前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第三章——LiDAR和Camera融合的BEV感知算法,先来了解下融合的基本概念
课程大纲可以看下面的思维导图

0. 简述
从第三章开始我们会针对详细的算法来给大家进行一个讲解
那我们在第三章当中主要针对融合算法也就是 LiDAR 和 Camera 融合感知的方案
我们在第四章当中主要是针对纯视觉的方案,也就是仅仅依赖单一的多视角图像输入的方法做 BEV 感知
我们开始第三章融合算法的基本介绍,我们主要分为三块内容,融合背景介绍,融合思路介绍以及融合的性能评价
1. 融合背景
我们先简单介绍一下融合的背景,第一章中提到过 BEV 感知是建立在多个子任务上的一个概念,这些子任务包括分类、检测、跟踪、分割等等,所以说我们的 BEV 是一个比较综合性的概念,它的输入也是比较宽泛的,包括毫米波雷达的输入,激光雷达点云的输入,视觉系统的输入,还有 GPS,轨迹等等,那我们得到的结果是可以为后续的决策规划提供一个比较好的支撑的

根据输入的不同,我们可以把 BEV 感知算法进行一个分类,这个分类是比较清晰的,以相机图像为输入的算法我们叫 BEV-Camera,具有代表性的有 BEVFormer、BEVDet 系列,以单点云为输入的算法我们称之为 BEV-LiDAR,那这部分其实是与传统的纯点云的方法一样,比如 PV-RCNN、PV-RCNN++ 等等,以图像和点云混合输入的方法我们称之为融合感知的方法,像 BEV-Fusion,像这类方法是同时处理图像和点云特征的,会生成一个 BEV 的多模态的表征,像这类方法中很具有代表性的就是 BEVFusion
那以上其实是一个融合背景的简介,我们知道要做融合之后,我们思考第一个问题,为什么要做融合?我们希望融合可以达成怎样的一个目的呢?🤔
实际上我们希望融合是可以实现一个模态信息的互补,那什么叫互补呢,你没有的我有或者你有的我没有,我们俩能够实现 “1+1>2”,我们称这就叫互补。那我们希望实现多模态信息的互补,这也就意味着单模态是有无法避免的一个劣势的,单模态数据的感知是存在一个固有的缺陷

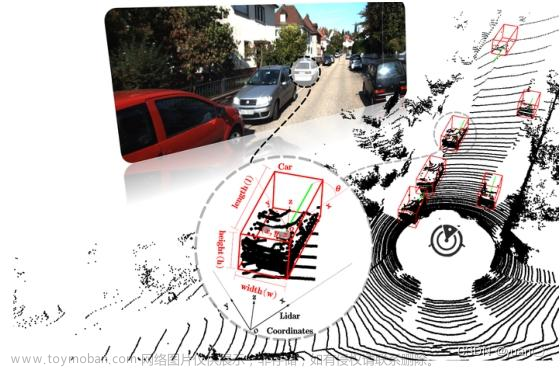
我们先说相机数据,相机数据主要是在前视图一个比较低的位置捕获的,大家在上图中也能看到,其实是一个偏平视的结果,相机模态存在的一个问题是复杂场景遮挡问题,会造成视觉表征的一个丢失。同样,激光雷达数据也是存在固有缺陷的,它受限于机械结构,在不同的距离具有不同的分辨率,这也就意味着我们采样点的数目是随着距离而变化的,而且激光雷达也很容易受到雨天、雾天等极端天气的影响。
所以说目前的单一模态都有固有的缺陷,我们当然希望通过多模态融合的方式实现跨模态信息的互补。从未来的角度出发,相机信息和点云信息的互补可以使得自动驾驶在感知层面上变得更加安全,我们这里讨论的主要任务还是 3D 检测和 3D 分割任务。
我们讲的多模态融合的输入输出是什么呢,输入自然是跨模态的数据,比如图中的点云和图像,输出则是感知结果,而感知结果是与任务相关的,它可以做一系列的任务,比如 2D 检测,3D 检测,2D 分割,3D 分割等等
那融合在哪做呢,怎么样把输入数据进行融合得到我们最终的结果呢,下面我们来逐步分析
2. 融合思路
一般而言融合方案其实是有三种划分的:
- 前融合(数据级融合)指通过空间对齐直接融合不同模态的原始传感器数据
- 深度融合(特征级融合)指通过级联或者元素相乘在特征空间中融合跨模态数据
- 后融合(目标级融合)指将各模态模型的预测结果进行融合,做出最终决策
