目录
一、hash函数的定义:
二、hash函数的工作方式:
三、hash函数的优缺点:
四、hash函数的常见应用场景:
1、hash函数:
1-1、Python:
1-2、VBA:
2、推荐阅读:
个人主页:https://blog.csdn.net/ygb_1024?spm=1010.2135.3001.5421

一、hash函数的定义:
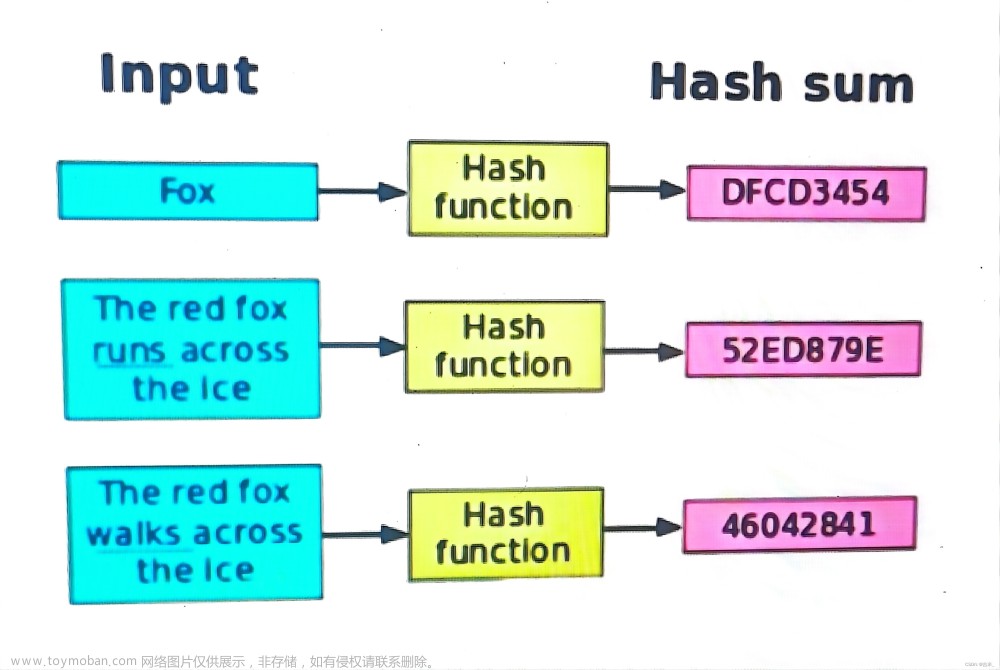
哈希函数(Hash Function)是一种将任意长度的数据(如字符串或数字)映射为固定长度数值(通常为较小的整数)的函数。这个固定长度的数值被称为哈希值或哈希码。哈希函数的主要特点是它能够将不同的输入映射到不同的哈希值,并且对于相同的输入,哈希函数应该总是产生相同的哈希值。
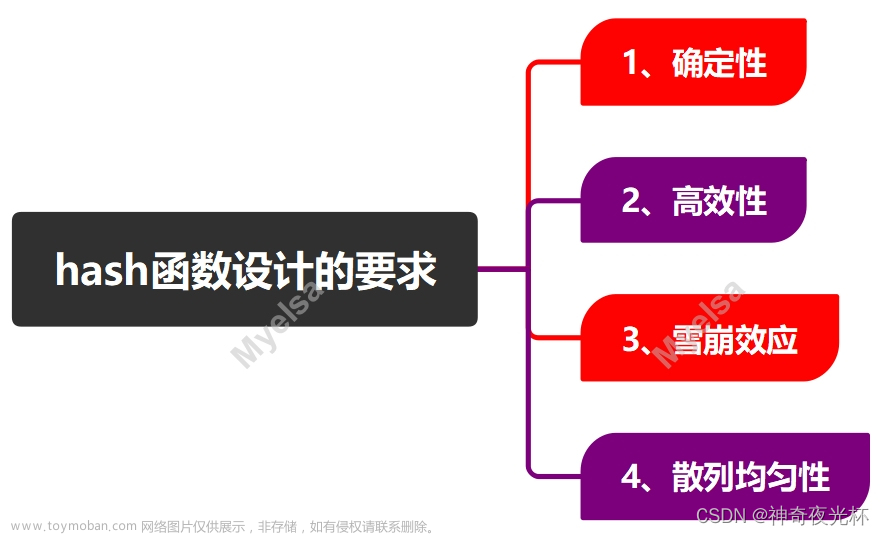
哈希函数的设计通常满足以下性质:
1、确定性:对于相同的输入,哈希函数总是产生相同的输出。
2、高效性:哈希函数的计算应该相对快速,以便在实际应用中能够高效地处理大量数据。
3、雪崩效应:哈希函数的输出对输入的微小变化应该非常敏感,即输入的小变化应该导致哈希值的大变化。这有助于减少哈希冲突的可能性。
4、散列均匀性:哈希函数的输出应该尽可能均匀地分布在输出空间中,以减少哈希冲突的概率。
哈希函数在多个领域有广泛应用,如数据查找(如哈希表)、数据完整性校验(如MD5或SHA-1用于文件校验和)、密码学(如加密哈希函数用于数字签名和消息认证)等。
注意,哈希函数不是加密算法,它们是单向的,即不能从哈希值反推出原始输入数据。此外,由于哈希函数的设计特点和固定长度的输出,哈希冲突(不同输入产生相同哈希值)是不可避免的,但好的哈希函数会尽量减少这种冲突的发生。
二、hash函数的工作方式:
哈希函数的工作方式可以概括为以下几个步骤:
1、接收输入:哈希函数首先接收一个输入,这个输入可以是任意长度的数据,比如一个字符串、一个数字、或者一组数据。
2、执行哈希算法:接下来,哈希函数会对输入数据进行一系列复杂的数学运算和转换。这些运算和转换通常包括位操作、模运算、加法、乘法等,具体的运算方式取决于哈希函数的设计和实现。这些运算的目的是将输入数据转换成一个固定长度的数值,即哈希值。
3、生成哈希值:经过哈希算法的处理后,哈希函数会输出一个固定长度的哈希值。这个哈希值通常是一个较小的整数,其长度是预先确定的,不会因为输入数据的长度变化而变化。
4、保证唯一性和确定性:哈希函数的设计需要满足一些关键特性,如确定性、散列均匀性和雪崩效应。确定性意味着对于相同的输入,哈希函数总是产生相同的输出;散列均匀性要求哈希值尽可能均匀地分布在整个输出空间中,以减少哈希冲突的可能性;雪崩效应则要求输入数据的微小变化能够导致哈希值的显著变化。
哈希函数的工作方式使得它能够在多个领域发挥重要作用。例如,在数据结构中,哈希函数可以将数据映射到哈希表的特定位置,从而实现快速的插入、查找和删除操作。在密码学中,哈希函数可以用于生成数据的唯一标识符,用于验证数据的完整性和未被篡改。此外,哈希函数还可以用于创建数字签名、实现消息认证等安全功能。
