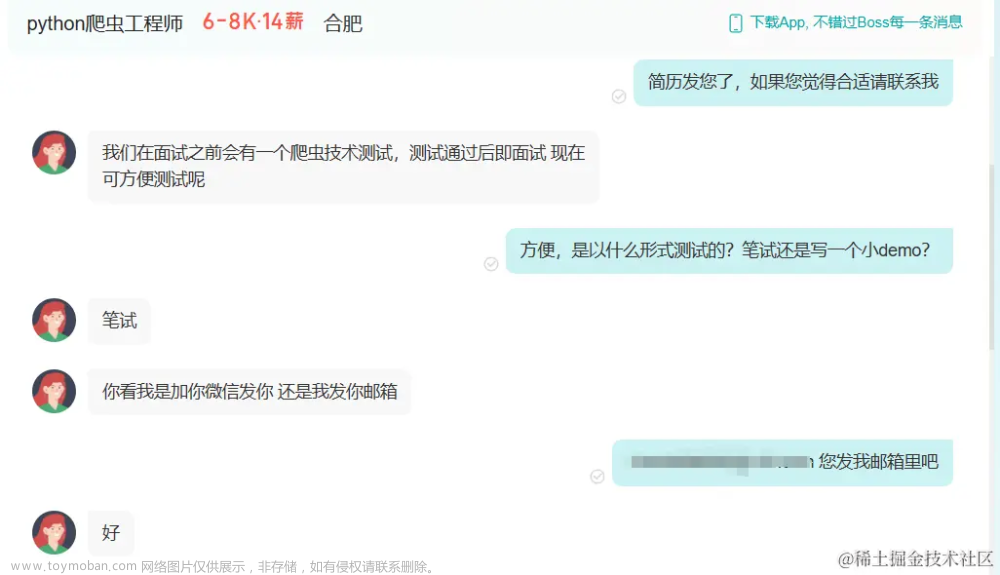
之前投简历时遇到了这样的一个笔试。本以为会是数据结构算法之类的没想到直接发了一个word直接提需求,感觉挺有意思就写了这篇文章,感兴趣的朋友可以看看。

拿到urllist
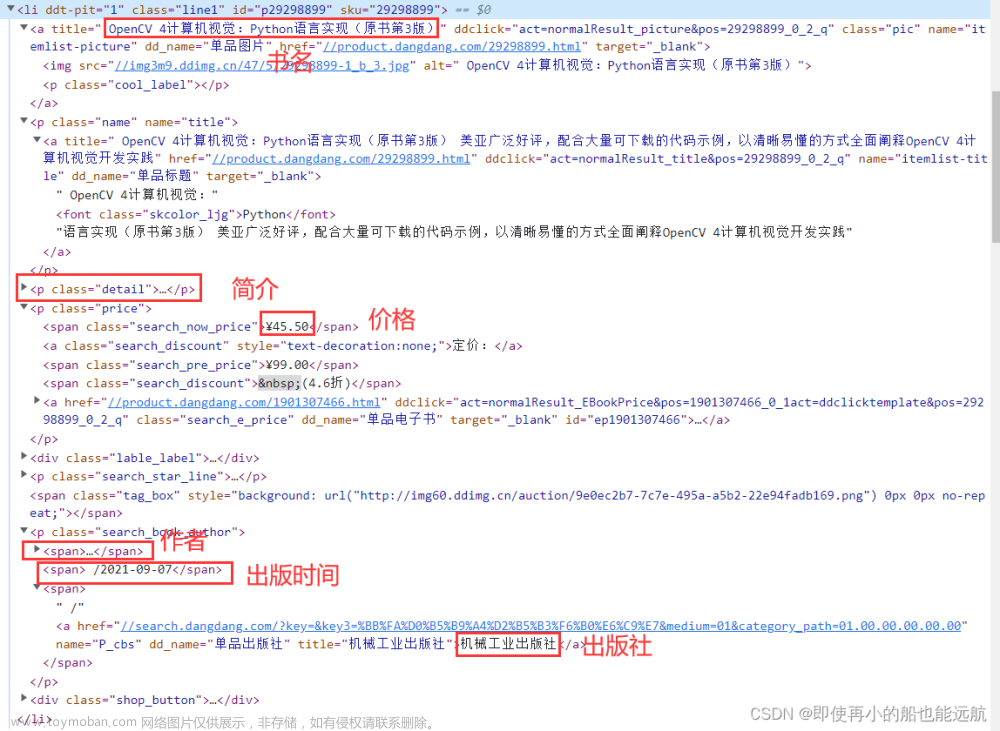
通过分析页面结构我们得以知道,这个页面本身没有新闻信息,是由js代码执行后才将信息插入到html中的,因此我们request拿到的代码是js执行前的代码,我们需要通过解析js代码来拿到想要的信息。
response = requests.get(url)
response.encoding = 'utf-8'
html_content = response.text
# print(html_content)
soup = BeautifulSoup(html_content, 'html.parser')
tag = soup.findAll('script')
# print(tag[9].text)
# 使用正则表达式匹配JavaScript代码中的item数组内容
pattern = re.compile(r"item[\d+]=new title_array('([^']+)','([^']+)','([^']+)');")
# 提取item数组中的数据
matches = pattern.findall(tag[9].text)
# 处理前15个匹配项
for i, match in enumerate(matches[:15], 1):
url, title, date = match
print("URL:", url)
print("Title:", title)
print("Date:", date)
这段代码用于从首页提取新闻标题、链接和日期信息。它首先发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析HTML文档。接着,通过正则表达式匹配JavaScript代码中的新闻数据,提取出匹配项,包括URL、标题和日期。最后,使用循环遍历这些匹配项,并打印输出每一条新闻的URL、标题和日期。
之后再进入详情页去拿到具体的内容。
获取详情页内容
在详情页中可以看出来,所有的正文信息都在p标签中,因此只需拿到p标签中的信息再进行筛选即可。文章来源:https://www.toymoban.com/news/detail-857398.html
def get_detailed(url,title,date):
response = requests.get(url)
response.encoding = 'utf-8'
html_content = response.text
# print(html_content)
soup = BeautifulSoup(html_content, 'html.parser')
# 使用CSS选择器定位元素
element = soup.findAll("p")
# 输出找到的元素
# print(element[15:])
data=''
data=data+title+'\n'+date+'\n'
for i in element[15:]:
data=i.text+data
print(data)
这个函数用于获取新闻的详细内容。它接收新闻的URL、标题和日期作为参数,并通过发送HTTP请求获取新闻页面的HTML内容。然后,使用BeautifulSoup库解析HTML文档,定位到新闻内容所在的段落元素。接着,将标题和日期添加到数据字符串中,并遍历段落元素,将每个段落的文本内容添加到数据字符串中。最后,将完整的新闻内容打印输出。文章来源地址https://www.toymoban.com/news/detail-857398.html
代码
# Author: 冷月半明
# Date: 2024/4/4
# Description: This script does XYZ.
import re
import requests
from bs4 import BeautifulSoup
def get_detailed(url,title,date):
response = requests.get(url)
response.encoding = 'utf-8'
html_content = response.text
# print(html_content)
soup = BeautifulSoup(html_content, 'html.parser')
# 使用CSS选择器定位元素
element = soup.findAll("p")
# 输出找到的元素
# print(element[15:])
data=''
data=data+title+'\n'+date+'\n'
for i in element[15:]:
data=i.text+data
print(data)
url = '*************************'
response = requests.get(url)
response.encoding = 'utf-8'
html_content = response.text
# print(html_content)
soup = BeautifulSoup(html_content, 'html.parser')
tag = soup.findAll('script')
# print(tag[9].text)
# 使用正则表达式匹配JavaScript代码中的item数组内容
pattern = re.compile(r"item[\d+]=new title_array('([^']+)','([^']+)','([^']+)');")
# 提取item数组中的数据
matches = pattern.findall(tag[9].text)
# 处理前15个匹配项
for i, match in enumerate(matches[:15], 1):
url, title, date = match
print("URL:", url)
print("Title:", title)
print("Date:", date)
# 调用get_detailed函数
get_detailed(url, title,date)
到了这里,关于爬虫机试题-爬取新闻网站的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!