-
如果客户端与待拉取消息的broker节点有待发送的网络请求(见代码@4),则本次拉取任务将不会再发起新的拉取请求,待已有的请求处理完毕后才会拉取新的消息。
-
拉取消息时需要指定拉取消息偏移量,来自队列负载算法时指定,主要消费组的最新消费位点。

Step2:按Node依次构建请求节点,并通过client的send方法将请求异步发送,当收到请求结果后会调用对应的事件监听器,这里主要的是一次拉取最大的字节数50M。
值得注意的是在Kafka中调用client的send方法并不会真正触发网络请求,而是将请求放到发送缓冲区中,Client的poll方法才会真正触发底层网络请求。
Step3:当客户端收到服务端请求后会将原始结果放入到completedFetches中,等待客户端从中解析。
本篇文章暂时不关注服务端对fetch请求的处理,等到详细剖析了Kafka的存储相关细节后再回过来看Fetch请求的响应。
1.2 Fetcher的fetchedRecords方法详解
向服务端发送拉取请求异步返回后会将结果返回到一个completedFetches中,也可以理解为接收缓存区,接下来将从缓存区中将结果解析并返回给消费者消费。从接收缓存区中解析数据的具体实现见Fetcher的fetchedRecords方法。

核心实现要点如下:
- 首先说明一下nextInLineRecords的含义,接下来的fetchedRecords方法将从这里获取值,该参数主要是因为引入了maxPollRecords(默认为500),一次拉取的消息条数,一次Fetch操作一次每一个分区最多返回50M数据,可能包含的消息条数大于maxPollRecords。
如果nextInLineRecords为空或者所有内容已被拉取,则从completedFetch中解析。
-
从completedFetch中解析解析成nextInlineRecords。
-
从nextInlineRecords中继续解析数据。
关于将CompletedFetch中解析成PartitionRecords以及从PartitionRecords提取数据成Map< TopicPartition, List< ConsumerRecord< K, V>>>的最终供应用程序消费的数据结构,代码实现非常简单,这里就不再介绍。
有关服务端响应SEND_FETCH的相关分析,将在详细分析Kafka存储相关机制时再介绍。在深入存储细节时,从消息拉取,消息写入为切入点是一个非常不错的选择。
2、消息消费端模型
阅读源码是手段而不是目的,通过阅读源码,我们应该总结提炼一下Kafka消息拉取模型(特点),以便更好的指导实践。
首先再强调一下消费端的三个重要参数:
- fetch.max.bytes
客户端单个Fetch请求一次拉取的最大字节数,默认为50M,根据上面的源码分析得知,Kafka会按Broker节点为维度进行拉取, 即按照队列负载算法分配在同一个Broker上的多个队列进行聚合,同时尽量保证各个分区的拉取平衡,通过max.partition.fetch.bytes参数设置。
- max.partition.fetch.bytes
一次fetch拉取单个队列最大拉取字节数量,默认为1M。
- max.poll.records
调用一次KafkaConsumer的poll方法,返回的消息条数,默认为500条。
实践思考:fetch.max.bytes默认是max.partition.fetch.bytes的50倍,也就是默认情况一下,一个消费者一个Node节点上至少需要分配到50个队列,才能尽量满额拉取。但50个分区(队列)可以来源于这个消费组订阅的所有的topic。
2.1Kafka消费线程拉取线程模型
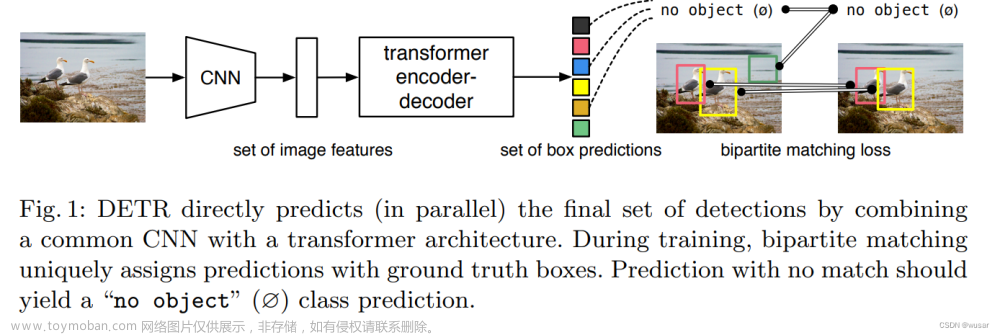
KafkaConsumer并不是线程安全的,即KafkaConsumer的所有方法调用必须在同一个线程中,但消息拉取却是是并发的,线程模型说明如下图所示:

其核心设计理念是KafkaConsumer在调用poll方法时,如果**本地缓存区中(completedFeches)**存在未拉取的消息,则直接从本地缓存区中拉取消息,否则会调用client#send方法进行异步多线程并行发送拉取请求,发往不同的broker节点的请求是并发执行,执行完毕后,再将结果放入到poll方法所在线程中的缓存区,实现多个线程的协同。
2.2 poll方法返回给消费端线程特点
pol l方法会从缓存区中依次获取一个CompletedFetch对象,一次只从CompletedFetch对象中获取500条消息,一个CompletedFetch对象包含一个分区的数据,默认最大的消息体大小为1M,可通过max.partition.fetch.bytes改变默认值。
如果一个分区中消息超过500条,则KafkaConsumer的poll方法将只会返回1个分区的数据,这样在顺序消费时基于单分区的顺序性保证时如果采取与RocketMQl类似的机制,对分区加锁,则其并发度非常低,因为此时顺序消费的并发度取决于这500条消息包含的分区个数。
Kafka顺序消费最佳实践: 单分区中消息可以并发执行,但要保证同一个key的消息必须串行执行。因为在实践应用场景中,通常只需要同一个业务实体的不同消息顺序执行。
好了,本文就介绍到这里了,一键三连(关注、点赞、留言)是对我最大的鼓励。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。

《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
习,当自己能上手再买这些书看又是非常有收获的事了。文章来源:https://www.toymoban.com/news/detail-857979.html
[外链图片转存中…(img-iCZLCLNd-1712266206558)]
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!文章来源地址https://www.toymoban.com/news/detail-857979.html
到了这里,关于一文读懂kafka消息拉取机制|线程拉取模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!