注意,哈希函数是单向的,即不能从哈希值反推出原始输入数据。这种单向性保证了哈希函数的安全性,使得它成为许多安全应用中的关键组件。

三、hash函数的优缺点:
哈希函数的优点和缺点主要体现在以下几个方面:
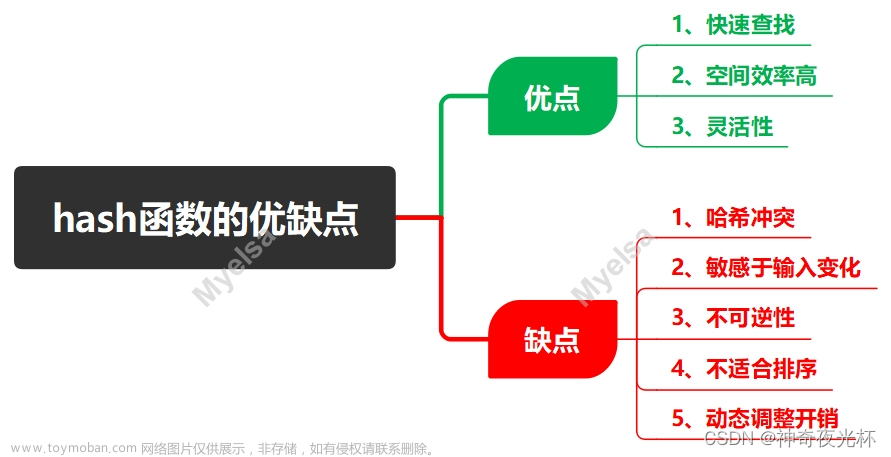
1、优点:
1-1、快速查找:哈希函数的主要优点是它们能够快速地定位到数据。通过将数据映射到唯一的哈希值,哈希函数允许我们以接近常量的时间复杂度(O(1))进行查找,这比线性搜索或二分搜索等算法要快得多。
1-2、空间效率高:哈希表通常能够以较小的空间存储大量的数据,因为哈希表不需要像数组那样预留连续的空间,也不需要像链表那样存储额外的指针。
1-3、灵活性:哈希函数可以用于各种类型的数据,不仅仅是数字或字符串。通过适当的哈希函数设计,我们可以为自定义的对象类型定义哈希值,从而将它们用作哈希表中的键。
2、缺点:
2-1、哈希冲突:虽然哈希函数设计得尽可能减少冲突,但冲突仍然可能发生。当两个不同的输入产生相同的哈希值时,就需要额外的机制(如链地址法或开放地址法)来处理这种冲突。这可能会增加查找和插入操作的复杂性。
2-2、敏感于输入变化:哈希函数对于输入的变化非常敏感。即使输入只有微小的变化,也可能导致哈希值发生很大的变化。这种敏感性在某些情况下是优点(如密码学哈希),但在其他情况下可能导致问题,因为相似的输入可能产生完全不同的哈希值。
2-3、不可逆性:哈希函数通常是单向的,即给定一个哈希值,很难(或不可能)找到原始输入。虽然这在某些场景下是优点(如密码存储),但在需要从哈希值恢复原始数据的场景下则成为缺点。
2-4、不适合排序:哈希表本身不保证元素的顺序,如果你需要按照某种顺序访问元素,那么哈希表可能不是最佳选择。
2-5、动态调整开销:当哈希表的大小需要动态调整(例如,当哈希表填满一定比例时)时,可能需要重新计算所有元素的哈希值并将它们移动到新的位置。这个过程可能会导致额外的开销。
注意,哈希函数的优点和缺点会因具体应用场景和需求而异。在选择使用哈希函数或哈希表时,需要根据实际情况进行权衡和选择。
四、hash函数的常见应用场景:
hash函数在Python中具有广泛的应用场景,主要是因为哈希表(如Python中的字典)的广泛使用以及哈希在算法和数据结构中的基础作用。常见的应用场景有:
1、字典的实现:字典是Python中非常重要的数据结构,它允许我们存储键值对。字典的底层实现通常依赖于哈希表。当向字典中添加一个键值对时,Python会使用hash()函数计算键的哈希值,并基于这个哈希值在哈希表中查找或存储该键值对,这种基于哈希值的查找方式使得字典的查找、插入和删除操作都非常快。
2、集合的实现:集合也是Python中的一种数据结构,用于存储唯一元素的集合。集合也使用哈希表来实现其底层存储,因此元素的哈希值对于集合的操作(如添加、删除、查找)至关重要。
3、数据去重与指纹生成:哈希函数可以用于生成数据的唯一指纹,这在数据去重、文件比较和版本控制等场景中非常有用。通过对数据进行哈希处理,可以生成一个固定长度的哈希值,用于标识数据的唯一性。当需要比较两个数据时,只需比较它们的哈希值即可,无需逐字节比较原始数据,从而提高了比较效率。
