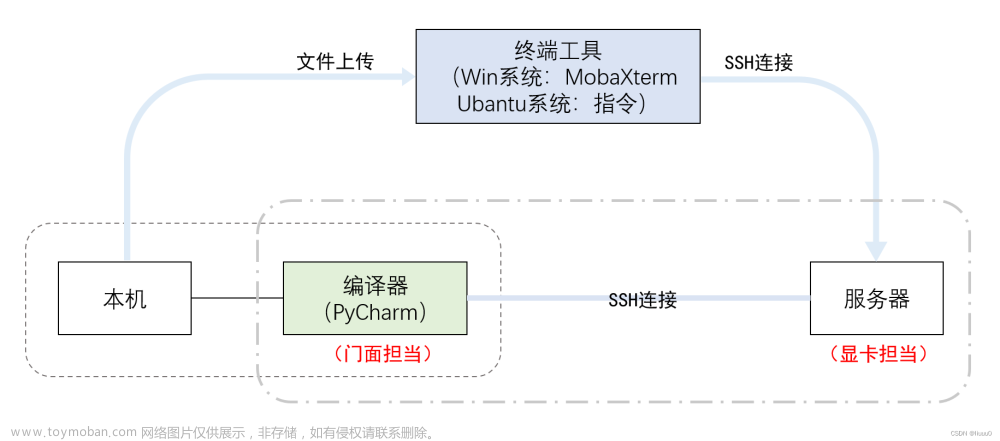
错误:
KeyError: 'Transformer/encoderblock_0/MlpBlock_3/Dense_0kernel is not a file in the archive'
解决方法:
修改这个函数即可,主要原因是Linux系统与window系统路径分隔符不一样导致文章来源:https://www.toymoban.com/news/detail-858941.html
def load_from(self, weights, n_block):
ROOT = f"Transformer/encoderblock_{n_block}"
with torch.no_grad():
# query_weight = np2th(weights[pjoin(ROOT, ATTENTION_Q, "kernel")]).view(self.hidden_size, self.hidden_size).t()
# key_weight = np2th(weights[pjoin(ROOT, ATTENTION_K, "kernel")]).view(self.hidden_size, self.hidden_size).t()
# value_weight = np2th(weights[pjoin(ROOT, ATTENTION_V, "kernel")]).view(self.hidden_size, self.hidden_size).t()
# out_weight = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "kernel")]).view(self.hidden_size, self.hidden_size).t()
query_weight = np2th(weights[(ROOT + '/' + ATTENTION_Q + "/kernel")]).view(self.hidden_size,self.hidden_size).t()
key_weight = np2th(weights[(ROOT + '/' + ATTENTION_K + "/kernel")]).view(self.hidden_size,self.hidden_size).t()
value_weight = np2th(weights[(ROOT + '/' + ATTENTION_V + "/kernel")]).view(self.hidden_size,self.hidden_size).t()
out_weight = np2th(weights[(ROOT + '/' + ATTENTION_OUT + "/kernel")]).view(self.hidden_size,self.hidden_size).t()
# query_bias = np2th(weights[pjoin(ROOT, ATTENTION_Q, "bias")]).view(-1)
# key_bias = np2th(weights[pjoin(ROOT, ATTENTION_K, "bias")]).view(-1)
# value_bias = np2th(weights[pjoin(ROOT, ATTENTION_V, "bias")]).view(-1)
# out_bias = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "bias")]).view(-1)
query_bias = np2th(weights[(ROOT + '/' + ATTENTION_Q + "/bias")]).view(-1)
key_bias = np2th(weights[(ROOT + '/' + ATTENTION_K + "/bias")]).view(-1)
value_bias = np2th(weights[(ROOT + '/' + ATTENTION_V + "/bias")]).view(-1)
out_bias = np2th(weights[(ROOT + '/' + ATTENTION_OUT + "/bias")]).view(-1)
self.attn.query.weight.copy_(query_weight)
self.attn.key.weight.copy_(key_weight)
self.attn.value.weight.copy_(value_weight)
self.attn.out.weight.copy_(out_weight)
self.attn.query.bias.copy_(query_bias)
self.attn.key.bias.copy_(key_bias)
self.attn.value.bias.copy_(value_bias)
self.attn.out.bias.copy_(out_bias)
mlp_weight_0 = np2th(weights[(ROOT + '/' + FC_0 + "/kernel")]).t()
mlp_weight_1 = np2th(weights[(ROOT + '/' + FC_1 + "/kernel")]).t()
mlp_bias_0 = np2th(weights[(ROOT + '/' + FC_0 +"/bias")]).t()
mlp_bias_1 = np2th(weights[(ROOT + '/' + FC_1 + "/bias")]).t()
self.ffn.fc1.weight.copy_(mlp_weight_0)
self.ffn.fc2.weight.copy_(mlp_weight_1)
self.ffn.fc1.bias.copy_(mlp_bias_0)
self.ffn.fc2.bias.copy_(mlp_bias_1)
self.attention_norm.weight.copy_(np2th(weights[(ROOT + '/' + ATTENTION_NORM + "/scale")]))
self.attention_norm.bias.copy_(np2th(weights[(ROOT + '/' + ATTENTION_NORM + "/bias")]))
self.ffn_norm.weight.copy_(np2th(weights[(ROOT + '/' + MLP_NORM + "/scale")]))
self.ffn_norm.bias.copy_(np2th(weights[(ROOT + '/' + MLP_NORM + "/bias")]))
 文章来源地址https://www.toymoban.com/news/detail-858941.html
文章来源地址https://www.toymoban.com/news/detail-858941.html
到了这里,关于visionTransformer window平台下报错的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!