实验2:VGG图像分类
一:实验目的与要求
1:掌握VGG网络的原理与结构。
2:学会利用VGG网络建立训练模型,并对模型进行评估。
3:学会使用VGG网络进行分类。
二:实验内容
1:用VGG网络对自选图像数据集进行多分类预测。
2:应用图像增强方法进行数据集的扩充。
3:调整VGG网络参数(如:batch_size、激活函数、优化器、学习率、训练epoch等),比较结果差异。
三:实验环境
本实验所使用的环境条件如下表所示。
| 操作系统 |
Ubuntu(Linux) |
| 程序语言 |
Python(3.11.4) |
| 第三方依赖 |
torch, torchvision, matplotlib |
四:方法原理
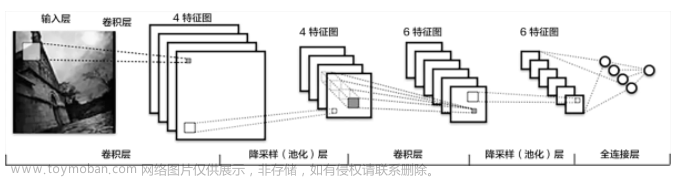
VGG是一种针对网络加深的CNN结构,其主要思想是通过重复使用简单的基础块来构建深度学习模型。
VGG系列的经典网络有VGG16和VGG19。VGG共有6种配置,分别为A、A-LRN、B、C、D、E。其中,D类对应VGG16,E类对应VGG19。
各类VGG都由5个卷积块和3个全连接层组成。第一个卷积块的每个卷积层共有64个输出通道,第二个卷积块的每个卷积层共有128个输出通道,第三个卷积块的每个卷积层共有256个输出通道,第四个卷积块的每个卷积层共有512个输出通道,第五个卷积块的每个卷积层共有512个输出通道。
各类VGG的卷积计算示意图如下图所示。

五、方法流程
本实验方法设计的流程如下:
- 下载公开数据集(https://aistudio.baidu.com/datasetdetail/171121),分析数据集的特点,并分别选择其中的苹果的病虫害图像数据集作为后续训练和测试的数据集,样本量为4000张。
- 配置容器的运行环境,并将数据集通过远程连接协议传入容器。
- 按照【数据集读取】——【数据集划分】——【模型实例化】——【损失函数和优化器选择】——【迭代训练模型】——【训练结果可视化】的步骤撰写代码。
- 得到基本框架的训练结果,分析结果产生的原因。
- 改变VGG网络的参数,例如batch_size、激活函数、优化器、学习率、训练epoch等,多次重复实验。
- 分析对比实验的结果,总结VGG网络的特点。
六、实验展示(训练过程和训练部分结果进行可视化)
1:VGG16的baseline训练
在VGG16的baseline训练中,各个基本参数的内容如下表所示。
| 基本参数 |
参数值 |
| Batch_size |
32 |
| 激活函数 |
ReLU |
| 优化器 |
Adam |
| 学习率 |
0.001 |
| 训练epoch |
30 |
基于VGG16进行初步训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,在VGG16的baseline中,训练集上的分类准确率最高可达99.25%,测试集上的分类准确率最高可达97.63%。
2:VGG19的baseline训练
在VGG19的baseline训练中,各个基本参数的内容如下表所示。
| 基本参数 |
参数值 |
| Batch_size |
32 |
| 激活函数 |
ReLU |
| 优化器 |
Adam |
| 学习率 |
0.001 |
| 训练epoch |
30 |
基于VGG19进行初步训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,在VGG19的baseline中,训练集上的分类准确率最高可达100.0%,测试集上的分类准确率最高可达98.39%。
对比第1部分的【VGG16】训练内容,VGG19在该数据集上的表现更佳,因此后续将选择VGG19进行参数调整的对比实验训练。
3:修改batch_size的对比实验(基于VGG19)
在深度学习中,batch_size(批大小)是指在训练神经网络时每次迭代所使用的样本数量。
常见的batch_size大小通常在以下范围内:
- 小批量(Small Batch):通常在2到64之间。
- 中等批量(Medium Batch):通常在64到256之间。
- 大批量(Large Batch):通常在256以上。
由于baseline中已经获得了batch_size=32的小批量训练结果,因此后续将采用batch_size=128获得中等批量的训练结果。
修改batch_size为【128】后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,修改batch_size为【128】后,训练集上的分类准确率最高可达98.86%,测试集上的分类准确率最高可达97.52%。与baseline相比,batch_size为【128】时的分类损失值和准确率出现了较大的波动,同时最高的测试准确率也比baseline低。因此,中等批量的训练结果比小批量的训练结果差。
4:修改激活函数的对比实验(基于VGG19)
VGG模型主要由两大部分组成:特征提取部分(features)和分类部分(classifier)。如果要修改预训练的VGG16模型中的激活函数,则需要直接访问并修改模型中包含激活函数的层,并替换激活函数类型。在本节实验中,激活函数从ReLU替换为LeakyReLU。
修改激活函数为【LeakyReLU】后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,修改激活函数为【LeakyReLU】后,训练集上的分类准确率最高可达99.30%,测试集上的分类准确率最高可达98.28%。与baseline相比,激活函数为【LeakyReLU】时最高的训练准确率和测试准确率均比baseline低。因此,LeakyReLU的训练结果比ReLU的训练结果差。
5:修改优化器的对比实验(基于VGG19)
修改优化器为【SGD】后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。
在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。
综上所述,修改优化器为【SGD】后,训练集上的分类准确率最高可达100.0%,测试集上的分类准确率最高可达100.0%。与baseline相比,优化器为【SGD】时最高的训练准确率和测试准确率均比baseline高。因此,SGD的训练结果比Adam的训练结果好。
6:修改学习率的对比实验(基于VGG19)
【学习率增大】
修改学习率为【0.01】后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,修改学习率为【0.01】后,训练集上的分类准确率最高可达34.45%,测试集上的分类准确率最高可达37.14%。与baseline相比,学习率为【0.01】时最高的训练准确率和测试准确率均比baseline低。因此,学习率为【0.01】的训练结果比学习率为【0.001】的训练结果差。
【学习率减小】
修改学习率为【0.0001】后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,修改学习率为【0.0001】后,训练集上的分类准确率最高可达100.0%,测试集上的分类准确率最高可达100.0%。与baseline相比,学习率为【0.0001】时最高的训练准确率和测试准确率均比baseline高。因此,学习率为【0.0001】的训练结果比学习率为【0.001】的训练结果好。
6:修改训练epoch的对比实验(基于VGG19)
【训练epoch减小】
修改训练epoch为【10】后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,修改训练epoch为【10】后,训练集上的分类准确率最高可达98.44%,测试集上的分类准确率最高可达96.88%。与baseline相比,训练epoch为【10】时最高的训练准确率和测试准确率均比baseline低。因此,训练epoch为【10】的训练结果比训练epoch为【30】的训练结果差。
【训练epoch增大】
修改训练epoch为【50】后进行训练的迭代过程如下图所示。