4、快速查找:在需要快速查找的场景中,可以使用哈希表。例如,如果你有一个大型的数据集,并且需要频繁地查找其中的元素,那么将数据集转换为一个哈希表(如字典或集合)可以大大提高查找速度。
5、缓存机制:在缓存系统中,哈希函数常用于将缓存键映射到缓存存储位置。这样,当需要查找缓存项时,可以直接使用哈希值来快速定位。
6、数据完整性校验:虽然Python的hash()函数主要用于内部的数据结构操作,但类似的哈希函数(如MD5、SHA系列)常用于数据完整性校验。通过计算数据的哈希值,并在数据传输或存储后重新计算哈希值进行比较,可以检测数据是否在传输或存储过程中被篡改。
7、分布式系统:在分布式系统中,哈希函数可以用于数据分区和负载均衡。通过将数据的键进行哈希,并根据哈希值将数据分配到不同的节点或服务器上,可以实现数据的分布式存储和处理。
8、密码学应用:在密码学中,哈希函数具有广泛的应用,如密码存储、数字签名和消息认证等。通过将密码或消息通过哈希函数转换为一个固定长度的哈希值,可以隐藏原始数据的具体内容,同时保留数据的唯一性。这使得哈希函数在保护用户密码安全、验证数据完整性和身份认证等方面发挥重要作用。
9、哈希表优化:在构建自定义哈希表或优化现有哈希表时,可以深入研究哈希函数的选择和冲突解决策略。通过设计更好的哈希函数(如减少冲突、均匀分布哈希值等),可以提高哈希表的性能。此外,还可以探索不同的冲突解决策略,如链地址法、开放地址法等。
10、布隆过滤器:布隆过滤器是一种空间效率极高的概率型数据结构,它利用位数组和哈希函数来快速判断一个元素是否存在于集合中。通过多个哈希函数将元素映射到位数组的不同位置,并将这些位置设置为1,从而实现了高效的插入和查询操作。虽然布隆过滤器可能会产生误报(即错误地认为元素存在于集合中),但其空间占用和查询效率的优势使得它在许多场景下非常有用。
11、自定义哈希函数:在某些特殊应用场景下,可能需要自定义哈希函数来满足特定需求。例如,在处理具有特定模式或结构的数据时,可以根据数据的特性设计哈希函数以提高哈希的均匀性和效率。通过继承Python的hash类并实现`__hash__()`方法,可以创建自定义的哈希函数。
注意,虽然哈希函数在某些场景下非常有用,但它们并不是安全的加密机制。哈希函数的设计目标是快速计算且冲突率低,而不是保证输出不可预测或防止逆向工程。因此,对于需要高度安全性的场景(如密码存储),应该使用专门的加密哈希函数(如bcrypt、Argon2等)。

1、hash函数:
1-1、Python:
# 1.函数:hash
# 2.功能:用于获取对象的哈希值
# 3.语法:hash(object)
# 4.参数:object,必须,一个不可变对象
# 5.返回值:返回对象的哈希值(若有的话)
# 6.说明:只有不可变对象,才有哈希值
# 7.示例:
# 应用1:字典的实现
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __hash__(self):
# 使用内置的hash函数对name和age进行哈希,并将结果组合起来
# 注意:为了避免哈希冲突,通常建议使用更复杂的方法,这里仅为示例
return hash((self.name, self.age))
