精准一次性投递
在Kafka中,精准一次性投递(Exactly Once)=至少投递一次(At Least Once)+幂等性。
至少投递一次(At Least Once):将生产端参数acks设置为-1(all),可以保证生产端发送到Broker的消息不会丢失,即:至少投递一次(At Least Once)。
幂等性:
- 幂等生产者幂保证单分区单会话内精准一次性投递消息。
- 事务生产者保证跨分区跨会话精准一次性投递消息。
幂等生产者
幂等生产者指的是当发送同一条消息时,消息在Broker端只会被持久化一次,消息不丢失也不重复,它在底层设计架构中引入了ProducerID和SequenceNumber:
- ProducerID:每个生产者启动时,Kafka会为生产者分配一个唯一标识ProducerID(注意:生产者重启时会重新分配ProducerID);
- SequenceNumber :针对每个生产者(即:每个ProducerID),发送到指定Topic中某个分区内的消息都会为其生成一个从0开始单调递增的SequenceNumber值。
幂等性配置:生产端设置参数enable.idempotence为true。
注意:开启幂等性后,retries(重试次数)配置将默认为Integer.MAX_VALUE,acks配置将默认为-1,如果此时手动将acks设置为0,会报错。
幂等生产者实现原理
生产者在初始化时会被分配一个唯一的ProducerID(凡是开启幂等性生产者都需要生成全局唯一的ProducerID,如开启事务,则由TransactionCoordinator节点生成ProducerID,未开启事务,则由Broker自身生成ProducerID),该ProducerID对用户完全透明。
Leader所在的Broker会按<ProducerID, Topic, Partition>维度缓存SequenceNumber,对于接收的每条消息:
- 如果消息序列号比Broker缓存中的序列号大1,则接受该消息,否则丢弃该消息。
- 如果消息序列号比Broker缓存中的序列号大1以上,说明中间有数据尚未写入(即:乱序),此时Broker拒绝该消息。
- 如果消息序列号小于等于Broker缓存中的序列号,说明该消息已被保存(即:重复消息),Broker丢弃该消息。
注意:生产端是以批次的方式发送消息,每个批次包含了多条消息,因此,生产端发送消息时,只会设置该批次第一条消息的序列号,该批次中其他消息的序列号是根据第一条消息的序列号计算得来。
ProducerID生产机制:
- ProducerID通过ProducerIdManager的generateProducerId()方法获取,每个Broker都会在本地维护一个ProducerID段,当本地的ProducerID段用完后,会去Zookeeper上申请(节点:/latest_producer_id_block,每次申请1000个)。
- 当Broker向Zookeeper申请ProducerID段时,会先获取Zookeeper中保存的当前ProducerID段最大值,然后尝试将要申请的ProducerID段写回ZK,这样其他Broker在尝试申请时,不会出现ProducerID段重复的情况。
- 若开启事务,则由TransactionCoordinator节点生成全局唯一的ProducerID。
重新选举Leader后生产者幂等性是否有效?
有效。因为Leader分区所在的Broker缓存了PID、SequenceNumber等信息,而Leader分区中所有消息都会被复制到Followers中,当ISR中某个Follower被选举为新的Leader时,新Leader内部的消息中已经存储了PID、SequenceNumber等信息信息,因此,新Leader接收生产者消息时仍能实现消息幂等。
事务生产者
Kafka的幂等生产者只能保证单分区单会话内精准一次性投递消息,不能解决跨会话跨分区的问题。Kafka0.11版本开始引入了事务生产者,事务生产者保证Kafka在幂等生产者的基础上,实现跨分区跨会话精准一次性投递消息。
事务场景
事务生产者使用场景:
- Producer发送多条消息组成一个事务,这些消息需要对Consumer同时可见或者同时不可见 。
- Producer可能会给多个Topic、多个Partition发消息,这些消息需要能放在一个事务中,这是典型的分布式事务场景。
- Kafka的应用场景经常是需要先消费一个Topic,处理后再发到另一个Topic,这个Consume-Transform-Produce过程需要放到一个事务中,比如:在消息处理或者发送的过程中失败,消费偏移量不能提交。
- Producer或者Producer所在的应用可能会挂掉,新的Producer启动以后需要处理之前未完成的事务 。
- 流式处理的拓扑可能会比较深,如果下游只有等上游消息事务提交以后才能读到,可能会导致RT非常长吞吐量也随之下降很多,所以需要实现Read Committed和Read Uncommitted两种事务隔离级别。
注意:当事务中仅存在Consumer消费消息的操作时,消费事务消息和Consumer手动提交Offset并没有区别。因此单纯的消费消息并不是Kafka引入事务机制的原因,单纯的消费消息也没有必要存在于一个事务中。
事务生产者实现原理
Kafka为了支持事务特性,引入一个新的组件:Transaction Coordinator,主要负责为生产者分配PID,记录事务状态等操作。
如图所示:
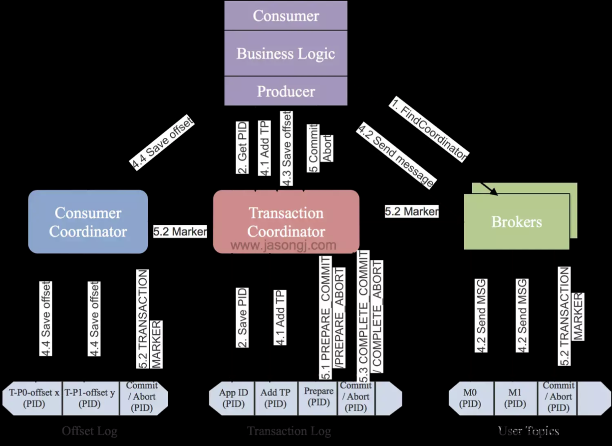
