目录
一、上传、解压&配置
(一)上传
(二)解压
(三)配置hadoop系统环境变量
1.配置hadoop环境变量
2.让环境变量生效
3.验证hadoop系统环境变量
二、修改配置文件
(一)前置介绍
(二)更改配置文件
1.配置Hadoop集群主机点
2.修改core-site.xml文件
3.修改hdfs-site.xml文件
4.修改mapred-site.xml文件
5.修改yarn-site.文件
6.修改slaves文件
三、分发
(一)分发hadoop安装目录
(二)分发系统变量文件
四、启动集群
(一)格式化集群
(二)启动集群
(三)通过UI查看Hadoop运行状态
本文是以root身份来控制集群启停的,后面会出一篇以hadoop用户来控制集群启停博客。
hadoop2.7.3.tar.gz 安装包提取
链接:https://pan.baidu.com/s/1W3TidAVddQZ4n5Lm2NJB_Q
提取码:ay17
一、上传、解压&配置
(一)上传
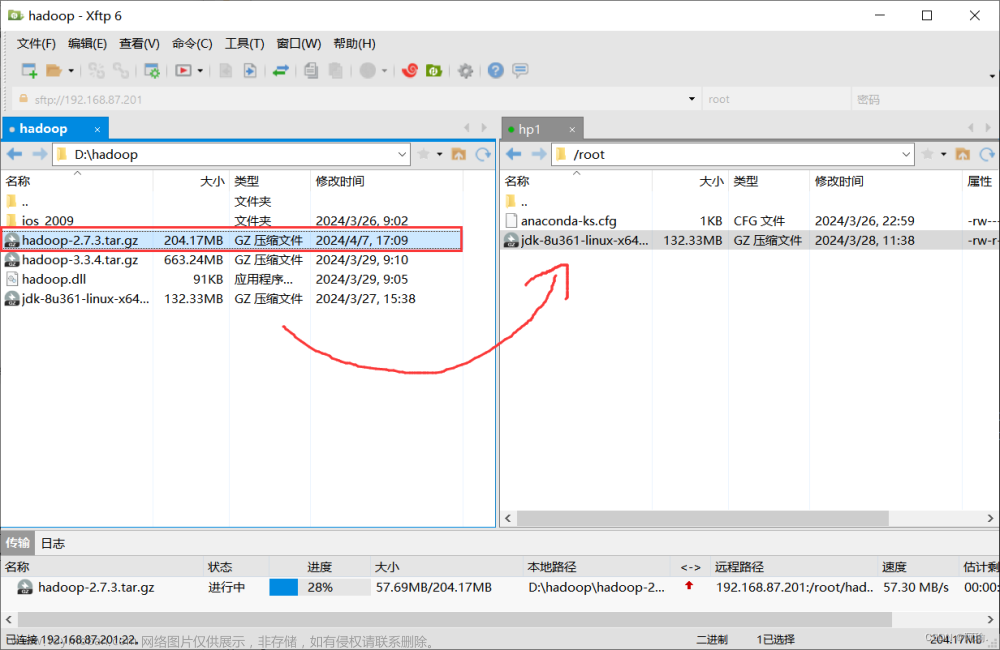
1.上传hadoop安装包到hp1节点中

(二)解压
1.解压缩安装包到/export/server/中
tar -zxvf hadoop-2.7.3.tar.gz -C /export/server/

2.将 hadoop-2.7.3 改名为hadoop
首先进入相应目录
然后将 hadoop-2.7.3 改名为hadoop,命令为
mv hadoop-2.7.3 hadoop

(三)配置hadoop系统环境变量
1.配置hadoop环境变量
vi /etc/profile

在里面添加如下内容:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

2.让环境变量生效
为了让系统变量文件中添加的内容生效,执行 “ source /etc/profile ”命令初始化系统环境变量,使添加的hadoop系统环境变量生效。

3.验证hadoop系统环境变量
在虚拟机hp1任意目录执行 “ hadoop version ” 命令,查看当前虚拟机中hadoop的版本号

二、修改配置文件
(一)前置介绍
配置HDFS集群,我们主要涉及到如下文件的修改:
| hadoop-env.sh |
配置Hadoop运行所需的环境变量 |
| yarn-env.sh |
配置YARN运行所需的环境变量 |
| core-site.xml |
Hadoop核心全局配置文件 |
| hdfs-site.xml |
HDFS核心配置文件 |
| mapred-site.xml |
MapReduce核心配置文件 |
| yarn-site.xml |
YARN核心配置文件 |
| slaves | 配置从节点(DataNode)有哪些 |
这些文件均存在于 $HADOOP_HOME/etc/hadoop文件夹中
PS: $HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即 /export/server/hadoop
修改文件之间需要进入到对应目录

(二)更改配置文件
1.配置Hadoop集群主机点
vim hadoop-env.sh
找到JAVA_HOME参数位置,进入如下修改(注意JDK路径)