def __eq__(self, other):
# 当两个Person对象具有相同的name和age时,它们被认为是相等的
if isinstance(other, Person):
return self.name == other.name and self.age == other.age
return False
# 创建Person对象并使用它们作为字典的键
people = {
Person("Myelsa", 18): "Myelsa's info",
Person("Jimmy", 15): "Jimmy's info"
}
# 根据Person对象获取字典中的值
alice = Person("Myelsa", 18)
print(people[alice])
# Myelsa's info
# 应用2:集合的实现
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __hash__(self):
# 使用内置的hash函数对name和age进行哈希,并将结果组合起来
# 注意:这里仅使用简单的元组哈希,实际中可能需要更复杂的哈希策略
return hash((self.name, self.age))
def __eq__(self, other):
# 当两个Person对象具有相同的name和age时,它们被认为是相等的
if isinstance(other, Person):
return self.name == other.name and self.age == other.age
return False
# 创建Person对象并使用它们作为集合的元素
people = {Person("Myelsa", 18), Person("Jimmy", 15)}
# 尝试添加一个已经存在的Person对象到集合中,它不会被添加(因为是重复的)
existing_person = Person("Myelsa", 18)
people.add(existing_person) # 这个操作实际上不会改变集合,因为Myelsa已经在里面了
# 打印集合中的元素数量,它应该仍然是2,因为Myelsa只被计算了一次
print(len(people))
# 检查一个Person对象是否在集合中
alice = Person("Myelsa", 18)
print(alice in people)
# 2
# True
# 应用3:数据去重与指纹生成
# 接受字符串信息,返回哈希值
import hashlib
def simple_hash(data: str) -> str:
"""
计算字符串的哈希值
"""
# 创建一个哈希对象
hasher = hashlib.sha256()
# 提供数据给哈希对象
hasher.update(data.encode('utf-8'))
# 获取十六进制哈希值
return hasher.hexdigest()
# 使用示例
data = "Hello, Python!"
