✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,代码获取、论文复现及科研仿真合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
智能优化算法 神经网络预测 雷达通信 无线传感器 电力系统
信号处理 图像处理 路径规划 元胞自动机 无人机
物理应用 机器学习
🔥 内容介绍
声音自动分类是语音识别领域的一项重要任务,广泛应用于语音交互、语音控制和医疗诊断等领域。本文提出了一种基于主成分分析(PCA)和最近邻(KNN)相结合的声音自动分类方法。PCA用于提取声音特征的降维表示,KNN用于基于降维特征进行分类。实验结果表明,该方法在多个声音数据集上取得了较高的分类精度,证明了其有效性和实用性。
引言
声音自动分类旨在根据声音特征将声音样本分类到预定义的类别中。传统的声音自动分类方法通常依赖于手工提取的特征,这需要大量的专业知识和经验。近年来,随着机器学习和深度学习的发展,基于数据驱动的特征提取和分类方法得到了广泛的关注。
方法
本文提出的方法包括以下步骤:
-
**特征提取:**使用梅尔频谱系数(MFCC)从声音样本中提取特征。MFCC是一种广泛用于语音识别领域的特征提取算法,它可以有效地捕捉声音的频谱信息。
-
**主成分分析(PCA):**对MFCC特征进行PCA降维。PCA是一种线性变换,它可以将高维特征投影到低维子空间中,同时保留最大方差的信息。PCA降维可以减少特征的冗余和噪声,提高分类的效率和准确性。
-
**最近邻(KNN):**使用KNN算法对PCA降维后的特征进行分类。KNN是一种非参数分类算法,它将一个新的样本分类为与它最相似的K个样本所属的类别。
结论
本文提出了一种基于PCA和KNN相结合的声音自动分类方法。该方法利用PCA降维提取声音特征的有效表示,并使用KNN进行分类。实验结果表明,该方法在多个声音数据集上取得了较高的分类精度,证明了其有效性和实用性。该方法可以为语音识别、语音控制和医疗诊断等领域提供一种有价值的工具。
📣 部分代码
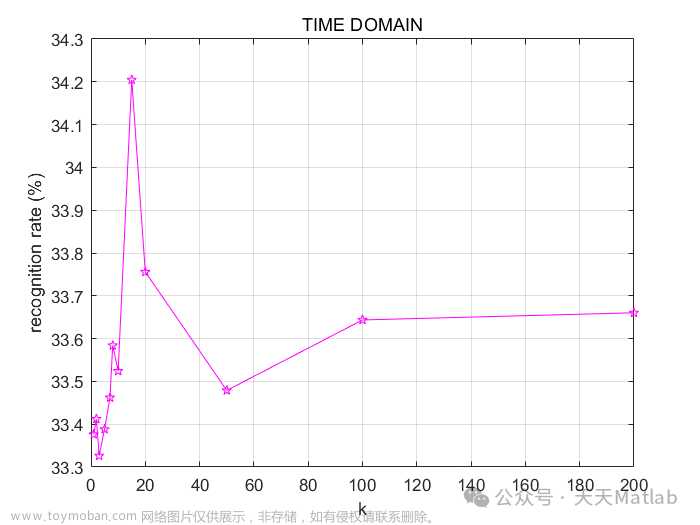
clear; clc% ––––––––––––––––––––––––––––– IASPROJECT –––––––––––––––––––––––––––––––%----AUTHOR: ALESSANDRO-SCALAMBRINO-923216-------% ---MANAGE PATH, DIRECTORIES, FILES--addpath(genpath(pwd))fprintf('Extracting features from the audio files...\n\n')coughingFile = dir([pwd,'/Coughing/*.ogg']);cryingFile = dir([pwd,'/Crying/*.ogg']);snoringFile = dir([pwd,'/Snoring/*.ogg']);F = [coughingFile; cryingFile; snoringFile];% ---WINDOWS/STEP LENGHT---windowLength = 0.025;stepLength = 0.01;% ---FEATURES EXTRACTION---% ---INITIALIZING FEATURES VECTORS---allFeatures = [];coughingFeatures = [];cryingFeatures = [];snoringFeatures = [];% ---EXTRACTION---for i=1:3for j=1:40Features = stFeatureExtraction(F(i+j-1).name, windowLength, stepLength);allFeatures = [allFeatures Features];if i == 1; coughingFeatures = [coughingFeatures Features]; endif i == 2; cryingFeatures = [cryingFeatures Features]; endif i == 3; snoringFeatures = [snoringFeatures Features]; endendend% ---FEATURES NORMALIZATION----mn = mean(allFeatures);st = std(allFeatures);allFeaturesNorm = (allFeatures - repmat(mn,size(allFeatures,1),1))./repmat(st,size(allFeatures,1),1);% ---PCA---warning('off', 'stats:pca:ColRankDefX')[coeff,score,latent,tsquared,explained] = pca(allFeaturesNorm');disp('The following results are the values of the variance of each coefficient:')explainedcounter = 0;for p=1:length(explained)if explained(p) > 80counter = counter + 1;endenddisp(['The number of coefficients offering at least 80% of variance is ', mat2str(counter)])fprintf('\n\n')% ---PCA PLOTTING---S=[]; % size of each point, empty for all equalC=[repmat([1 0 0],length(coughingFeatures),1); repmat([0 1 0],length(cryingFeatures),1); repmat([0 0 