自然语言处理
对自然语言处理相关的知识点进行总结。
自然语言处理(NLP)是一种人工智能技术,用于处理和理解自然语言文本。NLP 的目标是使计算机能够像人类一样理解、处理或生成自然语言,以便能够完成各种任务,例如文本分类、情感分析、机器翻译、问答系统等。
NLP 的实现通常需要使用机器学习和深度学习技术,例如使用神经网络、循环神经网络(RNN)、长短时记忆网络(LSTM)等。NLP 的实现还需要使用大量的语料库和数据集,以便训练模型。NLP 的应用领域非常广泛,包括文本挖掘、信息检索、智能客服、智能写作、智能翻译等。
1. word2vec是什么
- 一一一一一一一一一一一一一一一一一一一一一一一
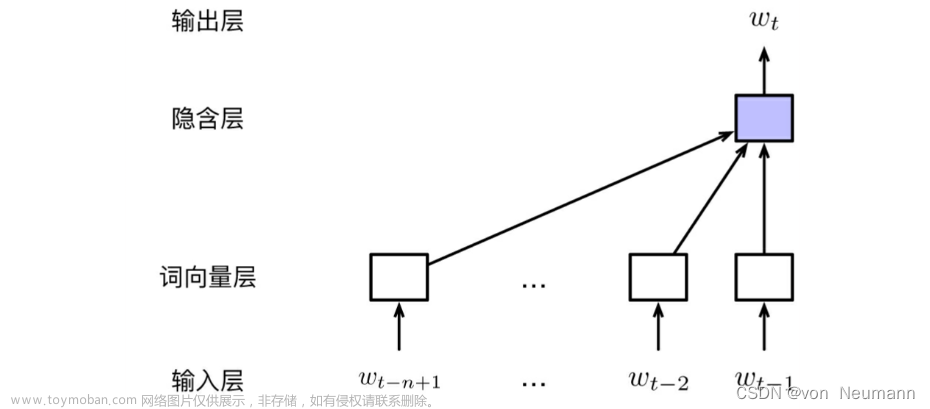
Word2Vec 用于将文本转换为向量。它是一种基于神经网络的语言模型,通过对大量文本数据进行训练,学习到文本中的语义信息,并将其表示为向量。
Word2Vec 的基本思想是将文本中的每个单词表示为一个向量,这些向量之间的相似性可以反映单词之间的语义关系。在训练过程中,Word2Vec 模型会根据上下文信息来预测下一个单词,从而学习到单词之间的语义关系。
Word2Vec 模型的训练过程通常分为两个阶段:
- 第一阶段是无监督学习,模型会根据大量文本数据来学习单词之间的语义关系;
- 第二阶段是有监督学习,模型会根据已知的标签信息来学习如何将文本分类或生成。
Word2Vec 模型的优点是它可以学习到单词之间的语义关系,并且不需要人工标注数据。此外,Word2Vec 模型的计算效率很高,可以在大规模文本数据上进行训练。
Word2Vec 模型的缺点是:
- 它无法处理长文本,并且无法学习到单词之间的复杂关系。此外,Word2Vec 模型的预测结果可能不准确,需要进一步的优化和改进。
2. 常用的NLP工具和软件
这些工具和库的特点和优势如下:
- NLTK: 是一个自然语言处理工具包,提供了丰富的文本处理功能,如分词、词性标注、命名实体识别、文本分类等。
- Gensim: 是一个用于文本建模的库,提供了多种文本表示方法,如词向量、主题模型等,可以用于文本分类、聚类、推荐系统等任务。
- Sklearn: 是一个机器学习库,提供了多种机器学习算法,如朴素贝叶斯、支持向量机、随机森林等,可以用于文本分类、情感分析等任务。