hash_value = simple_hash(data)
print(f"Hash of '{data}': {hash_value}")
# Hash of 'Hello, Python!': 1c68755fc075a6bb08a82e80a5f1d3c8a8d40086a73cd8195ec7c43a7554f188
# 列表去重复项
def remove_duplicates_with_hash(data_list: list) -> list:
"""
使用哈希值去除列表中的重复项
"""
# 创建一个集合来存储唯一的哈希值
unique_hashes = set()
# 创建一个列表来存储去重后的数据
unique_data = []
for item in data_list:
hash_value = simple_hash(item)
# 如果哈希值不在集合中,说明这是唯一的项
if hash_value not in unique_hashes:
unique_hashes.add(hash_value)
unique_data.append(item)
return unique_data
# 使用示例
data_list = ["apple", "banana", "apple", "cherry", "banana"]
unique_data_list = remove_duplicates_with_hash(data_list)
print(f"Unique data list: {unique_data_list}")
# Unique data list: ['apple', 'banana', 'cherry']
# 应用4:快速查找
# 创建一个字典用于存储学生信息,学生ID作为键,学生姓名作为值
students = {
'1001': 'Myelsa',
'1002': 'Bruce',
'1003': 'Jimmy',
# ... 可以添加更多学生信息
}
# 定义一个函数用于通过学生ID查找学生姓名
def find_student_by_id(student_id, students_dict):
return students_dict.get(student_id)
# 示例:查找ID为1002的学生姓名
student_id = '1002'
student_name = find_student_by_id(student_id, students)
if student_name:
print(f"Student with ID {student_id} is {student_name}")
else:
print(f"No student found with ID {student_id}")
# 如果需要添加新的学生信息,可以直接对字典进行操作
new_student_id = '1004'
new_student_name = 'Mark'
students[new_student_id] = new_student_name
# 再次查找新添加的学生
student_name = find_student_by_id(new_student_id, students)
if student_name:
print(f"Newly added student with ID {new_student_id} is {student_name}")
# Student with ID 1002 is Bruce
# Newly added student with ID 1004 is Mark
# 应用5:缓存机制
import hashlib
# 缓存类,使用字典存储缓存数据
class Cache:
def __init__(self):
self.cache = {}
# 生成缓存键的哈希函数
def generate_cache_key(self, *args):
# 将参数转换为字符串,并使用哈希算法生成哈希值
key_str = '_'.join(str(arg) for arg in args)
hasher = hashlib.sha256()
hasher.update(key_str.encode('utf-8'))
return hasher.hexdigest()
# 缓存数据
def cache_data(self, key, value):
self.cache[key] = value
# 获取缓存数据
def get_cached_data(self, *args):
key = self.generate_cache_key(*args)
return self.cache.get(key)
# 使用示例
cache = Cache()
# 缓存一些数据
cache.cache_data(cache.generate_cache_key('key1'), 'value1')
cache.cache_data(cache.generate_cache_key('key2', 123), 'value2')
# 获取缓存数据
print(cache.get_cached_data('key1'))
print(cache.get_cached_data('key2', 123))
# 尝试获取不存在的缓存数据
print(cache.get_cached_data('nonexistent_key'))
# value1
# value2
# None
# 应用6:数据完整性校验
import hashlib
import os
