神经网络算法是一种模仿人类神经系统结构和功能的机器学习算法。它由多个神经元(或称为节点)组成的层次结构构成,通过模拟神经元之间的连接和信号传递来学习数据之间的复杂关系。下面详细描述神经网络算法的一般原理和工作流程:
1. 神经元结构:
神经元是神经网络的基本单元。每个神经元都有多个输入和一个输出。每个输入都有对应的权重,神经元将输入与权重相乘并加权求和,然后将结果传递给激活函数,激活函数产生神经元的输出。
-
输入:
每个神经元接收来自上一层神经元或输入数据的信息。这些信息可以是输入特征的数值,也可以是上一层神经元的输出。 -
权重:
每个输入都有一个对应的权重,用于表示该输入对神经元输出的影响程度。权重决定了神经元对不同输入的敏感程度,可以理解为是输入的重要性或者贡献度。 -
加权求和:
神经元将输入与对应的权重相乘,并将所有加权值求和。这个过程可以用数学公式表示为:加权和 = ∑(输入_i × 权重_i)其中,
n是输入的数量,输入_i和权重_i分别表示第i个输入和对应的权重。 -
偏置(Bias):
除了权重之外,每个神经元还有一个偏置值,用于调整神经元的激活阈值。偏置可以理解为是神经元的基础活跃程度,影响着神经元对输入的敏感度。 -
激活函数:
加权求和得到的结果通常会通过一个激活函数进行转换,生成神经元的输出。常用的激活函数包括:- Sigmoid函数
- ReLU函数(Rectified Linear Unit)
- tanh函数
-
输出:
最终,神经元的输出即为激活函数的输出,表示神经元对输入数据的处理结果。这个输出会传递给下一层神经元或作为神经网络的最终输出。
神经元结构的设计和参数设置对神经网络的性能有重要影响,合适的权重和偏置以及适当选择的激活函数可以提高神经网络的学习能力和泛化能力。
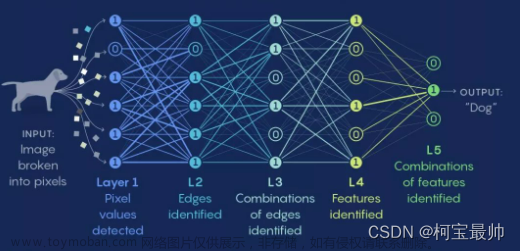
2. 神经网络结构:
神经网络由多个层次组成,通常包括输入层、隐藏层和输出层。其中,输入层接受原始数据,输出层产生最终的预测结果,隐藏层在输入层和输出层之间进行特征提取和表示学习。
当然,以下是使用Markdown语法详细描述神经网络结构:
-
输入层(Input Layer):
输入层是神经网络的第一层,负责接收原始数据或特征。每个输入对应数据的一个特征,并将其传递给下一层。 -
隐藏层(Hidden Layers):
隐藏层位于输入层和输出层之间,用于进行特征提取和表示学习。神经网络可以有多个隐藏层,每个隐藏层包含多个神经元。隐藏层的数量和每层的神经元数量是神经网络结构的重要参数,它们影响着网络的复杂度和学习能力。 -
输出层(Output Layer):
输出层是神经网络的最后一层,负责产生最终的预测结果。输出层的神经元数量取决于问题的类型,例如对于分类问题,通常有一个神经元对应每个类别;对于回归问题,通常只有一个神经元。
神经网络的层数、每层的神经元数量以及层与层之间的连接方式构成了网络的结构。合适的网络结构对于神经网络的性能至关重要,需要根据问题的复杂度和数据的特征进行调整。通常通过交叉验证和实验来选择最佳的网络结构,以达到最好的性能和泛化能力。
3. 前向传播(Forward Propagation):
前向传播是指从输入层开始,通过神经网络的每一层,直到输出层产生预测结果的过程。在每个神经元中,输入与权重相乘求和,经过激活函数得到输出,然后传递给下一层。
以下是使用Markdown语法详细描述前向传播过程:
输入数据传递:
- 输入层接收原始数据或特征,并将其传递给第一个隐藏层。
- 每个输入特征与对应的权重相乘,然后加权求和得到隐藏层神经元的输入值。
隐藏层计算:
- 隐藏层的每个神经元将输入加权求和的结果传递给激活函数。
- 激活函数对输入进行非线性转换,生成隐藏层神经元的输出。
- 这一过程依次进行,直到最后一个隐藏层。
输出层计算:
- 输出层接收来自最后一个隐藏层的输出,并将其传递给输出神经元。
- 输出神经元对输入进行加权求和,并通过激活函数产生最终的输出结果。
- 对于分类问题,通常使用softmax函数将输出转换为概率分布;对于回归问题,输出通常直接为预测值。
整个过程总结:
- 前向传播过程从输入数据开始,逐层计算神经网络的输出。
- 每层神经元将上一层的输出作为输入,通过权重和激活函数进行计算,得到下一层的输出。
- 最终,神经网络产生输出结果,用于进行预测或分类。
前向传播是神经网络中信息传递的过程,它确定了网络在给定输入下的输出结果。这个过程是神经网络训练和推理的基础,通过不断调整网络参数,使得前向传播的输出与实际标签尽可能接近。
