无心生大用,有物不通神
🎵 闪现吃血王昭君《道德经》
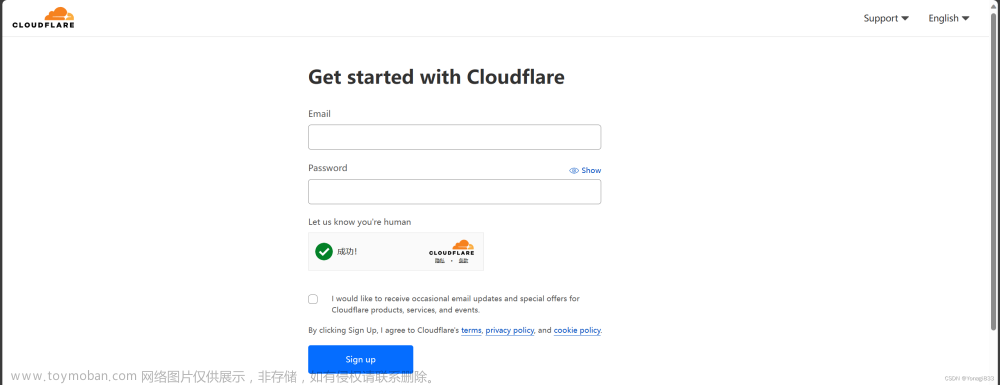
在当今的互联网世界中,保护网站免受恶意访问变得尤为重要。Cloudflare是一种流行的解决方案,提供了多种安全功能,包括一个被广泛称为"5秒盾"(5 Second Challenge)的机制。这个机制要求访问者等待5秒钟,Cloudflare在这期间验证访问者不是机器人。这对于人类用户来说可能只是轻微不便,但对于需要自动化抓取网站数据的开发者来说,则可能成为一个大问题。本文将探讨如何使用Python库Cloudscraper来突破这一防御机制。
为什么需要Cloudscraper?
Cloudflare的5秒盾是通过检查浏览器的JavaScript执行能力来工作的,因为大多数爬虫和自动化脚本不会执行JavaScript。Cloudscraper是一个Python库,设计用来模拟浏览器的行为,包括执行JavaScript,从而能够绕过Cloudflare的检查。
如何使用Cloudscraper
以下是使用Cloudscraper库的一个简单示例,旨在说明其基本用法和如何配置它来模拟特定的浏览器环境。
import cloudscraper
# 创建一个Cloudscraper实例,设置延迟和模拟的浏览器环境
scraper = cloudscraper.create_scraper(delay=5, browser={
'browser': 'chrome',
'platform': 'linux',
'mobile': False,
})
# 使用代理和Cloudscraper实例来访问一个网页
resp = scraper.get('https://webcache.googleusercontent.com/search?q=cache:https://www.truepeoplesearch.com/find/i',
proxies={'http': 'http://127.0.0.1:2333', 'https': 'http://127.0.0.1:2333'})
## 打印响应的文本和状态码
print(resp.text)
print(resp.status_code)
代码逻辑与原理
创建Cloudscraper实例: 使用cloudscraper.create_scraper()方法创建一个Cloudscraper对象。可以通过delay参数设置每个请求之间的延迟,以避免被服务器认为是攻击。browser参数用于模拟特定的浏览器环境,这里模拟的是Linux平台上的Chrome浏览器。
设置代理: 为了增加匿名性或绕过IP限制,代码中使用了代理服务器。proxies参数接受一个字典,指定HTTP和HTTPS请求应该使用的代理。
发送请求: 使用scraper.get()方法发送GET请求。这个方法模拟浏览器的请求,包括执行必要的JavaScript,这样即使是受Cloudflare保护的网站也能成功访问。
处理响应: 打印出响应内容(resp.text)和状态码(resp.status_code),以便于调试和验证是否成功绕过Cloudflare的检查。文章来源:https://www.toymoban.com/news/detail-859516.html
结论
Cloudscraper提供了一种有效的方式来绕过Cloudflare的5秒盾保护,使得
开发者可以自动化抓取那些使用了这一防御机制的网站。通过模拟真实的浏览器行为,Cloudscraper能够执行JavaScript代码,从而通过Cloudflare的检测。这使得开发者能够访问和收集重要数据,而无需手动干预或放弃因防护机制而难以抓取的网站。文章来源地址https://www.toymoban.com/news/detail-859516.html
到了这里,关于【爬虫】 突破Cloudflare 5秒盾的艺术:使用Cloudscraper的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!