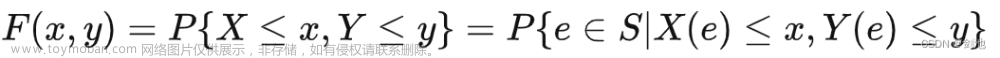文章信息

本周阅读的论文是一篇2012年发表在《Proceedings of the 2012 SIAM International Conference on Data Mining》上关于概率矩阵分解的文章,题目为《Kernelized Probabilistic Matrix Factorization Exploiting Graphs and Side Information》。

摘要

我们提出了一种新的矩阵补全算法——核化概率矩阵分解(Kernelized Probabilistic Matrix Factorization,KPMF),它有效地将外部辅助信息纳入矩阵分解过程中。与概率矩阵分解(Probabilistic Matrix Factorization,PMF)不同,PMF假设每行(以及每列)都有独立的潜在向量,并采用高斯先验;而KMPF使用具有高斯过程(Gaussian Process,GP)先验的潜在向量跨越所有行(以及列)。因此,KPMF明确地捕捉了跨行和列的底层(非线性)协方差结构。这一关键差异在适当的辅助信息(例如,在推荐系统中的用户社交网络)被纳入时,极大地提升了KPMF的性能。此外,高斯过程先验允许KPMF模型仅基于辅助信息就填充原始矩阵中完全缺失的行,而这对于标准的PMF公式是不可行的。在我们的论文中,我们主要处理带有行和/或列之间图形的矩阵补全问题作为辅助信息,但所提出的框架也可以轻松地与其他类型的辅助信息一起使用。最后,我们通过两种不同的应用展示了KPMF的有效性:1)推荐系统和2)图像恢复。

介绍

缺失值预测的问题,尤其是矩阵补全在许多研究领域已经得到解决,比如推荐系统、地质统计学和图像恢复。给定一个带有缺失值的大小为 的数据矩阵,目标是正确地添加缺失的条目,使它们与现有数据一致,其中现有数据可能包括数据矩阵中观察到的条目以及依赖于特定问题域的副信息。
的数据矩阵,目标是正确地添加缺失的条目,使它们与现有数据一致,其中现有数据可能包括数据矩阵中观察到的条目以及依赖于特定问题域的副信息。
在现有的矩阵补全技术中,基于因子分解的算法已经取得巨大成功和普及。这些算法中,矩阵的每一行,以及每一列,都有一个潜在向量,通过分解部分观察到的矩阵得到。因此,每个缺失条目的预测是对应行和对应列的潜在向量的内积。然而,这些技术经常会遇到现实场景中的数据稀疏性问题。例如,在多数商业推荐系统中,非缺失评分的密度小于1%,基于如此少的数据量进行缺失值预测是非常困难的。另一方面,除了数据矩阵,其他信息资源,比如推荐系统中用户的社交网络,有时很容易获得,并且可以提供有关底层模型的关键信息,而许多现有的分解技术只是忽略了这些侧面信息,或者本质上不能利用它。
为了解决这些缺陷,作者提出了一个核概率矩阵分解(KPMF),它通过核矩阵在行和列上合并侧信息。KPMF将一个矩阵建模为两个潜在矩阵,他们分别从两个不同的零均值高斯过程(GP)采样获得。GPs的协方差函数从侧信息中提取获得,并且分别编码跨行和跨列的协方差结构。在这篇文章中,作者从无向图(即用户社交网络)中提取协方差函数。然而,文章的通用框架还可以整合其他类型的侧信息。比如,当侧信息来自于特征向量,使用RBF核作为协方差函数可能是一种有效的方法。
虽然KPMF看上去与概率矩阵分解(PMF)以及其广义对应的贝叶斯PMF高度相关,使KPMF成为更强大的模型的关键区别在于,PMF/BPMF为每一行假设一个独立的潜在向量,而KPMF则使用跨越所有行的潜在向量。因此,与PMF/BPMF不同,KPMF能够显式地捕捉行间的协方差。另外,如果数据矩阵一整行的数据缺失,PMF/BPMF无法对其进行预测;相反,作为基于协方差函数的非参数模型,KPMF仍然可以仅基于行协方差进行预测。相似的,上述性质对于列也适用。
文章通过两个应用阐述KPMF:1)推荐系统以及2)图像复原。对于推荐系统,侧信息是用户社交网络;对于图像复原,侧信息来源于空间平滑假设,即小领域间的变化趋向于小且相关。实验表明KPMF始终优于最先进的协同过滤算法,并产生有希望的图像恢复结果。

