一、简介
定位元素:Selenium能够模拟用户去浏览器页面上执行对应(输入,点击,清除,提交)等操作,它是凭什么方式去寻找到页面的元素?Selenium没有视觉、听觉等。Selenium通过在页面上寻找元素位置,找到元素后,然后对元素进行相应的操作,Selenium寻找元素位置的方法,称之为定位。
二、自动化测试步骤
简单的来说步骤为:定位元素→操作元素→验证操作结果→记录测试结果
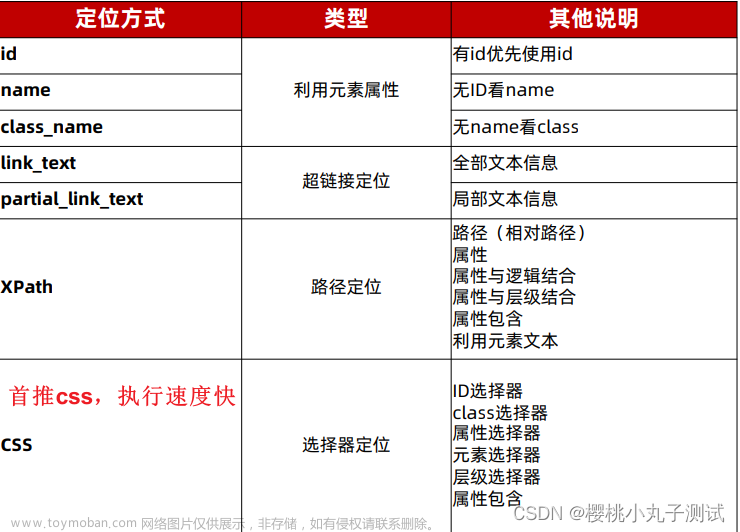
三、常用八大定位元素
(1)id
(2)name
(3)class name
(4)tag name
(5)link text
(6)partial link text
(7)xpath
(8)css selector
四、如何定位
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回元素句柄来定位元素
findElement() 方法返回一个元素, 如果没有找到,会抛出一个异 NoElementFindException()
findElements()方法返回多个元素, 如果没有找到,会返回空数组, 不会抛出异常
五、如何选择定位方法
选择简单,稳定的定位方法。当页面元素有 id属性的时候,尽量使用 id来定位。没有的话,再选择其他定位方法。cssSelector 执行速度快,推荐使用。
定位超链接的时候,可以考虑 linkText或 partialLinkText:但是要注意的是,文本经常发生改变,所以不推荐用。
xpath 功能最强悍。当时执行速度慢,因为需要查找整个DOM, 所以尽量少用。实在没有办法的时候,才使用 xpath。
六、定位方法的使用
1、通过id定位
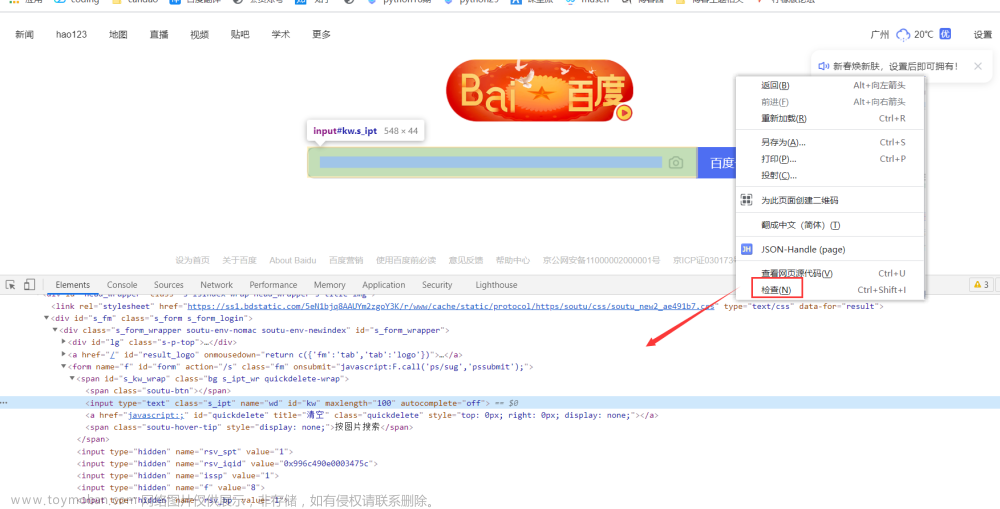
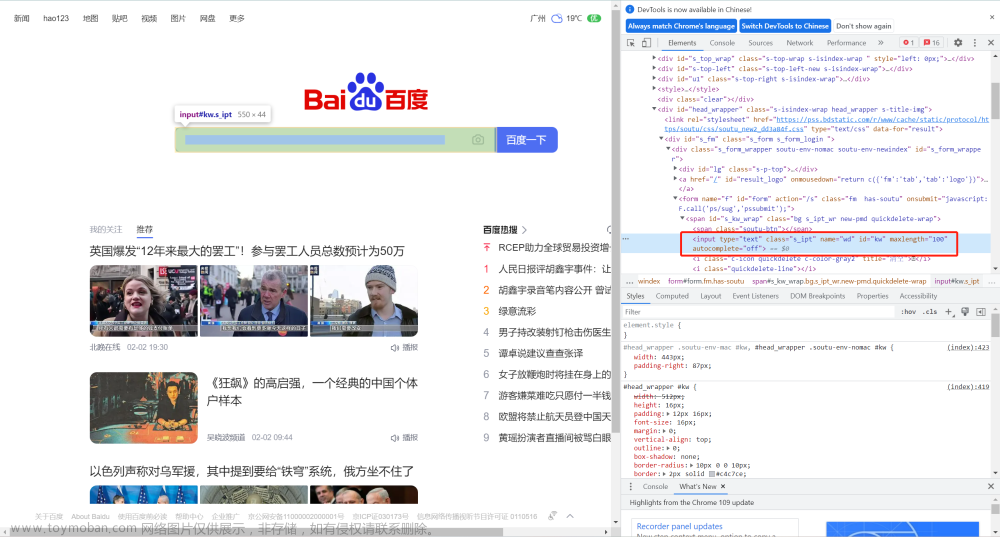
例子:探测百度主页输入框
我们可以看到蓝色框里面的id="kw"。
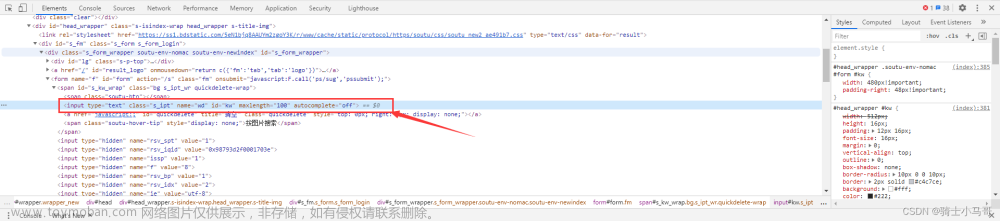
代码如下:
driver.findElement(By.id( "kw" )).sendKeys("小马哥");总结: 其实很简单,就是找元素的id,一般来说id都是唯一的,当然了特殊的另说,遇到特殊的就直接用Xpath定位。
2、通过name定位
代码如下:
driver.findElement(By.name( "wd" )).sendKeys("小马哥");总结:其实很简单,就是找元素的name,一般来说name不都是唯一的,那就需要换其他的定位方法了,当然了特殊的另说。一般都是绝大多数,特殊是个例,也就是我们常说的另类,如果目标元素节点有这个name属性,我们就采用By name,如果没有,就换成其他方法,例如id,例如XPath,一般XPath是万能的
3、通过class name定位
//By name 定位
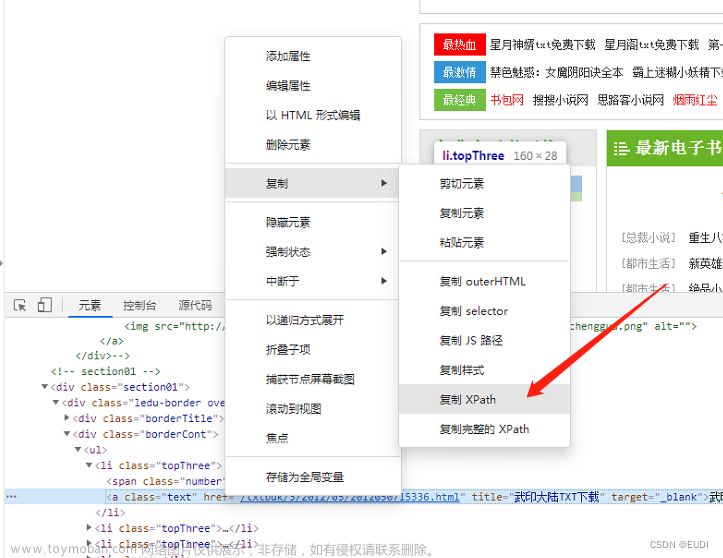
driver.findElement(By.className( "s_ipt" )).sendKeys("xiao");注意事项:当我们测试的过程中遇到了多类名的class时就需要谨慎了,因为多类名里面有空格,此外,我们需要在多类名里面找到正确的那一个。这样做很浪费时间,所以遇到多类名尽量用Xpath或者其他属性定位。就像下图这杨:

4、 通过tag name定位
通过tagname进行查找元素,findelement返回的数值没有重复的,那就是一个。
WebElement ww = driver.findElement(By.tagName("title"));