- Spacy: 是一个基于深度学习的自然语言处理库,提供了高效的词法分析、命名实体识别、关系抽取等功能,可以用于文本挖掘、问答系统等任务。
- TextBlob: 是一个文本处理库,提供了简单易用的文本分类、情感分析、关键词提取等功能,可以用于文本挖掘、情感分析等任务。
- Jieba: 是一个中文分词库,提供了高效的中文分词功能,可以用于中文文本处理、信息检索等任务。
- spaCy:是一个基于Python的自然语言处理库,提供了高效的词法分析、命名实体识别、关系抽取等功能。它使用了基于注意力机制的深度学习模型,可以处理大规模的文本数据。
- Stanford CoreNLP:是一个功能强大的自然语言处理工具,提供了词法分析、句法分析、命名实体识别、关系抽取等功能。它使用了基于规则和统计的方法,可以处理多种语言的文本数据。
- OpenNLP:是一个开源的自然语言处理工具,提供了词法分析、句法分析、命名实体识别、关系抽取等功能。它使用了基于规则和统计的方法,可以处理多种语言的文本数据。
- FastText:是一个基于词向量的文本分类工具,它使用了深度学习中的卷积神经网络(CNN)和循环神经网络(RNN)来对文本进行分类。它的优点是速度快、效率高,可以处理大规模的文本数据。
3. 朴素贝叶斯分类器
在各种类型的分类器中,朴素贝叶斯被称为最简单也最常用的生成式模型。朴素贝叶斯分类器是一种基于贝叶斯定理将联合概率转化为条件概率的分类方法,它通过计算样本属于每个类别的概率来进行分类。具体来说,朴素贝叶斯分类器假设每个特征都是独立的,并且每个类别的先验概率已知。然后,根据已知的先验概率和特征值,计算样本属于每个类别的后验概率,并选择后验概率最大的类别作为分类结果。
朴素贝叶斯分类器的优点是简单、快速、易于实现,并且在许多情况下表现良好。它的缺点是对数据的假设比较强,当数据的特征之间存在相关性时,分类效果可能会受到影响。此外,朴素贝叶斯分类器需要已知每个类别的先验概率,如果先验概率不准确,分类效果也会受到影响。
朴素贝叶斯分类器的实施步骤如下:
- 收集数据:收集训练数据和测试数据。
- 特征提取:提取数据的特征,例如单词、短语、词性等。
- 概率估计:估计每个类别的先验概率和每个特征的条件概率。