# 定义一个函数来计算文件的哈希值
def calculate_file_hash(file_path, hash_algorithm='sha256'):
"""
计算文件的哈希值用于数据完整性校验
:param file_path: 文件的路径
:param hash_algorithm: 哈希算法的名称,默认为'sha256'
:return: 文件的哈希值
"""
# 创建一个哈希对象
hasher = hashlib.new(hash_algorithm)
# 打开文件并逐块读取数据,更新哈希对象
with open(file_path, 'rb') as file:
while True:
chunk = file.read(4096) # 读取4096字节的数据块
if not chunk:
break
hasher.update(chunk)
# 获取十六进制哈希值
return hasher.hexdigest()
# 使用示例
file_path = 'file.txt' # 替换为你的文件路径
file_hash = calculate_file_hash(file_path)
print(f"The hash of '{file_path}' is: {file_hash}")
# 你可以将这个哈希值保存下来,然后在需要校验的时候重新计算文件的哈希值,并进行比较
# 如果两个哈希值相同,那么数据就是完整的;如果不同,那么数据可能在传输或存储过程中被篡改
# The hash of 'file.txt' is: 0ffe1abd1a08215353c233d6e009613e95eec4253832a761af28ff37ac5a150c
# 应用7:分布式系统
import hashlib
# 假设我们有四个节点
NUM_NODES = 4
# 哈希函数,将键转换为0到NUM_NODES-1之间的数字
def hash_key_to_node(key):
# 使用md5哈希算法,将键转换为哈希值
m = hashlib.md5()
m.update(key.encode('utf-8'))
# 取哈希值的最后几位,并转换为整数
node_id = int(m.hexdigest(), 16) % NUM_NODES
return node_id
# 模拟一些数据键
keys = ['3', '5', '6', '8', '10', '11', '24']
# 分配数据到节点
node_assignments = {}
for key in keys:
node_id = hash_key_to_node(key)
if node_id not in node_assignments:
node_assignments[node_id] = []
node_assignments[node_id].append(key)
# 打印每个节点的数据分配情况
for node_id, keys_assigned in node_assignments.items():
print(f"Node {node_id}: {keys_assigned}")
# Node 3: ['3', '24']
# Node 1: ['5', '8']
# Node 0: ['6', '10']
# Node 2: ['11']
# 应用8:密码学应用
import hashlib
import os
# 哈希密码的函数
def hash_password(password, salt=None):
if salt is None:
salt = os.urandom(16) # 生成一个随机的盐值
# 将密码和盐值拼接起来
password_salt = password + salt.hex()
# 创建SHA-256哈希对象
hasher = hashlib.sha256()
# 更新哈希对象
hasher.update(password_salt.encode('utf-8'))
# 获取哈希摘要的十六进制表示
hashed_password = hasher.hexdigest()
# 返回哈希值和盐值,通常将它们一起存储
return hashed_password, salt
# 使用示例
password = 'my_secret_password'
hashed_pwd, salt = hash_password(password)
print(f"Hashed Password: {hashed_pwd}")
print(f"Salt: {salt.hex()}")
# 验证密码
def verify_password(provided_password, stored_hashed_password, stored_salt):
hashed_pwd, _ = hash_password(provided_password, stored_salt)
return hashed_pwd == stored_hashed_password
# 假设这是从数据库或其他存储中检索的存储哈希值和盐值
stored_hashed_password = hashed_pwd
stored_salt = salt
# 用户提供的密码进行验证
provided_password = input("Enter your password: ")
if verify_password(provided_password, stored_hashed_password, stored_salt):
print("Password is correct!")
else:
print("Password is incorrect!")