在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,修改训练epoch为【50】后,训练集上的分类准确率最高可达100.0%,测试集上的分类准确率最高可达98.92%。与baseline相比,训练epoch为【50】时最高的训练准确率和测试准确率均比baseline高。因此,训练epoch为【50】的训练结果比训练epoch为【30】的训练结果好。
7:数据增强的对比实验(基于VGG19)
数据增强需要在transform处进行修改,例如RandomRotation。同时由于数据增强只在训练集上使用而不在测试集上使用,因此需要将训练集数据和测试集数据分开加载。
本部分数据增强采用了【随机裁剪】的数据增强技术,代码修改如下。
| # 训练集的转换:包含数据增强 train_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.RandomCrop(224, padding=4), # 添加随机裁剪 transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # 测试集/验证集的转换:不包含数据增强 test_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) dataroot = "/home/ubuntu/apple" # 加载数据集时应用相应的转换 train_dataset_full = torchvision.datasets.ImageFolder(root=dataroot, transform=train_transform) test_dataset_full = torchvision.datasets.ImageFolder(root=dataroot, transform=test_transform) # 划分 train 和 test 数据集 train_size = int(0.8 * len(train_dataset_full)) test_size = len(train_dataset_full) - train_size # 这里使用相同的索引划分方法来确保训练集和测试集的一致性 train_indices = torch.arange(0, train_size) test_indices = torch.arange(train_size, train_size + test_size) train_dataset = torch.utils.data.Subset(train_dataset_full, train_indices) val_dataset = torch.utils.data.Subset(test_dataset_full, test_indices) # 创建数据加载器 train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4) dataset = test_dataset_full |
采用数据增强后进行训练的迭代过程如下图所示。