4. 损失函数(Loss Function):
损失函数衡量模型预测结果与真实标签之间的差异。常用的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross Entropy)等。
-
目的:
- 损失函数的目标是量化模型预测与真实标签之间的差异,它是评价模型性能的重要指标。
- 优化损失函数可以使得模型在训练过程中不断地调整参数,提高模型的准确性和泛化能力。
-
常见损失函数:
-
均方误差(Mean Squared Error,MSE):
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
其中, y i y_i yi 是真实标签, y ^ i \hat{y}_i y^i 是模型预测值, n n n 是样本数量。MSE 适用于回归问题,它衡量模型预测值与真实值之间的平均误差。 -
交叉熵(Cross Entropy):
CrossEntropy = − 1 n ∑ i = 1 n ( y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ) \text{CrossEntropy} = -\frac{1}{n} \sum_{i=1}^{n} (y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i)) CrossEntropy=−n1i=1∑n(yilog(y^i)+(1−yi)log(1−y^i))
其中, y i y_i yi 是真实标签, y ^ i \hat{y}_i y^i 是模型预测的概率值, n n n 是样本数量。交叉熵适用于分类问题,它衡量模型输出概率分布与真实标签之间的差异。 -
其他损失函数:
除了上述常见的损失函数外,还有一些特定领域或任务中常用的损失函数,如 Huber Loss(用于回归问题中的稳健损失函数)、Hinge Loss(用于支持向量机中的损失函数)等。
-
-
选择损失函数:
- 选择合适的损失函数取决于问题的性质和数据的分布。
- 在回归问题中,通常使用 MSE 等损失函数;在分类问题中,交叉熵等损失函数更为常见。
损失函数的选择直接影响着神经网络的训练效果和性能,因此在设计网络结构和训练过程中需要谨慎选择合适的损失函数。
5. 反向传播(Backpropagation):
反向传播是神经网络中最重要的步骤之一,用于调整神经元之间的连接权重,以最小化损失函数。它通过计算损失函数对每个权重的偏导数,然后利用梯度下降法更新权重。
-
目的:
- 反向传播的目标是计算损失函数对每个参数的梯度,以便根据梯度方向调整参数值,最小化损失函数。
- 通过不断迭代反向传播和参数更新过程,神经网络可以逐渐优化模型参数,提高模型的准确性和泛化能力。
-
基本原理:
- 反向传播利用链式法则计算损失函数对每个参数的偏导数,然后根据梯度下降法更新参数。
- 反向传播的计算过程分为两个阶段:反向传播(向后计算梯度)和参数更新。
-
反向传播过程:
-
向后传播误差:
- 从输出层开始,计算损失函数关于输出的梯度。
- 通过链式法则,将梯度沿着网络反向传播,逐层计算每个参数的梯度。
-
计算参数梯度:
- 根据每层的输入、权重和激活函数,计算每个参数对损失的偏导数。
- 使用链式法则将误差从输出层传播到隐藏层,计算隐藏层参数的梯度。
-
-
参数更新:
- 根据计算得到的参数梯度,利用梯度下降等优化算法更新参数值。
- 通常采用学习率来控制每次更新的步长,避免更新过大或过小。
-
迭代过程:
- 反向传播和参数更新过程是迭代进行的,通常需要多次迭代才能使得模型收敛到最优解。
- 反向传播过程直到达到停止条件(如达到最大迭代次数、损失函数变化小于阈值等)才结束。
反向传播是神经网络训练的核心算法之一,它使得神经网络能够通过优化损失函数来学习数据的特征和模式,从而实现有效的模型训练和预测。
6. 优化算法:
梯度下降是最常用的优化算法之一,但也有改进版如随机梯度下降、小批量梯度下降等。这些算法通过不断地调整权重来最小化损失函数,使神经网络能够更好地拟合数据。
-
目的:
- 优化算法的目标是通过调整参数,使得损失函数达到最小值,从而提高模型的性能和泛化能力。
- 不同的优化算法有不同的更新策略和收敛性能,选择合适的优化算法对于训练有效的神经网络模型至关重要。
-
常见优化算法:
-
梯度下降(Gradient Descent):
- 梯度下降是最基本的优化算法之一,通过计算损失函数关于参数的梯度,并沿着梯度的反方向更新参数值。