# Hashed Password: 0fa70b9fe5516f543e28ab8d97e1e38e04594b7fd74331a0a25723552e437f20
# Salt: 7301e12e361696eb7ae3272c05cb0569
# Enter your password: 123
# Password is incorrect!
# 应用9:哈希表优化
class HashTable:
def __init__(self, size):
self.size = size
self.table = [[] for _ in range(size)]
# 简单的哈希函数,使用取模运算
def hash_function(self, key):
return key % self.size
# 处理哈希冲突的方法:链地址法
def insert(self, key, value):
hash_key = self.hash_function(key)
bucket = self.table[hash_key]
for pair in bucket:
if pair[0] == key:
pair[1] = value # 更新值
return
bucket.append([key, value]) # 添加新键值对
def get(self, key):
hash_key = self.hash_function(key)
bucket = self.table[hash_key]
for pair in bucket:
if pair[0] == key:
return pair[1]
return None
# 使用示例
hash_table = HashTable(10)
hash_table.insert(1, 'apple')
hash_table.insert(11, 'banana')
hash_table.insert(21, 'cherry')
hash_table.insert(31, 'date')
hash_table.insert(41, 'elderberry')
print(hash_table.get(11))
print(hash_table.get(21))
# banana
# cherry
# 应用10:布隆过滤器
import mmh3
import bitarray
class BloomFilter:
def __init__(self, size, hash_count):
"""
初始化布隆过滤器
:param size: 位数组的大小
:param hash_count: 要使用的哈希函数数量
"""
self.size = size
self.hash_count = hash_count
self.bit_array = bitarray.bitarray(size)
self.bit_array.setall(0) # 初始化所有位为0
self.hashes = [self._get_hash_function(i) for i in range(hash_count)]
def _get_hash_function(self, seed):
"""
生成哈希函数,这里使用mmh3库的不同种子来模拟多个哈希函数
:param seed: 哈希函数的种子
:return: 哈希函数
"""
def hash_function(data):
return mmh3.hash(data, seed) % self.size
return hash_function
def add(self, item):
"""
向布隆过滤器中添加元素
:param item: 要添加的元素
"""
for hash_func in self.hashes:
index = hash_func(item)
self.bit_array[index] = 1
def might_contain(self, item):
"""
检查布隆过滤器是否可能包含某个元素
注意:这里只能返回“可能包含”,因为布隆过滤器存在误报的可能性
:param item: 要检查的元素
:return: 如果可能包含则返回True,否则返回False
"""
for hash_func in self.hashes:
index = hash_func(item)
if self.bit_array[index] == 0:
return False
return True
# 使用示例
if __name__ == "__main__":
# 创建一个大小为1000000,使用3个哈希函数的布隆过滤器
bf = BloomFilter(size=1000000, hash_count=3)
# 添加一些元素到布隆过滤器中
bf.add("apple")
bf.add("banana")
bf.add("cherry")
# 检查元素是否可能存在于布隆过滤器中
print(bf.might_contain("apple")) # 应该返回True
print(bf.might_contain("date")) # 可能返回True(误报),也可能返回False,取决于哈希碰撞情况
# True
# False
# 应用11:自定义哈希函数
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 自定义哈希函数
def __hash__(self):
# 使用元组的哈希值作为基础,因为元组是不可变的,并且有自己的哈希实现
return hash((self.name, self.age))
# 为了使对象可哈希,还需要定义 __eq__ 方法
def __eq__(self, other):
if not isinstance(other, Person):
return False
return self.name == other.name and self.age == other.age
# 创建Person对象
person1 = Person("Alice", 30)
person2 = Person("Bob", 25)
person3 = Person("Alice", 30) # 与person1相同
# 将对象添加到集合中,集合要求元素是可哈希的
people_set = {person1, person2}
# 检查person3是否“可能”在集合中
# 注意:由于哈希冲突的可能性,这只是一个快速的检查,不一定准确
# 要准确检查,还需要使用 __eq__ 方法进行比较
print(person3 in people_set) # 输出: True,因为person3和person1在内容上相等
# 使用字典,字典的键也必须是可哈希的
people_dict = {person1: "Office A", person2: "Office B"}
print(people_dict[person1]) # 输出: Office A
# True
# Office A1-2、VBA:
略,待后补。2、推荐阅读:
1、Python-VBA函数之旅-float()函数
Python算法之旅:Algorithm文章来源:https://www.toymoban.com/news/detail-858531.html
Python函数之旅:Functions 文章来源地址https://www.toymoban.com/news/detail-858531.html
个人主页:神奇夜光杯-CSDN博客
到了这里,关于Python-VBA函数之旅-hash函数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!