在训练集和测试集上的分类准确率如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

在训练集和测试集上的分类损失值如下图所示(橘色部分为测试集结果,蓝色部分为训练集结果)。

综上所述,采用数据增强后,训练集上的分类准确率最高可达99.92%,测试集上的分类准确率最高可达99.57%。与baseline相比,采用数据增强时最高的测试准确率均比baseline高。因此,采用数据增强后的训练结果比baseline的训练结果好。
七、实验结论
1:VGG整体具备层数多,后面层的感受野大,包含更多的全局信息。相比于AlexNet,VGG的模型参数更少。
2:VGG对卷积核和池化大小进行了统一,网络中进行 3×3的卷积操作和2×2
的最大池化操作。VGG主要采用卷积层堆叠的策略,即多个具有小卷积核的卷积层串联的方式。一方面能够减少网络参数,另一方面提高感受野范围,增强网络的学习能力和特征表达能力。同时,VGG在每层卷积之后进行ReLU(激活函数)的非线性操作。
3:在batch_size的分类中,主要包括小批量、中等批量和大批量。小批量适合于较小的数据集或计算资源有限的情况,可以提供较高的梯度更新频率,但可能会导致训练过程中的噪声较多;中等批量通常是在一般情况下的默认选择,适用于中等大小的数据集和计算资源;大批量通常用于具有大型数据集和强大计算资源的情况下,可以加快训练速度,但可能需要更多的内存。
4:合适的参数设置可以显著提高模型性能。调整模型参数需要通过多次尝试和错误来找到最优的参数组合。每个参数的调整都需要基于对模型工作原理的深入理解。
5:数据增强是提高图像分类模型泛化能力的有效方法。适当的数据增强不仅可以增加数据量,还可以引入多样性,帮助模型学习到更加鲁棒的特征。
八、遇到的问题和解决方法
问题1:一开始使用pytorch搭建的VGG16网络,在数据集上的分类准确率只有33%。
解决1:将模型实例化改为torch集成的VGG模型,修改后的分类准确率可超过90%。
问题2:在batch_size=256的训练过程中,出现以下报错。

解决2:上述报错的原因是batch_size设置过大导致内存不足,需要降低batch_size,因此本实验无法训练大批量(batch_size>=256)的结果。
九、程序源代码
| import torch import torchvision import torchvision.transforms as transforms from torchvision import models import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, random_split import torch.nn.functional as F import matplotlib.pyplot as plt # visualization part def plot_loss(train_losses, val_losses): plt.figure(figsize=(10, 5)) plt.plot(train_losses, label='Training Loss') plt.plot(val_losses, label='Validation Loss') plt.xlabel('Epoch') plt.ylabel('Loss') plt.title('Training and Validation Loss') plt.legend() # plt.show() plt.savefig('loss-vgg.png') def plot_accuracy(train_accuracies, val_accuracies): plt.figure(figsize=(10, 5)) plt.plot(train_accuracies, label='Training Accuracy') plt.plot(val_accuracies, label='Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.title('Training and Validation Accuracy') plt.legend() # plt.show() plt.savefig('acc-vgg.png') # Data Preparation transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) dataroot = r"/home/ubuntu/apple" dataset = torchvision.datasets.ImageFolder(root=dataroot, transform=transform) # 划分 train 和 test 数据集 train_size = int(0.8 * len(dataset)) test_size = len(dataset) - train_size train_dataset, val_dataset = random_split(dataset, [train_size, test_size]) # 创建数据加载器 train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4) # 实例化模型 # model = VGG16(num_classes=6) model = models.vgg16(pretrained=True) # 修改分类器部分 model.classifier = nn.Sequential( nn.Flatten(), nn.LayerNorm(25088), nn.Linear(25088, len(dataset.classes)) ) # Training and Evaluation device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) criterion = nn.CrossEntropyLoss() # optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) optimizer = torch.optim.Adam(model.parameters(), lr=0.001) for i, layer in enumerate(model.features): if isinstance(layer, nn.ReLU): model.features[i] = nn.LeakyReLU(negative_slope=0.01) for i, layer in enumerate(model.classifier): if isinstance(layer, nn.ReLU): model.classifier[i] = nn.LeakyReLU(negative_slope=0.01) # Training loop num_epochs = 30 train_losses = [] val_losses = [] train_accuracies = [] val_accuracies = [] for epoch in range(num_epochs): # train model.train() running_loss = 0.0 correct = 0 total = 0 test_correct = 0 test_total = 0
for i, (inputs, labels) in enumerate(train_loader): inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step()
running_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()
train_losses.append(running_loss / len(train_loader)) train_accuracies.append(100 * correct / total)
# evaluate model.eval() with torch.no_grad(): val_loss = 0.0 val_correct = 0 val_total = 0 for inputs, labels in val_loader: inputs, labels = inputs.to(device), labels.to(device) outputs = model(inputs) loss = criterion(outputs, labels) val_loss += loss.item() _, predicted = torch.max(outputs.data, 1) val_total += labels.size(0) val_correct += (predicted == labels).sum().item()
val_losses.append(val_loss / len(val_loader)) val_accuracies.append(100 * val_correct / val_total)
print(f"Epoch {epoch+1}, Loss: {train_losses[-1]}, Accuracy: {train_accuracies[-1]}%, Validation Loss: {val_losses[-1]}, Validation Accuracy: {val_accuracies[-1]}%") # 绘制损失曲线和准确率曲线 plot_loss(train_losses, val_losses) plot_accuracy(train_accuracies, val_accuracies)文章来源:https://www.toymoban.com/news/detail-858204.html print('Finished')文章来源地址https://www.toymoban.com/news/detail-858204.html |
到了这里,关于【人工智能Ⅱ】实验2:VGG图像分类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!