- 分类:根据已知的先验概率和特征值,计算样本属于每个类别的后验概率,并选择后验概率最大的类别作为分类结果。
在实施朴素贝叶斯分类器时,需要注意以下几点:
- 特征选择:选择合适的特征对于分类效果至关重要。应该选择能够有效区分不同类别的特征,并且特征之间应该尽可能独立。
- 概率估计:估计每个类别的先验概率和每个特征的条件概率时,应该使用合适的方法,例如最大似然估计或贝叶斯估计。
- 模型选择:选择合适的朴素贝叶斯分类器模型,例如高斯朴素贝叶斯分类器或多项式朴素贝叶斯分类器。
- 模型评估:使用合适的评估指标,例如准确率、召回率、F1 值等,来评估模型的性能。
- 缺点:无法有效地将文本的语义信息表达出来,并且当数据集规模较大时,会出现存储延迟与计算能力迟钝的问题。
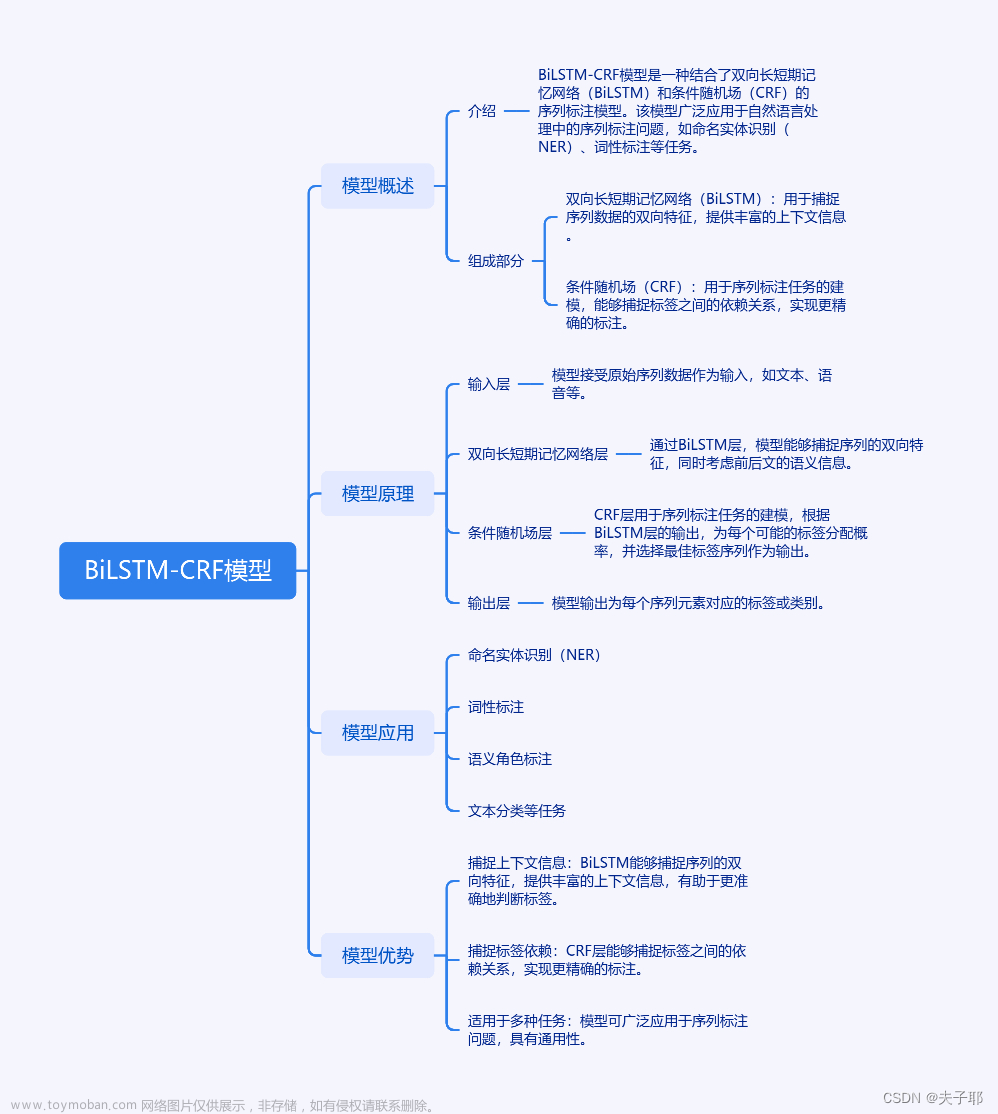
4. BiLSTM-CRF模型怎么去实现
BiLSTM-CRF 模型是一种用于序列标注任务的深度学习模型,它结合了双向长短期记忆网络(BiLSTM)和条件随机场(CRF)的优点,可以有效地捕捉序列中的长期依赖关系和上下文信息。
BiLSTM 层是一种特殊的 LSTM 网络,它包含两个 LSTM 网络,一个用于正向处理序列,另一个用于反向处理序列。这样可以同时捕捉序列的正向和反向信息,从而更好地捕捉序列中的长期依赖关系。
CRF 层是一种用于序列标注任务的概率模型,它通过对每个位置的标记进行概率计算,从而得到整个序列的标注结果。CRF 层可以有效地处理标签之间的依赖关系,从而提高模型的性能。
下面是实现 BiLSTM-CRF 模型的步骤:
- 数据预处理:首先需要对数据进行预处理,包括文本清洗、分词、词性标注等。可以使用现有的自然语言处理工具来完成这些任务。
- 模型架构:BiLSTM-CRF 模型由 BiLSTM 层和 CRF 层组成。BiLSTM 层用于捕捉序列中的长期依赖关系,而 CRF 层用于对输出进行标注。
- 训练模型:使用训练数据对模型进行训练,可以使用交叉熵损失函数和随机梯度下降(SGD)算法来优化模型的参数。
- 预测:使用训练好的模型对测试数据进行预测,可以得到每个位置的标注结果。
- 评估:使用评估指标,如准确率、召回率、F1 值等,对模型的性能进行评估。
5. Bert模型实现NER
6. 命名实体识别任务中,怎么去处理数据分布不均的问题?
