目录
前言
一、fsck命令
1、HDFS副本块数量的配置
2、fsck命令查看文件的副本数
3、block配置
二、NameNode元数据
1、edits文件
2、fsigame文件
3、NameNode元数据管理维护
4、元数据合并控制参数
5、SecondaryNameNode的作用
三、HDFS数据的读写流程
1、数据写入流程
2、数据读取流程
前言
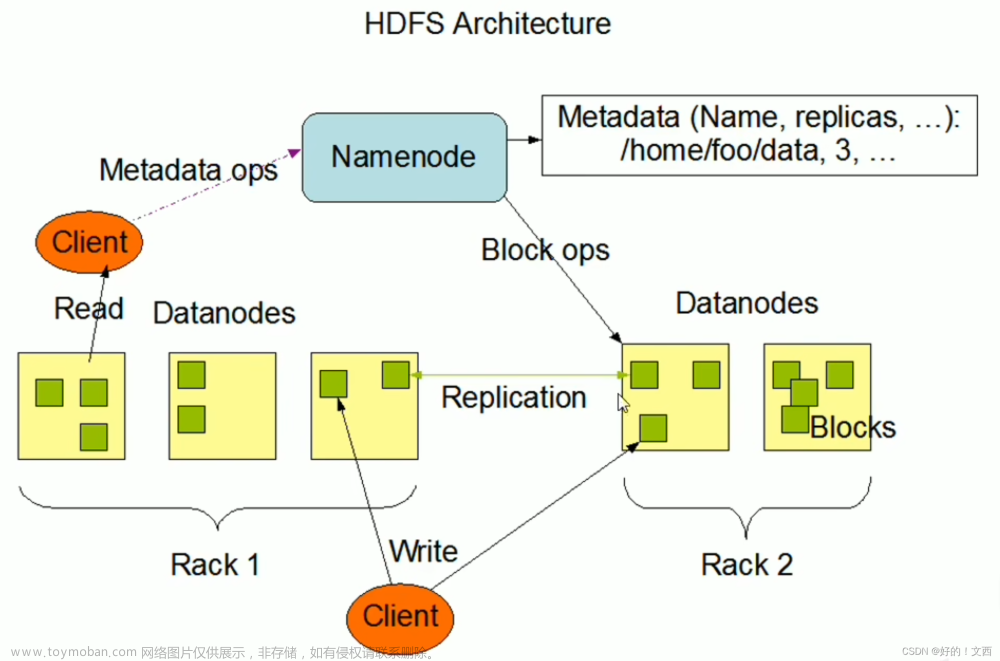
HDFS的存储原理是将大文件切分成固定大小的数据块,并在集群中的不同节点上存储数据块的副本,以提高数据的可靠性和性能。同时,HDFS采用流式的数据读写方式,减少了寻址的开销,提高了数据的传输效率。设定统一的管理单位,block块。Block块,HDFS最小存储单位,每个256MB(可以修改)
一、fsck命令
1、HDFS副本块数量的配置
HDFS文件系统的数据安全,是依靠多个副本来确保的。
如何设置默认文件上传到HDFS中拥有的副本数量呢?可以在hdfs-site.xml中配置如下属性:
<property>
<name>dis.replication</name>
<value>3</value>
</property>这个属性默认是3,一般情况下,我们无需主动配置(除非需要设置非3的数值)
如果需要自定义这个属性,请修改每一台服务器的hdfs-site.xml文件,并设置此属性。
- 除了配置文件之外,我们还可以在上传文件的时候,临时决定被上传文件以多少个副本存储。
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-1.png)
如上命令,就可以在上传test.txt的时候,临时设置其副本数为2.
- 对于已经存在HDFS的文件,修改dfs.replication属性不会修改,如果要修改已存在文件可以通过命令
hadoop fs -setrep [-R] 2 path
如上命令,指定path的内容将会被修改为2个副本存储。-R选项可选,使用-R表示对子目录也生效。
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-2.png)
2、fsck命令查看文件的副本数
我们可以使用hdfs提供的fsck命令来检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
- -files可以列出指定路径是否正常
- -files -block 输出文件块报告(有几个块,多少副本)
- -files -block -locations 输出每一个block的详情
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-3.png)
3、block配置
可以看到通过fsck命令我们验证了:
- 文件有多个副本
- 文件被分成多个块存储在hdfs
对于块(block),hdfs默认设置为256MB一个,也就是1GB文件会被划分为4个block存储。
块大小可以通过参数修改:
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>设置HDFS块大小,单位是b</description>
</property>如上,设置为256MB。
二、NameNode元数据
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护。
1、edits文件
edits文件,是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对于的block。edits记录每一次HDFS的操作,逐渐变得越来越大;所以会存在多个edits文件,确保不会有超大edits的存在,保证检索性能。
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-4.png)
2、fsigame文件
将全部的edits文件,合并为最终结果,即可得到一个fsimage文件、
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-5.png)
3、NameNode元数据管理维护
NameNode基于edits和fsimage的配合,完成整个文件系统文件的管理。
- 每次对HDFS的操作,均被edits文件记录
- edits达到大下上限后,开启新的edits记录
- 定期进行edits的合并操作
- 如当前没有fsimage文件,将全部edits合并为第一个fsimage
- 如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage。
- 重复123流程
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-6.png)
前边配置时已经将namenode的操作记录存放于/data/nn目录中。
4、元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
- dfs.namenode.checkpoint.period,默认3600(秒) 即一小时
- dfs.namenode.checkpoint.txns,默认1000000,即100w次事务
只要有一个达到条件就执行。
检查是否达到条件,默认60秒检查一次,基于:
- dfs.namenode.checkpoint.check.period,默认60(秒)
5、SecondaryNameNode的作用
对于元数据的合并,还记得HDFS集群有一个辅助角色:SecondaryNameNode。
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage),然后合并完成后提供给NameNode使用。
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-7.png)
三、HDFS数据的读写流程
1、数据写入流程
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-8.png)
- 客户端向NameNode发起请求
- NameNode审核权限,剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
- 客户端向指定的DataNode发送数据包
- 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其他DataNode
- 如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给DataNode3和DataNode4
- 写入完成客户端通知NameNode,NameNode做元数据记录工作
2、数据读取流程
![【Hadoop】-HDFS的存储原理[4],hadoop,hadoop,hdfs,大数据](https://imgs.yssmx.com/Uploads/2024/04/858768-9.png)
- 客户端向NameNode申请读取某文件
- NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
- 客户端拿到block列表后自行寻找DataNode读取即可
总结
1、对于客户端读取HDFS数据的流程中,一定要知道不论读,还是写,NameNode都不经手数据,均是客户端和DataNode直接通讯,不然对NameNode压力太大。
2、写入和读取的流程,简单来说就是:文章来源:https://www.toymoban.com/news/detail-858768.html
- NameNode做授权判断(是否能写、是否能读)
- 客户端直连DataNode写入、客户端直连DataNode进行block读取
- 写入,客户端会被分配找离自己最近的DataNode写数据
- 读取,客户端拿到的block列表,会是网络距离最近的一份
3、网络距离文章来源地址https://www.toymoban.com/news/detail-858768.html
- 最近的距离就是在同一台机器
- 其次就是同一个局域网(交换机)
- 再其次就是跨越交换机
- 再其次就是跨越数据中心
到了这里,关于【Hadoop】-HDFS的存储原理[4]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!