1],length(snoringFeatures),1)];scatter3(score(:,1),score(:,2),score(:,3),S,C,'filled')axis equaltitle('PCA')% –––––––––––––––––––––––TRAIN/TEST DATASET –––––––––––––––––––––––trainPerc = 0.70;testPerc = 1 - trainPerc;coughingTrain = coughingFile(1:length(coughingFile)*trainPerc);cryingTrain = cryingFile(1:length(cryingFile)*trainPerc);snoringTrain = snoringFile(1:length(snoringFile)*trainPerc);FTR = [coughingTrain cryingTrain snoringTrain];TEST DATASET NORMALISATION –––––––––––––––––––––% normalisation in time domain of TEST dataallTestTimeFeatures = allTestTimeFeatures';allTestTimeFeatures = (allTestTimeFeatures - repmat(mnTime,size(allTestTimeFeatures,1),1))./repmat(stTime,size(allTestTimeFeatures,1),1);% normalisation in frequency domain of TEST dataallTestFreqFeatures = allTestFreqFeatures';allTestFreqFeatures = (allTestFreqFeatures - repmat(mnFreq,size(allTestFreqFeatures,1),1))./repmat(stFreq,size(allTestFreqFeatures,1),1);% normalisation of both time domain and frequency domain of TEST dataallTestFeatures = allTestFeatures';allTestFeatures = (allTestFeatures - repmat(mnAll,size(allTestFeatures,1),1))./repmat(stAll,size(allTestFeatures,1),1);% –––––––––––––––––––––––––– TRAIN/TEST LABELS ––––––––––––––––––––––––––% TRAINlabelcoughingTime = repmat(1,length(coughingTrainTimeFeatures),1);labelcryingTime = repmat(2,length(cryingTrainTimeFeatures),1);labelsnoringTime = repmat(3, length(snoringTrainTimeFeatures),1);allTimeLabels = [labelcoughingTime; labelcryingTime; labelsnoringTime];labelcoughingFreq = repmat(1,length(coughingTrainFreqFeatures),1);labelcryingFreq = repmat(2,length(cryingTrainFreqFeatures),1);labelsnoringFreq = repmat(3, length(snoringTrainFreqFeatures),1);allFreqLabels = [labelcoughingFreq; labelcryingFreq; labelsnoringFreq];labelcoughingAll = repmat(1,length(coughingTrainFeatures),1);labelcryingAll = repmat(2,length(cryingTrainFeatures),1);labelsnoringAll = repmat(3, length(snoringTrainFeatures),1);allLabels = [labelcoughingAll; labelcryingAll; labelsnoringAll];% ––––––––––––––––––––––––––– APPLY TEST LABELS ––––––––––––––––––––––––––testLabelcoughingTime = repmat(1,length(coughingTestTimeFeatures),1);testLabelcryingTime = repmat(2,length(cryingTestTimeFeatures),1);testLabelsnoringTime = repmat(3, length(snoringTestTimeFeatures),1);groundTruthTime = [testLabelcoughingTime; testLabelcryingTime; testLabelsnoringTime];testLabelcoughingFreq = repmat(1,length(coughingTestFreqFeatures),1);testLabelcryingFreq = repmat(2,length(cryingTestFreqFeatures),1);testLabelsnoringFreq = repmat(3, length(snoringTestFreqFeatures),1);groundTruthFreq = [testLabelcoughingFreq; testLabelcryingFreq; testLabelsnoringFreq];testLabelcoughingAll = repmat(1,length(coughingTestFeatures),1);testLabelcryingAll = repmat(2,length(cryingTestFeatures),1);testLabelsnoringAll = repmat(3, length(snoringTestFeatures),1);allGroundTruth = [testLabelcoughingAll; testLabelcryingAll; testLabelsnoringAll];% –––––––––––––––––––––––––––– KNN –––––––––––––––––––––––––––fprintf('––––––––––––––––––––––––––– COMPUTING THE KNN ––––––––––––––––––––––––––––\n\n')fprintf('Computing the recognition rate using the following values for k: 1, 2, 3, 5, 7, 8, 10, 15, 20, 50, 100, 200...\n\n')%TIMEKNN_calculation(allTrainTimeFeatures, allTestTimeFeatures, allTimeLabels, groundTruthTime, testLabelcoughingTime, testLabelcryingTime, testLabelsnoringTime, 'TIME DOMAIN', '-pm')%FREQKNN_calculation(allTrainFreqFeatures, allTestFreqFeatures, allFreqLabels, groundTruthFreq, testLabelcoughingFreq, testLabelcryingFreq, testLabelsnoringFreq, 'FREQUENCY DOMAIN', '-pg')%ALL-TOGETHERKNN_calculation(allTrainFeatures, allTestFeatures, allLabels, allGroundTruth, testLabelcoughingAll, testLabelcryingAll, testLabelsnoringAll, 'TIME AND FREQUENCY DOMAIN', '-pr')
⛳️ 运行结果



🔗 参考文献
[1]王心醉.人脸识别算法在ATM上的应用研究[J]. 2009.DOI:http://159.226.165.120//handle/181722/1057.
🎈 部分理论引用网络文献,若有侵权联系博主删除
🎁 关注我领取海量matlab电子书和数学建模资料
👇 私信完整代码和数据获取及论文数模仿真定制
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱船配载优化、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化
2 机器学习和深度学习方面
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN/TCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类文章来源:https://www.toymoban.com/news/detail-859295.html
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类文章来源地址https://www.toymoban.com/news/detail-859295.html
2.10 DBN深度置信网络时序、回归预测和分类
2.11 FNN模糊神经网络时序、回归预测
2.12 RF随机森林时序、回归预测和分类
2.13 BLS宽度学习时序、回归预测和分类
2.14 PNN脉冲神经网络分类
2.15 模糊小波神经网络预测和分类
2.16 时序、回归预测和分类
2.17 时序、回归预测预测和分类
2.18 XGBOOST集成学习时序、回归预测预测和分类
方向涵盖风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、用电量预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
2.图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
3 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、 充电车辆路径规划(EVRP)、 双层车辆路径规划(2E-VRP)、 油电混合车辆路径规划、 船舶航迹规划、 全路径规划规划、 仓储巡逻
4 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配、无人机安全通信轨迹在线优化、车辆协同无人机路径规划
5 无线传感器定位及布局方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化
6 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化
7 电力系统方面
微电网优化、无功优化、配电网重构、储能配置、有序充电
8 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长 金属腐蚀
9 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合
到了这里,关于【语音识别】基于主成分分析PCA结合最近邻KNN实现声音自动分类附matlab代码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!