第一种方法叫前融合即数据级融合,也叫 pre-fusion,它通过一种空间对齐的方式直接融合不同模态的原始数据,比如说点云是可以投影到 2D 空间当中的,会生成一个伪 2D 图,那这是不是一种数据融合的方式,或者说我们如果有图像的深度数据,图像的像素数据按照深度值可以投影到 3D 空间,可以生成一系列的伪点云,从图像能到点云,后续我们可以把图像数据按照伪点云的方式处理,那这也是一种数据级的融合方式
第二种方法我们叫深度融合或者说特征级的融合,是一个 Feature-Level 的融合,特征的融合,输入图像经过图像处理网络可以得到图像特征,输入点云通过点云处理网络得到点云特征,我们在特征层面把多模态数据去进行一个融合也是一种可行的方案
第三种融合叫后融合,也叫目标级的融合,它其实是偏向一种后处理的方法,从图像中我们得到了 2D 图像的预测结果,从点云中我们得到了点云的预测结果,那两种结果是不是可以进行一种融合,比如类似于 NMS 的方法,是不是能得到一个最终的检测结果,它属于一种决策级的融合
从融合方法的划分我们也能看到我们现在这种划分方法偏向于一种流程性的划分,从数据到中间过程然后到最终的结果,那在不同阶段全都是可以做多模态融合方法的。那上述流程我们其实可以划分的更详细一点,下图是一个更详细的划分示例:

图中上半部分是图像分支,图像分支包含的数据也就是输入图像,可以输入 RGB 图像也可以输入灰度图,图像分支还包含特征,可以有图像特征,也可以有深度特征,包括分割结果分割特征图也是属于一种特征,另外图像支路还包含检测结果,Object Level,是一个物体层面的,我们是得到对应物体的检测结果的,那这就是图像支路所包含的三块主要内容,分别对应数据层面,特征层面和我们的结果层面
那我们再来看下半部分的点云支路,我们划分点云支路的方法还是按照数据、特征和结果三个层面,那数据包含什么呢,那数据其实包含很多方面,可以采用伪点云的数据,也可以采用点云数据,体素化数据,还包括 2D 点云图像,我们怎么理解 2D 点云图像呢,那我们可以理解成它是点云信息在 2D 空间的一个投影,像 BEV 空间可以理解成一个 2D 平面,我们把点云投影到 BEV 空间当中属于一种 2D 点云图像的处理方式,另外一个我们有了点云输入之后,我们通过网络可以提取到一个 LiDAR Feature 点云特征,利用点云特征我们可以得到最终的一个预测结果
图像支路和点云支路我们讲要做融合,图像支路是包含三个子模块的,数据模块、特征模块还有一个结果模块,那同样我们点云支路也包含三个模块,一个是数据模块,一个是特征模块,一个是结果模块,我们图像中的三个模块和点云中的三个模块两两之间都是可以做融合的,比如图像的 Data 和点云的 Data,也就是图中黄色的线,它是一个早期融合的方法也叫 Early-Fusion,那这个很容易理解它表示我们在一开始做的融合,所以叫早期融合,是数据层面的融合,是我们网络开始时已经做的融合,是数据和数据之间的一种融合方式,所以我们叫 Early-Fusion
另外一个,我们知道数据和数据之间可以做融合,那特征和特征之间是不是也可以做融合呢,那就是图中蓝色的线,我们可以对应到深度的融合,深度融合其实是一个相比较的概念,和数据层面的融合相比深度融合做的是更深层次的,它是到了特征层面,那我们把这种方式叫做深度融合,也叫 Deep-Fusion 的方法
另外一个是后融合,按照这个流程性我们也能明白后融合是在后面做的,它是一种结果层面的融合,它也是一个相比较的概念,相比于 Early 而言的,是在网络流程之后处理的,那我们可以看到无论是 Early-Fusion 还是 Deep-Fusion 亦或 Late-Fusion 它们都是同层次的融合,我们的数据和数据,特征和特征是同 Level 的一个融合
那我们不同 Level 能不能做融合呢,能不能做 Feature 和 Data 的融合,或者说 Feature 和 Object 的融合呢,跨级的融合可不可以做呢,也是可以做的,我们把这种方式称为非对称的融合方法即 Asymmetry-fusion,
