可以看到有标题,类型,姓名,以及热度,我们爬取这四个字段就行
然后滑到底部,这里的下一页是我们控制爬取页数的
注意:当我们进入页面时,虽然有滚动条,但所有直播信息已经加载好,并不是通过滑动然后Ajax加载的,所以在代码中并不需要写滑动,直接提取就可以拿到整个页面的数据。
1.解析数据的函数
#解析数据的函数
def parse(self):
#强制等待两秒,等待页面数据加载完毕
sleep(2)
li_list = self.bro.find_elements_by_xpath(‘//*[@id=“listAll”]/section[2]/div[2]/ul/li’)
#print(len(li_list))
data_list = []
for li in li_list:
dic_data = {}
dic_data[‘title’] = li.find_element_by_xpath(‘./div/a/div[2]/div[1]/h3’).text
dic_data[‘name’] = li.find_element_by_xpath(‘./div/a/div[2]/div[2]/h2/div’).text
dic_data[‘art_type’] = li.find_element_by_xpath(‘./div/a/div[2]/div[1]/span’).text
dic_data[‘hot’] = li.find_element_by_xpath(‘./div/a/div[2]/div[2]/span’).text
data_list.append(dic_data)
return data_list
2.保存数据的函数
(1)保存为txt文本
#保存数据的函数
def save_data(self,data_list,i):
#在当前目录下将数据存为txt文件
with open(‘./douyu.txt’,‘w’,encoding=‘utf-8’) as fp:
for data in data_list:
data = str(data)
fp.write(data+‘\n’)
print(“第%d页保存完成!” % i)
(2)保存为json文件
#保存数据的函数
def save_data(self,data_list,i):
with open(‘./douyu.json’,‘w’,encoding=‘utf-8’) as fp:
#里面有中文,所以注意ensure_ascii=False
data = json.dumps(data_list,ensure_ascii=False)
fp.write(data)
print(“第%d页保存完成!” % i)
3.主函数设计
#主函数
def run(self):
#输入要爬取的页数,如果输入负整数,转化成她的绝对值
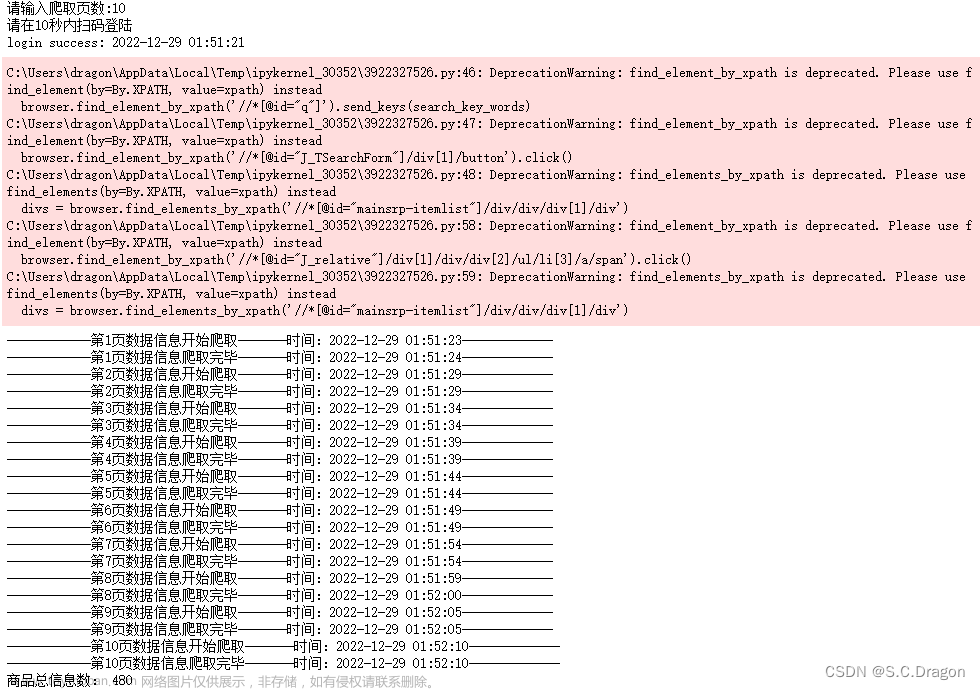
page_num = abs(int(input(“请输入你要爬取的页数:”)))
#初始化页数为1
i = 1
#判断输入的数是否为整数
if isinstance(page_num,int):
#实例化浏览器对象
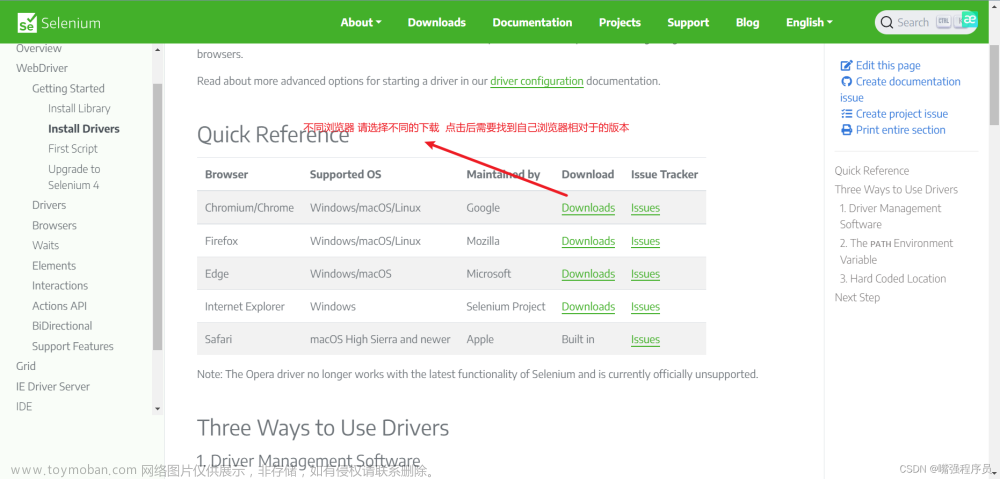
self.bro = webdriver.Chrome(executable_path=‘…/…/可执行文件/chromedriver.exe’)
chromedriver.exe如果已添加到环境变量,可省略executable_path=‘…/…/可执行文件/chromedriver.exe’
self.bro.get(self.url)
while i <= page_num:
#调用解析函数
data_list = self.parse()
#调用保存函数
self.save_data(data_list,i)
try:
#定位包含“下一页”字段的按钮并点击
button = self.bro.find_element_by_xpath(‘//span[contains(text(),“下一页”)]’)
button.click()
i += 1
except:
break
self.bro.quit()
else:
print(“输入格式错误!”)