上述配置文件中设置的是Hadoop运行时需要的JDK环境变量,目的是让Hadoop启动时能够执行守护进程。
2.修改core-site.xml文件
vim core-site.xml
该文件是Hadoop的核心配置文件,其目的是配置HDFS地址、端口号,以及临时文件目录。打开配置文件后,在<configuration></configuration>之间添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://hp1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop/tmp</value>
</property>

上述核心配置文件中,配置了HDFS的主进程NameNode运行主机(也就是此次Hadoop集群的主节点位置),同时配置了Hadoop运行时生成数据的临时目录。
3.修改hdfs-site.xml文件
vim hdfs-site.xml
该文件用于设置HDFS的NameNode和DataNode两大进程。打开该配置文件,在<configuration></configuration>之间添加如下内容
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hp2:50090</value>
</property>

在上述配置文件中,配置了HDFS数据块的副本数量(默认值就是3),并根据需要设置了Secondary NameNode所在服务的HTTP协议地址。
4.修改mapred-site.xml文件
该文件是MapReduce的核心配置文件,用于指定MapReduce运行时框架。因为hadoop版本不同,有些版本里面在/etc/hadoop/目录中默认没有该文件,需要先通过 “ cp mapred-site.xml.template mapred-site.xml " 命令将文件复制并重命名为 “ mapred-site.xml "。接着,打开mapred-site.xml文件进行修改:
vim mapred-site.xml

在<configuration></configuration>之间添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

5.修改yarn-site.文件
vim yarn-site.xml
本文件是YARN框架的核心配置文件,需要指定YARN集群的管理者。
在<configuration></configuration>之间添加如下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hp1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

在上述配置文件中,配置了YARN的主进程ResourceManager运行主机为hp1,同时配置了NodeManager运行时的附属服务,需要配置为mapreduce_shuffle才能正常运行MapReduce默认程序。
6.修改slaves文件
如果是 hadoop 3.x版本即为workers文件
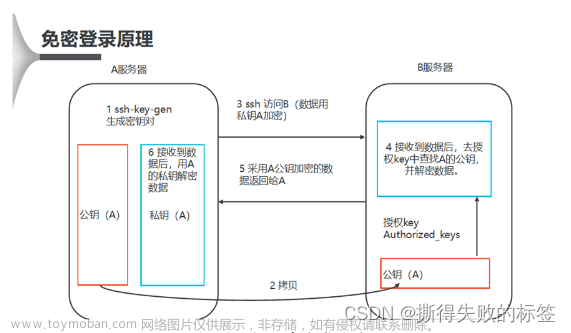
该文件用于记录Hadoop集群所有从节点(HDFS的DataNode 和 YARN 的 NodeManager 所在主机)的主机名,用来配合一键启动脚本启动集群从节点(并且还需要保证关联节点配置了SSH免密登录)。打开该配置文件,先删除里面的内容(默认localhost),然后配置如下内容
hp1
hp2
hp3

在上述配置中,配置了Hadoop集群所有从节点的主机名为hp1、hp2、hp3(这是因为此次在该3台机器上搭建Hadoop集群,同时前面的配置文件hdfs-site.xml指定了HDFS服务副本数量为3)
三、分发
(一)分发hadoop安装目录
使用scp命令将虚拟机hp1的hadoop安装目录分发至虚拟机hp2和hp3中存放安装程序的目录
scp -r /export/server/hadoop root@hp2:/export/server/


scp -r /export/server/hadoop root@hp3:/export/server/


(二)分发系统变量文件
scp /etc/profile hp2:/etc/profile
scp /etc/profile hp3:/etc/profile



执行完上述所有指令后,还需要再其他子节点hp2、hp3上分别执行 "source /etc/profile " 指令立即刷新配置文件。
至此,整个集群所有节点就都有了Hadoop运行所需的环境和文件,Hadoop集群也就安装配置完成。
四、启动集群
(一)格式化集群
hdfs namenode -format 或者 hadoop namenode -format

格式化指令只需要再Hadoop集群初次启动前执行即可,后续重复启动就不需要执行格式化了。
(二)启动集群
一键启动集群命令:start-all.sh
一键关闭集群命令:stop-all.sh

在整个Hadoop集群服务启动完成之后,可以在各自机器上通过jps指令查看各节点的服务进程启动情况



(三)通过UI查看Hadoop运行状态
Hadoop集群正常启动后,它默认开放了50070和8088两个端口,分别用于监控HDFS集群和YARN集群。通过UI可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。
http://hp1:50070(集群服务IP+端口号)
查看HDFS集群状态

http://hp1:8088 查看YARN集群状态文章来源:https://www.toymoban.com/news/detail-857458.html
 文章来源地址https://www.toymoban.com/news/detail-857458.html
文章来源地址https://www.toymoban.com/news/detail-857458.html
到了这里,关于Hadoop集群部署(完全分布式模式、hadoop2.7.3+安装包)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!