比如我们点云会得到一个 3D 检测框,我们以这个检测框为基准为初始量去图像采样特征,所以我们就得到了一个以点云 Object-Level 和图像的 Feature-Level 合在一起的融合方法,我们把这种方式叫做非对称的融合方式
我们前面表述了这么多,用下面的图来说明可能更清晰一些

大家可以自己先想一下,上面这几个图例分别对应我们刚刚提到的哪种融合方式呢,我们前面说融合主要分为四种方式,非对称的融合,偏早期的融合,深度融合,偏后期的融合
我们先看第一幅图,它是属于什么样的融合方式呢,图中上面是点云 Points 的输入,下面是图像输入,图像会经过分割处理得到一些偏向前景点的像素,把这些像素映射到点云空间和原始点云去进行一个合并,我们能看到融合后的输出点云是包含图像像素的映射点的,这种方式就属于偏早期的融合,也就是我们提到的 Early-Fusion,它虽然经过了一个分割网络的处理,但输出层面是对原始点云数据的一个融合,所以它更偏向于偏早期的数据融合阶段
接着看,第二幅图是属于什么样的融合方式呢,输入点云通过 3D 目标检测算法可以得到物体的 proposal,输入图像通过分割网络可以提取图像特征,图像特征和 3D 检测结果去做融合,它属于什么样的融合方式呢,点云支路提供 Object-Level 的检测结果,图像支路提供 Feature-Level 的特征,那利用结果去找特征是什么融合方式呢,是属于非对称的融合
我们再来看看第三幅图像它是属于什么方法呢,输入点云通过体素化的处理可以得到 3D 的体素特征,得到的点云数据是一个 Feature-Level 的特征,图像通过图像处理网络得到图像特征,图像也是一个 Feature-Level 的特征,后续做融合属于什么层面呢,属于 Feature 对 Feature 层面的,属于 Deep-Fusion 的方法
OK,我们再看最后一个,只剩下后处理融合的方式没有被提及到了,也就是我们所说的 Late-Fusion,我们也可以叫决策级的融合,它是一个结果对结果的融合,我们点云通过 3D 的目标检测网络可以得到一系列的 proposal,图像通过 2D 目标检测网络可以得到一系列的 2D 目标的 proposal,我们把 2D 目标检测框和 3D 目标检测框去进行一个融合,它就叫 Late-Fusion 的方法
所以我们这里讲了这么多主要是想让大家对融合思路进行一个基本的了解,无论是通用的自动驾驶算法还是 BEV 感知算法总的来说全都是离不开这些融合思路的
本章我们挑选了两种比较具有代表性的方法,那一种我们叫数据级的支撑,通过点云数据可以为图像数据提供一个先验,是我们 3.4 小节要介绍的 BEV-SAN
另外一种我们叫特征级的融合,也就是我们 Deep-Fusion 的一个方式,通过图像支路提取图像特征,通过点云支路提取点云特征,把图像特征和点云特征合在一起,通过融合网络可以得到一个融合后的检测结果,这部分其实是我们 3.5 小节当中要讲解的 BEVFusion
3. 融合性能优劣
此外,我们再来看一下融合性能要怎么比较,怎么讨论一个融合性能的优劣

我们看一下融合性能的比较,上图是博主在 2023/12/10 当天截取的 nuScenes 检测任务的 Leaderboard 榜单,那这个榜单我是按照 mAP 去进行一个排名的,前面的方法都是 mAP 比较高的,mAP 这个指标我们后续也会讲,它是一个越高越好的指标
那这个榜单怎么看呢,我们按顺序走,首先第一个是 Date,是结果上传的一个时间,比如按照 2023/12/10 当天排名第一的是 2023-03-25 上传的,是 BEVFusion-4D,后续第二个 Name 表示该算法的名称,第三个是 Modalities 模态,博主这里选择的是 Any,这个 Any 就是所有的模态,包括图像的 Camera 模态,包括点云的 LiDAR 模态等等,此外我们可以看到其中是有一些 Radar 的算法也是可以包含在内的,我们这里选的是 Any 也就是我们所有模态的所有方法都拉出来一起比一比,后面两个一个是 Map data 地图数据,一个是 External data 额外数据,比如有没有使用额外的标注或者有没有使用额外的数据集去做 pre-train 等等