四、完整代码
======
from selenium import webdriver
from time import sleep
import json
#创建一个类
class Douyu():
def init(self):
self.url = ‘https://www.douyu.com/directory/all’
#解析数据的函数
def parse(self):
#强制等待两秒,等待页面数据加载完毕
sleep(2)
li_list = self.bro.find_elements_by_xpath(‘//*[@id=“listAll”]/section[2]/div[2]/ul/li’)
#print(len(li_list))
data_list = []
for li in li_list:
dic_data = {}
dic_data[‘title’] = li.find_element_by_xpath(‘./div/a/div[2]/div[1]/h3’).text
dic_data[‘name’] = li.find_element_by_xpath(‘./div/a/div[2]/div[2]/h2/div’).text
dic_data[‘art_type’] = li.find_element_by_xpath(‘./div/a/div[2]/div[1]/span’).text
dic_data[‘hot’] = li.find_element_by_xpath(‘./div/a/div[2]/div[2]/span’).text
data_list.append(dic_data)
return data_list
#保存数据的函数
def save_data(self,data_list,i):
#在当前目录下将数据存为txt文件
with open(‘./douyu.txt’,‘w’,encoding=‘utf-8’) as fp:
for data in data_list:
data = str(data)
fp.write(data+‘\n’)
print(“第%d页保存完成!” % i)
json文件的存法
with open(‘./douyu.json’,‘w’,encoding=‘utf-8’) as fp:
里面有中文,所以注意ensure_ascii=False
data = json.dumps(data_list,ensure_ascii=False)
fp.write(data)
print(“第%d页保存完成!” % i)
#主函数
def run(self):
#输入要爬取的页数,如果输入负整数,转化成她的绝对值
page_num = abs(int(input(“请输入你要爬取的页数:”)))
#初始化页数为1
i = 1
#判断输入的数是否为整数
if isinstance(page_num,int):
#实例化浏览器对象
self.bro = webdriver.Chrome(executable_path=‘…/…/可执行文件/chromedriver.exe’)
chromedriver.exe如果已添加到环境变量,可省略executable_path=‘…/…/可执行文件/chromedriver.exe’
self.bro.get(self.url)
while i <= page_num:
#调用解析函数
data_list = self.parse()
#调用保存函数
self.save_data(data_list,i)
try:
#定位包含“下一页”字段的按钮并点击
button = self.bro.find_element_by_xpath(‘//span[contains(text(),“下一页”)]’)
button.click()
i += 1
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数前端工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!

由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:前端)

结尾
正式学习前端大概 3 年多了,很早就想整理这个书单了,因为常常会有朋友问,前端该如何学习,学习前端该看哪些书,我就讲讲我学习的道路中看的一些书,虽然整理的书不多,但是每一本都是那种看一本就秒不绝口的感觉。
以下大部分是我看过的,或者说身边的人推荐的书籍,每一本我都有些相关的推荐语,如果你有看到更好的书欢迎推荐呀。
戳这里免费领取前端学习资料文章来源:https://www.toymoban.com/news/detail-858265.html
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:前端)
结尾
正式学习前端大概 3 年多了,很早就想整理这个书单了,因为常常会有朋友问,前端该如何学习,学习前端该看哪些书,我就讲讲我学习的道路中看的一些书,虽然整理的书不多,但是每一本都是那种看一本就秒不绝口的感觉。
以下大部分是我看过的,或者说身边的人推荐的书籍,每一本我都有些相关的推荐语,如果你有看到更好的书欢迎推荐呀。
戳这里免费领取前端学习资料
 文章来源地址https://www.toymoban.com/news/detail-858265.html
文章来源地址https://www.toymoban.com/news/detail-858265.html
到了这里,关于用selenium爬取直播信息(1),JavaScript中的innerHTML、value属性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!