1. 重采样数据集
(1)欠采样(减少数据量大的类别的样本,平衡稀有类别样本的数据量,缺点:丢失了数据,影响模型效果)对于多数类别的样本,可以从中随机抽取样本,减少该类别的样本数量,以平衡各个类别的样本分布。
(2)过采样(增加稀有样本的数量,可通过使用重复、自举或合成少数类过采样等方法(SMOTE)来生成,缺点:重复样本导致过拟合)对于少数类别的样本,可以通过复制、生成或引入一些变化,使得该类别的样本数量增加,以平衡各个类别的样本分布。
(3)数据增强(Data Augmentation):对训练数据进行增强,引入一些变化,以增加数据的多样性。
2. 算法
(1)类别权重调整:在训练过程中,可以为不同类别赋予不同的权重,使得模型更关注样本较少的类别。这通常在损失函数中通过引入类别权重参数来实现。Loss权重阶段:训练集数据分布不均衡,针对样本不均衡,训练时针对不同
(2)的标签loss设置权重,不断迭代调整权重值得到最优组合。
(3)生成对抗网络:使用生成对抗网络来生成合成的样本,特别是对于少数类别的样本。这有助于增加少数类别的样本数量,提高模型对这些类别的学习能力。
(4)集成学习:使用集成学习方法,如投票、堆叠等,将多个模型的预测结果结合起来,从而平衡各个类别的影响。
(5)迁移学习:利用在其他任务上预训练的模型,通过微调或特征提取来适应目标任务。这对于数据不足的情况下有助于提升模型性能。
(6)使用其他评估指标:在不均衡数据集上,除了准确度(可能不适用于高度不均衡的问题)之外,可以使用其他评估指标如精确度、召回率、F1分数等,更全面地评估模型性能。
(7)生成类别权重:根据每个类别的样本数量为其分配权重,使得样本数量较少的类别具有更大的权重。
(8)多任务学习(Multi-task Learning):将多个相关任务结合在一起学习,从而能够更好地利用数据。
(9)生成式模型(Generative Models):使用生成式模型如变分自编码器(VAE)或生成对抗网络(GAN)来生成缺乏样本的类别。
(10)BERT在样本类别不平衡数据中预测效果仍然表现突出。文章来源:https://www.toymoban.com/news/detail-857653.html
7. 用户问题检索相关文本时,具体都用了哪些技术,有没有训练自己的检索模型?
问题检索技术:
1. 索引:
1、通过TF-IDF(评估查询词对文档重要性的权重)、向量空间模型、倒序索引、概率检索模型、模糊搜索,从大量文本数据中检索、匹配与用户查询相关的文本2.
2. 基于规则+知识图谱技术:
1、针对问题进行语义理解:提取关键词、问句分类;
2、通过关键词和问句类型,在图数据中,检索指定的实体和类别的数据,通过答案模版加入检索得到的答案进行检索结果输出。
3. 基于预训练模型技术:
1、对预训练模型进行微调;
2、对文问句的语义进行再次建模训练,进行tokenization的操作,输入至模型中,获得问句中的上下文语义的语义关键信息,模型再进行预测,生成可能是正确答案概率最高的词,并合并成一个句子文章来源地址https://www.toymoban.com/news/detail-857653.html
8. 文本向量(Text Embeddings)是什么?
- 将文本转成一组浮点数:每个下标 i i i,对应一个维度
- 整个数组对应一个 n n n 维空间的一个点,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
9. 文本向量是怎么得到的?
- 构建相关(正立)与不相关(负例)的句子对儿样本
- 训练双塔式模型,让正例间的距离小,负例间的距离大
到了这里,关于自然语言处理技术(Natural Language Processing)知识点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!