目录
1.原理
扩散模型的目的是什么?
扩散模型是怎么做的?
前向过程在干啥?
反向过程在干啥?
2.安装环境
3.lora 训练
4.推理
5.源代码
noise_scheduler:
tokenizer:
textModel:
vae:
unet:
每次train的过程:
代码:https://github.com/huggingface/diffusers/tree/main/examples/text_to_image
2006.11239.pdf (arxiv.org)论文 2006.11239.pdf (arxiv.org)
1.原理
找到一个科普不错的
https://www.bilibili.com/video/BV1tz4y1h7q1/?spm_id_from=333.337.search-card.all.click&vd_source=3aec03706e264c240796359c1c4d7ddc
简述一下:扩散模型分为两个部分,前向过程,根据timestep添加噪声,每一次从高斯噪声中采样然后添加到图像里面,这个采样的噪声就是GT。反向过程就是去噪,使用神经网络unet去预测噪声从而实现去噪。
扩散模型的目的是什么?
学习从纯噪声生成图片的方法
扩散模型是怎么做的?
训练一个U-Net,接受一系列加了噪声的图片,学习预测所加的噪声(纯噪声图-噪声=生成图)
前向过程在干啥?
逐步向真实图片添加噪声最终得到一个纯噪声
对于训练集中的每张图片,都能生成一系列的噪声程度不同的加噪图片
在训练时,这些 【不同程度的噪声图片 + 生成它们所用的噪声】 是实际的训练样本
反向过程在干啥?
训练好模型后,采样、生成图片

前向过程:


 对于x2,把x1的公式带入到x2就可以消除x1,以此类推,最后得到Xt和X0的关系式:
对于x2,把x1的公式带入到x2就可以消除x1,以此类推,最后得到Xt和X0的关系式:

多次噪声的累加(即他们的均值和方差分别相加)可以等价于一个噪声,最后Xt和时间t,参数a,噪声theta,X0有关。
反向过程:
在扩散模型的训练过程中,pipeline首先产生一个与输入图片同尺寸的噪声图,在每个时间步(timestep),将噪声图传给model来预测噪声残差(noise residual),然后scheduler根据预测出的噪声残差来得到一张噪声较少的图像,如此反复,直到达到预设的最大时间步,就得到了一张高质量的生成图像。利用了贝叶斯公式:
目标:在Xt噪声发生的条件下求解Xt-1 P(Xt-1|Xt)以至于到X0(从结果反推过程事件的发生概率)
等价于 p(xt|xt-1)在xt-1发生的条件下xt的概率 * p(xt-1) / p(xt):

推到X0


把高斯分布的公式带入

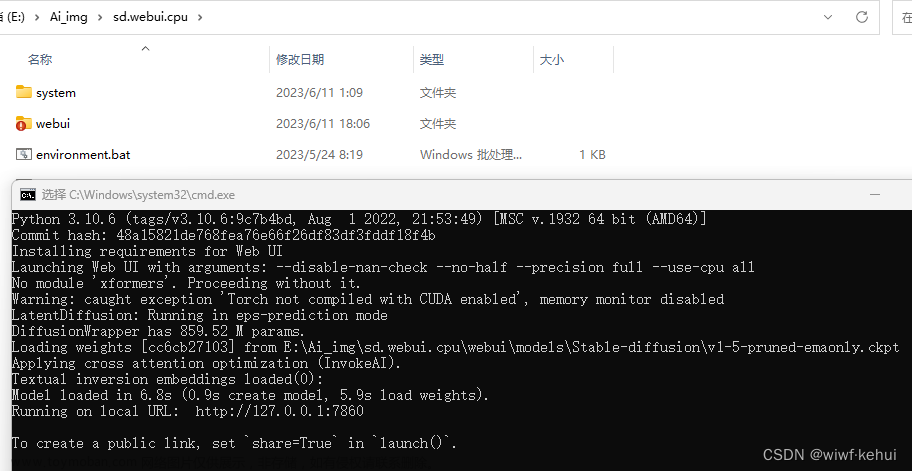
2.安装环境
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
cd example/text_to_image
pip install -r requirements.txt3.lora 训练
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=512 --random_flip \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb"报错:ValueErrorValueError: : Attempting to unscale FP16 gradients.Attempting to unscale FP16 gradients.
参考:https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/310
把--mixed_precision="fp16" 去掉
比较合理的解释

成功train:


4.推理
只train了100步,跑通流程,学习才是重点。
from diffusers import StableDiffusionPipeline
import torch
model_path = "./sd-model-finetuned-lora"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with green head and white legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
5.源代码
noise_scheduler:
Diffusion里的scheduler是一个采样器(samplers),用于把噪声图像还原为原始图像,它的功能是实现逆向扩散。注意:我们把去噪的过程定义为采样。使用采样的方法,称之为采样器。各种有关schedulers的代码在diffusers库 diffusers/src/diffusers/schedulers/中可以找到。
https://zhuanlan.zhihu.com/p/674001640
调度器定义了迭代地向图像添加噪声或基于模型输出更新样本的方法。
以不同方式添加噪声代表了通过向图像添加噪声来训练扩散模型的算法过程。
对于推断(inference),调度器定义了如何基于预训练模型的输出更新样本。
调度器通常由噪声计划(noise schedule)和更新规则(update rule)来解决微分方程问题的解。







def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.IntTensor,
) -> torch.FloatTensor:
self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5 # # 取出该时刻t的a值
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
# 加噪 (1-B)^1/2 * x + B^1/2 * 噪声
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
def step(
self,
model_output: torch.FloatTensor,
timestep: int,
sample: torch.FloatTensor,
generator=None,
return_dict: bool = True,
) -> Union[DDPMSchedulerOutput, Tuple]:
"""
去噪过程的计算
本质上:图像t - 预测的时刻t的噪声 = 图像t-1
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
"""
t = timestep
prev_t = self.previous_timestep(t)
if model_output.shape[1] == sample.shape[1] * 2 and self.variance_type in ["learned", "learned_range"]:
model_output, predicted_variance = torch.split(model_output, sample.shape[1], dim=1)
else:
predicted_variance = None
# 1. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[t]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
current_alpha_t = alpha_prod_t / alpha_prod_t_prev
current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
pred_original_sample = model_output
elif self.config.prediction_type == "v_prediction":
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample` or"
" `v_prediction` for the DDPMScheduler."
)
# 3. Clip or threshold "predicted x_0"
if self.config.thresholding:
pred_original_sample = self._threshold_sample(pred_original_sample)
elif self.config.clip_sample:
pred_original_sample = pred_original_sample.clamp(
-self.config.clip_sample_range, self.config.clip_sample_range
)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
variance = 0
if t > 0:
device = model_output.device
variance_noise = randn_tensor(
model_output.shape, generator=generator, device=device, dtype=model_output.dtype
)
if self.variance_type == "fixed_small_log":
variance = self._get_variance(t, predicted_variance=predicted_variance) * variance_noise
elif self.variance_type == "learned_range":
variance = self._get_variance(t, predicted_variance=predicted_variance)
variance = torch.exp(0.5 * variance) * variance_noise
else:
variance = (self._get_variance(t, predicted_variance=predicted_variance) ** 0.5) * variance_noise
pred_prev_sample = pred_prev_sample + variance
if not return_dict:
return (pred_prev_sample,)
return DDPMSchedulerOutput(prev_sample=pred_prev_sample, pred_original_sample=pred_original_sample)tokenizer:
把文本-->数字token,计算机只认识数字




textModel:
对文本token进行特征编码



vae:
把图像从pixel空间编码mapping到latent 空间,数据压缩






 Encoder = 4* resnet block下采样encoder + mid(attention + resnet)
Encoder = 4* resnet block下采样encoder + mid(attention + resnet)

Encoder = 4* resnet下采样encoder + mid(attention + resnet)
Decoder = 4* 上采样resnet block + mid(attention + resnet block)
VAE = encoder + decoder
unet:
图像的特征编码





上图是lora的参数量和原始的参数量文章来源:https://www.toymoban.com/news/detail-858276.html
Unet = Resnet block + Attention + lora (linear)文章来源地址https://www.toymoban.com/news/detail-858276.html
每次train的过程:
# 1.图像encoder 到latent空间
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor # bs,3,512,512-->bs,4,64,64
# 2.采样噪声
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# 3.采样随机时间步长
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long() # 【0,1000】中随机的一个值
# 3.前向过程:加噪
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps) # bs,4,64,64
# 5.文本encoder(条件condition)
encoder_hidden_states = text_encoder(batch["input_ids"], return_dict=False)[0]
# 6.获取gt--noise
target = noise
# 7.unet预测噪声,添加文本encoder作为条件
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states, return_dict=False)[0]
# 8.计算loss
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")到了这里,关于huggingface的diffusers训练stable diffusion记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!