- 可以根据梯度的大小调整学习率,以控制参数更新的步长。
-
随机梯度下降(Stochastic Gradient Descent,SGD):
- 随机梯度下降是梯度下降的变种,每次更新只使用部分数据(一个样本或一小批样本)的梯度。
- 这样可以加快参数更新的速度,但也会引入一定的随机性,需要适当调整学习率和批量大小。
-
小批量梯度下降(Mini-batch Gradient Descent):
- 小批量梯度下降是介于梯度下降和随机梯度下降之间的优化算法,每次更新使用一小批数据的梯度。
- 它综合了梯度下降的稳定性和随机梯度下降的效率,通常是训练神经网络的首选方法。
-
动量优化(Momentum Optimization):
- 动量优化是基于梯度的优化算法的改进版本,它引入了动量项,模拟物理中的惯性效应。
- 这样可以加速收敛过程,避免在损失函数空间中陷入局部极小值。
-
自适应学习率算法(Adaptive Learning Rate Algorithms):
- 自适应学习率算法根据参数的历史梯度信息自动调整学习率,如 Adagrad、RMSProp 和 Adam 等。
- 这些算法可以根据每个参数的梯度大小动态调整学习率,提高训练的稳定性和收敛速度。
-
-
选择优化算法:
- 选择合适的优化算法取决于问题的性质、数据的特点和网络的结构。
- 需要根据实际情况进行试验和比较,以找到最适合的优化算法。
优化算法直接影响着神经网络的训练速度、收敛性和泛化能力,因此选择合适的优化算法对于训练高效的神经网络模型至关重要。
7. 参数调节和验证
神经网络具有许多超参数(如层数、每层神经元数量、学习率等),需要进行调节以获得最佳性能。通常会将数据划分为训练集、验证集和测试集,用验证集评估模型性能并调节超参数,最终用测试集评估模型的泛化能力。
-
目的:
- 参数调节的目标是选择合适的超参数(如学习率、正则化参数、隐藏层大小等),以提高模型的性能。
- 验证的目标是评估模型在独立数据集上的性能,以检验模型的泛化能力。
-
超参数调节:
- 网格搜索(Grid Search):
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# Define the parameter grid
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1], 'kernel': ['rbf', 'linear']}
# Create the model
model = SVC()
# Perform grid search
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# Get the best parameters
best_params = grid_search.best_params_
print("Best parameters:", best_params)
网格搜索是一种常用的超参数调节方法,通过在预定义的超参数网格上进行组合搜索,并对每组参数进行评估来确定最佳组合。
这种方法的缺点是计算开销大,但在超参数空间相对较小的情况下适用。
- 随机搜索(Random Search):
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# Define the parameter distributions
param_dist = {'C': uniform(loc=0, scale=4), 'gamma': uniform(loc=0, scale=2), 'kernel': ['rbf', 'linear']}
# Create the model
model = SVC()
# Perform random search
random_search = RandomizedSearchCV(model, param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
# Get the best parameters
best_params = random_search.best_params_
print("Best parameters:", best_params)
随机搜索是一种更加高效的超参数调节方法,随机选择参数组合进行评估,直到达到预设的搜索次数或时间限制。
这种方法相比于网格搜索更适用于大型超参数空间和高维参数空间。
-
贝叶斯优化(Bayesian Optimization):