System.out.println(ww.getText());如果当前标签存在重复则在运行的时候会找不到元素,此时需要使用find_elements***。通过tagName来搜索元素的时候,会返回多个元素. 因此需要使用findElements()。
List<WebElement> links= driver.findElements(By.tagName( "article" ));
//storing the size of the links
int i= links.size();
//Printing the size of the string
//System.out.println(i);
for (int j=0; j<i; j++)
{
//Printing the links
System.out.println(links.get(j).getText());
}拓展:
1.tag name即标签名称,如:a、input、button、img等
注意: 如果使用tagName, 要注意很多HTML元素的tagName是相同的,
比如单选框,复选框, 文本框,密码框.这些元素标签都是input. 此时单靠tagName无法精确获取我们想要的元素, 还需要结合type属性,才能过滤出我们要的元素
WebDriver driver = new FirefoxDriver();
driver.get("http://www.cnblogs.com");
List<WebElement> buttons = driver.findElements(By.tagName("input"));
for (WebElement webElement : buttons) {
if (webElement.getAttribute("type").equals("text")) {
System.out.println("input text is :" + webElement.getText());
}
}5、通过link Text定位(精确定位)
注意:linkText也是遵循“匹配第一个”的原则,同一网页多次出现的话找第一个。
 代码如下:
代码如下:
driver.findElement(By.linkText("加入购物车")).click();
Thread.sleep(1000);Thread.sleep()的意思上面操作完成后让程序睡1秒。
6、通过partial link text
driver.findElement(By.partialLinkText("加入")).click();
Thread.sleep(1000);注意:为了防止因为文字出现位置太多,定位失败,建议选择的字符要有唯一性,不然会定位到其他地方,或者无法定位。此外一定要连续的字才行,随便从中间挑几个字不连续那不行。英文也一样,得是连续字母才行。你要是不信偏要以身试法,那就会报错。
7、通过Xpath定位
(1)静态
a、绝对路径定位
(1)WebElement searchBox = driver.findElement(By.xpath( "/html/body/div/div/div/div/div/form/span/input" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("/html/body/div/div/div/div/div/form/span[2]/input[@value='百度一下']"));缺点:当页面元素位置发生改变时,都需要修改,因此,并不推荐使用绝对路径的写法。
b、相对路径:
(1)WebElement searchBox = driver.findElement(By.xpath( "//*[@id='kw']" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//*[@id='su']"));两者区别:
绝对路径 以 "/" 开头, 让xpath 从文档的根节点开始解析
相对路径 以"//" 开头, 让xpath 从文档的任何元素节点开始解析
一般我们在测试的时候直接选择需要测试的代码块然后 右击-复制-完整Xpath就OK了
(2)动态
有一种特殊的情况:页面元素的属性值会被动态地生成,即每次看到的页面元素属性值是不一样的,这种页面元素会加大定位的难度,使用模糊属性值定位方法可以部分解决问题。首先带大家了解一下xpath的元素
1)Starts-with()
格式:xxx.By.xpath("//标签[starts-with(@属性,'内容')]")
//input[starts-with(@name,'name1')]
//查找name属性中开始位置包含'name1'关键字的页面元素2)Contains()
格式:xxx.By.xpath("//标签[contains(@属性,'内容')]")
//查找name属性中包含wd关键字的页面元素
WebElement searchBox = driver.findElement(By.xpath( "//input[contains(@name,'wd')]" ));
WebElement SearchButton = driver.findElement(By.xpath("//input[contains(@value,'百度一下')]"));
3)text ()
格式:xxx.By.xpath("//标签[text()='文本']") 或者 xxx.By.xpath("//标签[text()='文本']")
//查找所有文本为"百度搜索" 的元素,精确匹配
driver.findElement(By.xpath("//*[text()='百度搜索']"));
//查找所有文本为“搜索” 的超链接 ,模糊匹配
driver.findElement(By.xpath("//a[contains(text(),'搜索')]")); 总结:Xpath的功能非常强大,不仅能够完成界面定位的任务,而且能保证稳定性,实际自动化测试中,能够识别界面元素是重要的,更重要的是要保证版本间的稳定性,减少脚本的维护工作。
如下规则请参考:
(1)特征越少越好
(2)特征越是界面可见的越好
(3)不能使用绝对路径
(4)避免使用索引号
(5)相对路径,属性值,文本内容,Axis 可以任意组合,当然属性值和文本内容的模糊匹配也支持和上述方式任意组合,Axis 可以嵌套使用。
通过 Xpath 的各种方式组合,能够解决 selenium 自动化测试中界面定位的全部问题,可以说:有了 Xpath,响哥再也不用担心我不会元素定位了。
8、通过cssSelector()定位
1、绝对路径定位
格式:xxx.By.cssSelector("绝对路径")
CSS表达式:
①用大于号(>)
(1)html>body>div>div>div>div>div>form>span>input
(2)html>body>div>div>div>div>div>form>span>input[value='百度一下']②用空格
(1)html body div div div div div form span input
(2)html body div div div div div form span input[value='百度一下']实例代码
(1)WebElement searchBox = driver.findElement(By.cssSelector( "html>body>div>div>div>div>div>form>span>input" ));