生产者事务执行流程:
- 1)初始化事务:生产者向事务协调器发送InitProducerIdRequest请求,为生产者生成对应的PID。
- 2)开启事务:生产者调用KafkaProducer#beginTransaction()方法开启事务。
- 3)发送事务消息:
- 生产者发送消息前,向事务协调器发送AddPartitionsToTxnRequest请求,增量记录事务关联的TopicPartition列表。
- 生产者向Broker发送事务消息。
- 生产者向事务协调器发送AddOffsetsToTxnRequest请求,增量记录Offsets提交前,Group Coordinator(消费者组协调器)对应的TopicPartition列表。
- 生产者向消费者组协调器发送TxnOffsetCommitRequest请求,将生产者提交的Offsets放置在事务性待确认列表。
- 4)提交或回滚事务:生产者向事务协调器发送EndTxnRequest请求:
- 将Prepare消息写入 __transaction_state。
- 事务协调器向事务关联的TopicPartitions主副本和__transaction_state中写入EndTransactionMarker标记。
- 5)超时事务中止:事务协调器以10s/次的频率轮询检测进行中的事务是否已超时,若事务已超时,则推进Epoch、中止当前事务。后续再次收到老的生产者(Epoch小于当前Epoch)消息将抛出ProducerFencedException异常。
开启事务配置
对于生产者,通过KafkaProducer的beginTransaction()方法可以开启一个事务,调用该方法后,生产者本地会标记已经开启了一个新的事务,只有在生产者发送第一条消息之后TransactionCoordinator才会认为该事务已经开启。同时,需要设置transactional.id属性,设置了transactional.id属性后,enable.idempotence属性会自动设置为true。
对于消费者,需要设置isolation.level = read_committed,这样Consumer只会读取已经提交了事务的消息。另外,需要设置enable.auto.commit = false来关闭自动提交Offset功能。
生产者事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的TransactionID,并将生产者的PID与TransactionID绑定,这样当生产者重启后,就可以通过生产者绑定的TransactionID获得原来的PID。
为了管理事务,Kafka引入了一个新的组件Transaction Coordinator(事务协调器,事务协调器为Leader分区所在的Broker节点),生产者就是通过与Transaction Coordinator交互获得TransactionID对应的任务状态,Transaction Coordinator负责将事务操作写入Kafka的一个内部Topic(__transaction_state(默认分区数:50)),这样即使Transaction Coordinator宕机重启,由于事务状态得到保存,未完成的事务状态可以得到恢复。
消费者事务
对于消费者而言,事务能保证的语义相对较弱,无法保证已提交事务中的消息都能被消费。原因如下:
- 对采用日志压缩策略的主题而言,事务中的某些消息有可能被清理(相同Key的消息,后写入的消息会覆盖前面写入的消息)。
- 事务中的消息可能分布在同一个分区的多个日志分段(Segment)中,当旧的日志分段被删除时,对应的消息可能会丢失。
- 消费者可以通过seek()方法访问任意offset的消息,从而可能遗漏事务中的部分消息。
- 消费者在消费时可能没有分配到事务内的所有分区,因此不能读取事务中的所有消息。
消费端有一个isolation.level参数,该参数用来配置消费者的事务隔离级别(类型为字符串),有效值为read_uncommitted和read_committed,表示消费者消费到的位置,如果设置为read_committed,那么消费者会忽略事务未提交的消息,即:只能消费到LSO(Last Stable Offset,即:最后稳定偏移)的位置。默认值为read_uncommitted,即:可以消费到HW处的位置,注意:Follower副本的事务隔离级别为read_uncommitted,且不可修改。
在开启Kafka事务时,生产者发送了message1、message2、message3、message4四条消息到Broker中,如果生产者没有提交事务,对于read_committed隔离级别的消费者而言,是看不到这些消息的,设置为read_uncommitted隔离级别则可以看到。事务中第一条消息的位置标记为firstUnstableOffset(即:message1的位置)。
LSO会影响Kafka消息滞后量(Kafka Lag,即:消息堆积量)的计算。如图所示:

图中:在read_uncommitted(默认)隔离级别下,Consumer Offset表示当前的消费位置(针对普通消息的情况),Kafka Lag = HW - Consumer Offset,即:Kafka Lag计算方式不受影响(即使引入事务消息)。在read_committed隔离级别下,如果引入事务消息,Kafka Lag计算需要引入LSO来进行计算。如图所示:

图中:对于未完成的事务,LSO的值等于事务中第一条消息的位置(即:firstUnstableOffset),对于已完成的事务,LSO的值与HW相同,因此,LSO<=HW<=LEO。如下图所示:

图中:在read_committed隔离级别下,Kafka Lag = LSO - Consumer Offset。注:ControlBatch为控制消息,控制消息一共有两种类型:COMMIT和ABORT,分别用来表示事务已经成功提交或已经被成功终止。KafkaConsumer可以通过控制消息来判断对应的事务已提交或已中止,再结合参数isolation.level配置的隔离级别来决定是否将相应的消息返回给消费端。
事务恢复保证
为了实现有状态的应用也可以保证重启后从断点处继续处理(即:事务恢复)。应用程序必须提供一个稳定的(重启后不变)唯一的ID(即:Transaction ID)。Transactin ID与PID可能一一对应。区别在于Transaction ID由用户提供,而PID是内部的实现对用户透明。
另外,为了保证新的生产者启动后,旧的具有相同Transaction ID的生产者失效,生产者通过Transaction ID拿到PID的同时,还会获取一个单调递增的epoch。由于旧的生产者的epoch比新生产者的epoch小,Broker会拒绝其请求。
有了Transaction ID和epoch后,Kafka可保证:
- 跨Session的数据幂等发送。当具有相同Transaction ID的新的生产者实例被创建且工作时,旧的且拥有相同Transaction ID的生产者将不再工作。
- 跨Session的事务恢复。如果某个应用实例宕机,新的实例可以保证任何未完成的旧的事务要么Commit要么Abort,使得新实例从一个正常状态开始工作。
事务原子性保证
事务原子性是指生产者将多条消息作为一个事务批量发送,要么全部成功要么全部失败。 引入了一个服务器端的模块,名为Transaction Coordinator,用于管理生产者发送的消息的事务性。
该Transaction Coordinator维护Transaction Log,该Log存于一个内部的Topic内(__transaction_state(默认分区数:50))。由于Topic数据具有持久性,因此事务的状态也具有持久性。
生产者并不直接读写Transaction Log,它与Transaction Coordinator通信,然后由Transaction Coordinator将该事务的状态插入相应的Transaction Log。
Transaction Log的设计与Offset Log用于保存Consumer的Offset类似。
事务中Offset提交保证
在Kafka Stream应用中同时包含Consumer和Producer(即Consumer-Transform-Producer),前者负责从Kafka中获取消息,后者负责将处理完的数据写回Kafka的其它Topic中。
为了实现该场景下的事务原子性,Kafka需要保证对Consumer Offset的Commit与Producer对发送消息的Commit包含在同一个事务中。否则,如果在二者Commit中间发生异常,根据二者Commit的顺序可能会造成数据丢失和数据重复:
- 如果先Commit Producer发送数据的事务,再Commit Consumer的Offset,即:At Least Once语义,可能造成数据重复。
- 如果先Commit Consumer的Offset,再Commit Producer数据发送事务,即At Most Once语义,可能造成数据丢失。
拒绝僵尸实例(Zombie fencing)
在分布式系统中,一个实例宕机或失联,集群会启动一个新的实例来代替该实例。此时若旧实例恢复,集群中就会存在两个相同的实例(即:TransactionID和PID相同的实例),此时旧实例就被称为“僵尸实例”。
在Kafka中,两个相同的生产者实例同时处理消息并生产重复消息,这就是僵尸实例问题。
Kafka事务特性通过TransactionID属性来解决僵尸实例问题。所有具有相同TransactionID的生产者会分配相同的PID,同时,每个生产者还会分配一个递增的epoch(纪元)。Broker收到事务提交请求时,如果检查当前事务提交者的epoch不是最新值,就会拒绝该生产者的请求,从而达成拒绝僵尸实例的目标。
用于事务特性的控制型消息
为了区分写入Partition的消息被Commit还是Abort,Kafka引入了一种特殊类型的消息(即:Control Message)。该类消息的Value内不包含任何应用相关的数据,并且不会暴露给应用程序。它只用于Broker与Client间的内部通信。
对于Producer端事务,Kafka以Control Message的形式引入一系列的Transaction Marker。Consumer即可通过该标记判定对应的消息被Commit了还是Abort了,然后结合该Consumer配置的隔离级别决定是否应该将该消息返回给应用程序。
注意:文章来源:https://www.toymoban.com/news/detail-858049.html
Kafka事务的回滚,并不是删除已写入的数据,而是将写入数据的事务标记为Rollback/Abort,从而在读数据时过滤该数据。文章来源地址https://www.toymoban.com/news/detail-858049.html
到了这里,关于Kafka核心原理之精准一次性投递的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!