我们再往后是一些评价指标,从 mAP 到 NDS 都是一个评价指标,我们稍后会讲。我们来说说 PKL,那 PKL 其实是一个比较新的指标,它叫 Planning KL Divergence,其实是一个 KL 散度,它代表什么意思呢,我们从这个词上也能了解这个叫规划的 KL 散度,那也就是说我们基于这个检测结果后续要怎么做规划,那这个规划决策的差异有多大,那如果衡量的是决策差异,我们当然希望这个差异是越小越好的,那也就是说如果对于一个确定的检测结果,我们要么走要么停,我们不能说这个决策是一个模棱两可的一个决策,可走可停的一个结果,那这不就乱套了嘛,所以说 PKL 结果是越低越好的,是越小越好,0 就是完美的,说明当前决策不存在差异。那当然这个指标其实对于我们要讲的检测任务而言不是特别重要,我们也可以看到榜单上面的各种方法在 PKL 上差距不是特别大,最后一个指标是 FPS,也就是我们常说的效率问题,那效率问题这里大家都没有上传,属于 n/a 是没有检测效率方面的报告的
OK,我们说完了每列代表的含义后,我们再来看看这个榜单目前最好的算法是什么,是 LiDAR 和 Camera 融合的方法,可以看到第一页榜单差不多都是一些融合的方法,另外大家也能看到,我们融合的方法离不开 BEVFusion,那所以 BEVFusion 也是作为我们第三章的一个重点内容去讲解的
OK,我们说完了这个榜单,我们详细看一下我们刚提到的这个榜单上面的指标,每一个指标具体是什么意思,是不是说这个指标越高越好呢,我们先简单梳理一下各指标代表的含义:
- mean Average Precision mAP:最常用的评价指标之一,不过 nuScenes 使用的是距离度量,而非 IoU
- mean Average Translation Error (mATE):平均平移误差,单位是 m
- mean Average Scale Error (mASE):平均尺寸误差,以 IoU 作为度量
- mean Average Orientation Error (mAOE):平均角度误差,以弧度值作为度量
- mean Average Velocity Error (mAVE):平均速度误差,m/s
- mean Average Attribute Error (mAAE):平均属性误差,1-acc,其中 acc 为类别分类准确得
- nuScenes detection score (NDS):一半基于检测性能(mAP),而另一半基于检测性能根据位置、大小、方向、属性和速度度量的检测质量
我们从 mAP 开始看,mAP 其实是我们在目标检测当中属于非常常用的一个指标,但它与通用的目标检测指标有什么区别呢,它这里的 AP 的阈值匹配不是使用 IoU 去做匹配的,而是使用我们两个框的 2D 中心距离来计算的。我们都知道 IoU 是怎么算的,两个框我们计算其交集面积和并集面积的比值作为 IoU,如果算交并比的话,物体的尺寸,物体的方向会对 IoU 产生比较明显的影响,所以 nuScenes 数据集在评价 mAP 这个指标的时候考虑的不是使用 IoU 这个阈值评价标准,而是使用一个距离度量。我们算两个点,算法预测的中心点和实际的中心点两个点之间的位置偏差,用 2D 中心距离去进行一个评判。
我们以 IoU 作为一个阈值标准的 mAP 评价指标当中我们的 IoU 会设置成 0.5 或者 0.7,那我们在 nuScenes 数据集当中,mAP 的计算我们是采用一个距离度量的方法,范围也自然有个阈值设置,我们的距离 D D D 会设置成 0.5,1,2,4,单位是 m,那 mAP 这个值显然是越高越好,它越高代表算法预测的准确率也越高