- 贝叶斯优化是一种基于高斯过程的优化算法,通过构建参数空间的代理模型来估计最优参数,并在不断迭代中更新模型以获得更好的性能。
- 这种方法通常需要更少的评估次数,并且在大型参数空间和高计算成本的情况下表现良好。
- 验证方法:
- 交叉验证(Cross Validation):
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
# Create the model
model = RandomForestClassifier(n_estimators=100)
# Perform cross-validation
scores = cross_val_score(model, X_train, y_train, cv=5)
# Print the mean accuracy
print("Mean Accuracy:", scores.mean())
交叉验证是一种常用的验证方法,将训练数据分成多个子集,每次使用其中一个子集作为验证集,其余子集作为训练集进行模型训练和评估。
交叉验证可以提供对模型性能的更稳健的估计,减少了数据划分的偶然性。
- 留出验证(Holdout Validation):
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Create the model
model = SVC(C=1, gamma=0.1, kernel='rbf')
# Train the model on the training set
model.fit(X_train, y_train)
# Make predictions on the validation set
y_pred = model.predict(X_val)
# Calculate accuracy
accuracy = accuracy_score(y_val, y_pred)
print("Validation Accuracy:", accuracy)
留出验证是将数据集划分为训练集和验证集两部分,其中一部分用于训练模型,另一部分用于验证模型性能。
这种方法简单直接,但数据利用率较低,对数据划分敏感。
-
验证集策略:
- 在进行参数调节和验证时,需要注意保持验证集的独立性,避免将验证集用于参数调节过程中。
- 通常需要在参数调节前将数据划分为训练集、验证集和测试集,其中验证集用于参数调节,测试集用于最终评估模型性能。
参数调节和验证过程需要谨慎进行,合适的方法和策略可以帮助提高模型的性能和泛化能力,从而更好地适应实际应用场景。
8.展望与总结
整体来看,神经网络作为一种强大的机器学习模型,在许多领域都取得了显著的成功。文章来源:https://www.toymoban.com/news/detail-859374.html
展望
1. 深度学习的持续发展
- 随着硬件计算能力的不断提升和算法优化的持续改进,深度学习将继续发展,解决更加复杂和多样化的问题。
2. 跨学科融合
- 神经网络的发展将进一步促进机器学习、计算机视觉、自然语言处理等领域的融合,为跨学科研究和创新提供更多可能性。
3. 自动化和智能化应用
- 神经网络在自动化、智能化应用领域的应用将更加广泛,如自动驾驶、智能助手、智能医疗等,为社会生活带来更多便利和改变。
4. 终身学习和迁移学习
- 神经网络模型将逐渐向更加灵活和智能的方向发展,支持终身学习和迁移学习,能够在不同任务和环境中持续学习和适应。
总结
1. 技术进步推动发展
- 硬件技术的进步(如GPU、TPU)、算法优化(如正则化、归一化)、大规模数据集的开放等都推动了神经网络的发展。
2. 应用领域广泛
- 神经网络已经在图像识别、自然语言处理、语音识别等领域取得了突破性的成果,并在工业、医疗、金融等领域得到广泛应用。
3. 挑战与机遇并存
- 神经网络在数据需求、解释性、稳定性等方面仍然存在挑战,但随着技术和理论的不断进步,这些挑战也将逐渐被克服。
4. 多方合作共同推进
- 神经网络的发展需要学术界、工业界和政府等多方合作,共同推动技术的进步和应用的落地。
神经网络作为一种强大的机器学习模型,将继续在各个领域发挥重要作用,推动人工智能技术的不断发展和应用。文章来源地址https://www.toymoban.com/news/detail-859374.html
到了这里,关于【机器学习算法】穿越神经网络的迷雾:深入探索机器学习的核心算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!