经常看到一些公众号万字长文分析 tcp 触发快速重传的条件,公司 oncall 也经常有人纠结为什么重复确认却没有触发重传,公司招聘面试也经常会问重复确认和快速重传。
这种老掉牙机制(即 rfc3517 中被规范,如今是 rfc6675)早不时兴了,虽然我也知道某些场景下确实仍需要兼容老掉牙的东西,但每有人咨询这问题,我的回答总是 “忘了它吧,现在都用 rack 了”。
看看 linux 系统 tcp_recovery 缺省值:
tcp_recovery - INTEGER
This value is a bitmap to enable various experimental loss recovery
features.
RACK: 0x1 enables the RACK loss detection for fast detection of lost
retransmissions and tail drops. It also subsumes and disables
RFC6675 recovery for SACK connections.
RACK: 0x2 makes RACK's reordering window static (min_rtt/4).
RACK: 0x4 disables RACK's DUPACK threshold heuristic
Default: 0x1
既然它早就缺省 1 了,谁还在乎多少个重复确认,而你又有什么理由将其恢复成 0 呢,忘了重复确认触发快速重传这件事吧。
为什么在 sack 被引入后这么多年才有人提出 rack(它是 bbr 的必须,但却可用于任何 cc) 呢。
- rack 需要高精度时间戳支持,这对硬件有所需,rtt 越小,要求的时钟精度越高;
- rack 需要重传队列报文结构体多个时间戳字段,对内存有所需;
- rack 对乱序相对严重的网络重传过于激进,对拥塞缓解不利。
历史使然,早期硬件无法支撑高频率高精度时间戳,早期网络乱序多,rack 将乱序压缩在 minrtt/4 到 srtt 之间很难覆盖频发且原因复杂的乱序检测。说白了还是 rack 在实现上依赖过多,rack 的假设是一个稳定且资源相对充足的端到端,cpu,内存,乱序都不是问题,所以它才简单。
现在的网络传输环境基本满足了稳定且资源充足,假设满足,则 rack 可大用。
但即使在当前,iot,无线弱网,卫星链路等场景,仍然是弱处理器,小内存,高乱序,低带宽,这就是 rack 不适合的场景,tcp 兼容性的意义正在此,你要知道老掉牙不时兴的东西为什么没被删去。
在大多数互联网厂商的纠结者面临的场景下,除非故意刁难,“reordering 次 dupack 触发快速重传” 确实不时兴了,若不是为了兼容,删掉这类代码 tcp 的实现就会变得非常清爽。
针对上面描述的三点理由,不必过多强调硬件支不支持高精度时间戳的问题,结构体里追加一些字段对再小的内存也不是压力,这些因素并无全局影响,早期虽不易,但你总能找到更强大的硬件和更大的内存得以支撑 rack,启不启用 rack 的关键在于第三点。
如果网络带宽低,buffer 浅,rtt 抖动大,不稳定,乱序几乎是必然(为不耽误行文,乱序分析放在最后的附录)。这种情况对于丢包和乱序的判断存在歧义,必须采用保守策略,能少发一个报文就少发一个,节约带宽。彼时 rfc3517(被 rfc6675 修订废弃) 是好的,它的名字可以看出它的态度:A Conservative Selective Acknowledgment (SACK)-based Loss Recovery Algorithm for TCP。
相比之下,资源充盈,rack 则更 aggressive,能快一点判定为 lost 就能快一点重传,节省时间。
大多数情况下,rfc3517 的保守算法需要改进的原因是场景变了,引述 rack draft 的 overview:
Using a threshold for counting duplicate acknowledgments (i.e., DupThresh) alone is no longer reliable because of today’s prevalent reordering patterns. A common type of reordering is that the last “runt” packet of a window’s worth of packet bursts gets delivered first, then the rest arrive shortly after in order. To handle this effectively, a sender would need to constantly adjust the DupThresh to the burst size; but this would risk increasing the frequency of RTOs on real losses.