OK,我们再来看接下来几个,从 mATE 开始一直到 mAAE 有一个共性特点那就是它们都有一个词叫 Error 误差,既然是误差代表这几个指标要求越低越好。mATE 叫平均平移误差,是 2D 空间的一个欧氏距离,平均平移误差它的一个度量单位是米;mASE 是尺寸误差,那我们如果想度量尺寸以什么评价最好呢,那当然以 IoU 评价最好,所以我们在计算平均尺寸误差的时候是以 IoU 作为度量的,我们一般讲 IoU 其实是一个越高越好的量,那这里由于我们计算的是误差,所以最后的结果其实是以 1-IoU 来评价的,那所以 1-IoU 这个值是什么,越低越好的一个量
mAOE 是一个角度,我们度量角度一般采用弧度为单位,那与 Ground Truth 的偏差越小,弧度值越小,误差越小,所以这个值是越低越好的;mAVE 叫平均速度误差,是一个速度量,那我们知道 nuScenes 中的车是在行驶的,所以它会有一个速度值,那它既然是误差,它也是越低越好的;mAAE 是一个平均属性的误差,属性其实是一个类别的概念,我们分类越准,那属性误差越小,所以我们也能看到如果 acc 越大的话,我们分类越准的话,那 1-acc 值就越小。所以从 mATE 到 mAAE 都是 Error 误差的概念,误差肯定是越小越好的
我们这里提到的这些指标其实在很多论文中也能看到,他们一般是通过上下箭头来表示的,比如 mAP 指标是越高越好的,那用一个上箭头 ⬆ 来表示,从 mATE 到 mAAE 是越低越好的,会用一个下箭头 ⬇ 来表示
那我们再继续看最后的 NDS 是什么呢,它的全称是 nuScenes detection score,从名字也能看出来,它是 nuScenes 数据集专属的一个概念,叫检测得分,那这个得分我们一般一半是来源于性能的 mAP,另一半是基于位置、大小、方向、属性速度来评价的一个检测质量,那我们刚刚提到的位置,方向,大小,属性,速度是怎么来衡量的呢,其实就是我们上面提到的 mATE 到 mAAE 误差这种衡量方式,那所以 NDS 其实可以看作我们上面提到的这些指标量的一个加权融合
OK,从 3.1 到 3.3 节我们给大家简单介绍了融合算法的基本概念是什么,那后续我们会挑出一些详细的算法来具体分析它们的融合到底是怎么实现的
总结
在这节课程我们主要对融合算法做了一个基本介绍,我们讲了为什么要去做融合,主要是为了模态信息的互补,单模态感知都存在固有的缺陷,比如相机模态在复杂场景存在遮挡,点云模态采样点数目随距离而变化。接着我们讲了融合的思路,怎么去做融合呢,融合的方案是什么呢,那主要分为前融合也叫数据级的融合,深度融合也叫特征级的融合,后融合也叫目标级的融合。最后我们讨论了融合算法性能的一些常用评价指标包括 mAP、mATE、mASE 等等。文章来源:https://www.toymoban.com/news/detail-859170.html
下一节我们会讲解具体的 BEV 融合感知算法 BEV-SAN,敬请期待😄文章来源地址https://www.toymoban.com/news/detail-859170.html
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- [1] Huang et al., Multi-modal Sensor Fusion for Auto Driving Perception: A Survey
到了这里,关于三. LiDAR和Camera融合的BEV感知算法-融合算法的基本介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!