(2)WebElement SearchButton = driver.findElement(By.cssSelector("html>body>div>div>div>div>div>form>span>input[value='百度一下']"));缺点:此方法缺点显而易见,当页面元素位置发生改变时,都需要修改,因此,并不推荐使用绝对路径的写法。
2、相对路径
格式:xxx.By.cssSelector("标签[属性='']")
CSS表达式
(1)*[id="kw"]
(2)*[id="su"]实例代码
(1)WebElement SearchBox = driver.findElement(By.cssSelector( "*[id='kw']" ));
(2)WebElement SearchButton = driver.findElement(By.cssSelector("*[id='su']"));3、使用class名称定位
格式:xxx.By.cssSelector("标签.class名称")
CSS表达式:
(1)input.s_ipt
(2)input.btn 实例代码
(1)WebElement SearchBox = driver.findElement(By.cssSelector( "input.s_ipt" ));
(2)WebElement SearchButton = driver.findElement(By.cssSelector("input.btn"));拓展
使用浏览器调试工具,可以直接获取CSS语句,如下图

七、总结
| 方法 | 语法 | 描述 |
|---|---|---|
| id | driver.findElement(By.id(String id)) | 使用页面元素的id属性 |
| name | driver.findElement(By.name(String name)) | 使用页面元素的name属性 |
| className | driver.findElement(By.className(String class)) | 使用页面元素的类名属性 |
| tagName | driver.findElement(By.tagName(String tag)) | 使用页面元素的HTML的标签名属性 |
| linkText | driver.findElement(By.linkText(String text)) | 使用页面链接元素的文字属性(全部对应文字内容) |
| partialLinkText | driver.findElement(By.partialLinkText(String text)) | 使用页面链接元素的文字属性(包含部分文字内容) |
| xpath | driver.findElement(By.xpath(String xpath) | 使用xpath定位 |
| cssSelector | driver.findElement(By.cssSelector(String css)) | 使用CSS选择器定位 |
遵循原则:
1.若id和name在html中是唯一的,则优先使用这2种。
2.使用css或xpath,他们都很灵活,但语法复杂。Xpath性能应该是最慢的。
3.link text、partial link text缺点在于只对连接元素起作用。
4.class name不支持复合类名的元素。
5.tag name是危险的方法,因为一个页面上有很多相同标签的元素。
若某种方法定位到多个元素,则会返回第一个元素。文章来源:https://www.toymoban.com/news/detail-859753.html
文章来源地址https://www.toymoban.com/news/detail-859753.html
到了这里,关于java+selenium自动化测试之8大常用定位方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!