如果在非上述批判的场景中误用了 rack,本不充裕的资源被激进的重传占据,则势必挤压有效吞吐。
rack 提供了一种兼容 rfc3517/6675 的方法,虽说是兼容,但却是激进地兼容:
RACK’s approach considers a packet lost when at least one higher sequence packet is SACKed and the total number of SACKed packets is at least DupThresh. For example, suppose a connection sends 10 packets, and packets 3, 5, 7 are SACKed. [RFC6675] considers packets 1 and 2 lost. RACK considers packets 1, 2, 4, 6 lost.
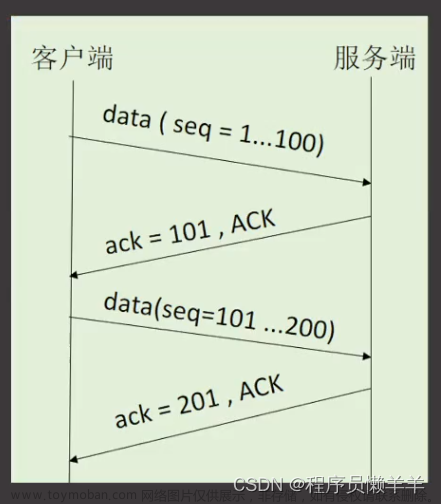
老方法不解释,能把大部分人搞懵,简单解释一下 rack 的兼容方法,比较简单:传了 1 到 10,最晚收到的确认是 7(它就是 recent ack),并且 sacked 数量不小于 dupthresh(= 3),符合触发条件,那么在最晚确认 7 之前发送的所有未确认报文均 mark lost。
这岂不就是 fack 么,rack 曾废了 fack,它自己不也如此?所不同的是,fack 由 “最高序列号” 往前 mark lost,而 rack 则由 “最 recent 确认序列号” 往前 mark lost。
总之,历史向前走,曾经的假设如今可能不再成立,新的假设下总要更新新的算法,但也不要以为所有的旧场景都以不再,做 iot 仍需要小心翼翼用内存,这与 20 年前 pc 编程无异。
如果(只是如果)互联网带宽几乎无限,收敛比接近 1,随机丢包率承诺到 0.000001 以下,回退到 rto + gbn 则最优,历史是个圈,一开始的方法可能就是终极的方法。
附:乱序分析-为什么会乱序
- 转发设备的包分类,排队算法,qos 策略粗糙或存在 bug,将同流报文排入不同队列,造成乱序;
- 可靠或尽力可靠(如 wifi)链路层重传,导致发送 1,2,3 后 1 丢失,2,3 继续转发,1 重传,产生 2,3,1 序列;
- 路由重收敛导致乱序;
- 在相对大的 buffer 中堆积足够的报文指示即将发生的严重拥塞时,后面的报文才可能被调度到另一队列甚至另一条路径而优先到达。
我们要清楚随着网络技术的发展,那些问题被减轻了,而又有哪些问题恶化了:
- 算法和 qos 越来越细化,优化,同流不同队列的问题减轻;
- 链路层越来越可靠,链路层重传导致的乱序越来越减轻;
- 随带宽提高以及 bgp/igp 互联度增强,拥塞及路由重收敛导致的乱序几乎会在 1 个 rtt 内确认,这为 rack 提供了依据;
- 端到端时延由于带宽增加而减少,但对时间更敏感,轻微时间差异就会乱序,带宽越大,并行处理越要小心;
- 多核,硬件并行处理越来越流行,其粗糙或错误实现造成的乱序不降反增。
- iot 设备场景增多,设备性能不高,网络弱,此环境乱序不随高性能设备的发展而减轻。
虽然总体看来乱序问题有所减轻,但必须清楚乱序的原因。文章来源:https://www.toymoban.com/news/detail-858874.html
浙江温州皮鞋湿,下雨进水不会胖。文章来源地址https://www.toymoban.com/news/detail-858874.html
到了这里,关于大历史下的 tcp:忘了 3 次重复确认的快速重传吧的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!