参数介绍

1. 符号
尽管提出的KPMF模型适用于其他矩阵补全问题,文章还是以推荐系统为例,给出相应的符号和说明。其中,这篇文章使用的主要符号如下:

2. PMF和BPMF
给定一个形状为 ,且具有一定数量缺失值的实值矩阵R,矩阵补全的目标是预测矩阵的缺失值。概率矩阵分解(PMF)通过矩阵分解解决这个问题。假设两个潜在矩阵:
,且具有一定数量缺失值的实值矩阵R,矩阵补全的目标是预测矩阵的缺失值。概率矩阵分解(PMF)通过矩阵分解解决这个问题。假设两个潜在矩阵: 和
和 ,分别捕捉矩阵R的行列特征,那么PMF的生成过程如下所示:
,分别捕捉矩阵R的行列特征,那么PMF的生成过程如下所示:
1)对矩阵R的每一行n,生成
 ,其中I表示单位矩阵;
,其中I表示单位矩阵;
2)对矩阵R的每一列m,生成
 ;
;
3)对于每个未缺失的条目(n,m),生成 。
。
该模型的参数 和
和 具有零均值球面高斯先验,每个条目
具有零均值球面高斯先验,每个条目 从一个多元高斯分布生成,其中均值由
从一个多元高斯分布生成,其中均值由 和
和 的内积决定。潜在矩阵U和V的对数后验给定如下:
的内积决定。潜在矩阵U和V的对数后验给定如下:

其中, 表示一个指示指标,如果
表示一个指示指标,如果 是一个可观测的条目,则取1;否则取0。A是R中没有缺失数值的条目的数量,C是一个不依赖于U和V的常数。MAP推理分别最大化U和V的最大似然,可以被用于预测数据矩阵R中的缺失条目。
是一个可观测的条目,则取1;否则取0。A是R中没有缺失数值的条目的数量,C是一个不依赖于U和V的常数。MAP推理分别最大化U和V的最大似然,可以被用于预测数据矩阵R中的缺失条目。
作为PMF的扩展,贝叶斯PMF(BPMF)为每个 和
和 引入了一个全贝叶斯先验。接着,
引入了一个全贝叶斯先验。接着, (
( 类似)从高斯分布
类似)从高斯分布 中采样获得,其中的超参数
中采样获得,其中的超参数 进一步从Gaussian-Wishart先验中采样获得。
进一步从Gaussian-Wishart先验中采样获得。

模型介绍

KPMF
文章提出一个核概率矩阵分解(KPMF)模型,并提出梯度下降和随机梯度下降方法用于学习模型。

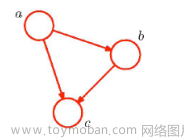
图1:(a)PMF中生成R的过程;(b)KPMF中生成R的过程
在KPMF中,潜在矩阵每一列的先验分布 和
和 服从均值为0的高斯过程。高斯过程是多元高斯分布的推广。一个多元高斯分布由一个均值向量和一个协方差矩阵决定,而高斯过程
服从均值为0的高斯过程。高斯过程是多元高斯分布的推广。一个多元高斯分布由一个均值向量和一个协方差矩阵决定,而高斯过程 由一个均值函数
由一个均值函数 和一个协方差函数
和一个协方差函数 决定。在文章的问题背景下,x是一个矩阵行(列)的索引。不失一般性,令
决定。在文章的问题背景下,x是一个矩阵行(列)的索引。不失一般性,令 ,
, 表示相关的核函数,表示任何行(或列)间的协方差。同时,令
表示相关的核函数,表示任何行(或列)间的协方差。同时,令 和
和 分别表示R中行和列的全协方差矩阵。在先验中使用
分别表示R中行和列的全协方差矩阵。在先验中使用 和
和 以进行潜在因子分解可以同时捕获行之间和列之间的潜在协方差。
以进行潜在因子分解可以同时捕获行之间和列之间的潜在协方差。
假设 和
和 已知,KPMF的生成过程如下所示。
已知,KPMF的生成过程如下所示。
1)生成 ;
;
2)生成 ;
;
3)对于每个没有缺失的条目 ,生成
,生成
 ,其中是一个常数。
,其中是一个常数。
给定潜在矩阵U和V,目标矩阵R中观测到的条目的似然函数如下:

其中U和V的先验给定如下:

为了简单起见,通过 定义
定义 ,通过定义
,通过定义 。因此U和V的对数后验分布给定如下:
。因此U和V的对数后验分布给定如下:

其中,A是R中非缺失条目的数量,是K的行列式,C是一个常数项,与潜在矩阵U和V无关。

图2:(a)在PMF/BPMF中,U是以“row-wise”的方式进行采样;(b)在KPMF中,U是以“column-wise”的方式进行采样
2. KPMF v.s. PMF/BPMF
图2解释了KPMF和PMF/BPMF间的差异。在PMF/BPMF中,U以一种“row-wise”的方式进行采样,即 对R中的每一行进行采样,
对R中的每一行进行采样, 在给定先验条件下是条件独立的。因此,行间的关联性在模型中没有被捕捉。相反,在KPMF,U以一种“column-wise”的方式进行采样,即对于每一个D潜在因素,
在给定先验条件下是条件独立的。因此,行间的关联性在模型中没有被捕捉。相反,在KPMF,U以一种“column-wise”的方式进行采样,即对于每一个D潜在因素, 对R中的所有行进行采样。具体来说,
对R中的所有行进行采样。具体来说, 从一个高斯过程中采样而得,其中协方差
从一个高斯过程中采样而得,其中协方差 捕捉了行的相关性。通过这种方式,在训练过程中,每一行的潜在因子
捕捉了行的相关性。通过这种方式,在训练过程中,每一行的潜在因子 通过
通过 与其他行的潜在因子
与其他行的潜在因子 进行关联。如果两行潜在因子根据侧信息共享一些相似性,相关的潜在因子在经过训练后也会比较相似,这是在给定侧信息的情况下希望直观达到的效果。相似的,这些描述同样适用于V和R的每一列。KPMF和BPMF的差异是很微小的,但他们实际上是完全不同的模型,并且不能视为彼此的特殊情况。PMF是两种模型的一个简单的特殊例子,既没有跨行相关性,也没有捕获潜在因素之间的相关性。
进行关联。如果两行潜在因子根据侧信息共享一些相似性,相关的潜在因子在经过训练后也会比较相似,这是在给定侧信息的情况下希望直观达到的效果。相似的,这些描述同样适用于V和R的每一列。KPMF和BPMF的差异是很微小的,但他们实际上是完全不同的模型,并且不能视为彼此的特殊情况。PMF是两种模型的一个简单的特殊例子,既没有跨行相关性,也没有捕获潜在因素之间的相关性。
PMF和BPMF中的行和列的独立性极大削弱了模型的功能,因为在实际场景中,行(列)之间往往存在很强的相关性。例如,在推荐系统中,用户对商品的评分(通过行表示)很可能被具有社会关系的其他用户(朋友、家庭等)所影响。PMF和BPMF难以捕捉这种关联的依赖性,而文章提出的KPMF在这方面具有更优的性能。
3. 用于KPMF的梯度下降
文章通过MAP估计来学习潜在矩阵U和V,它们在前文最大化对数后验,相当于最小化以下的目标函数:

最小化目标函数E可以通过梯度下降实现。具体来说,梯度给定如下:

其中, 表示一个N维的单位向量,第n个元素取值为1,其他为0。U和V的更新如下所示:
表示一个N维的单位向量,第n个元素取值为1,其他为0。U和V的更新如下所示:

其中,表示一个学习率。算法通过上述两个等式分别更新U和V直到收敛。需要注意的是,由于 和
和 在整个迭代过程中保持固定,所以
在整个迭代过程中保持固定,所以 和需要在初始化计算一次即可。
和需要在初始化计算一次即可。
先假设R中的一整行或列缺失。虽然PMF和BPMF无法解决这种问题,但是只要给定合适的侧信息,KPMF仍然可以有效解决该问题。在这种情况下,上述更新过程变为

在这种情况下,相应 的更新是基于当前状态下U的所有行的加权平均,包括那些全部缺失的行和没有缺失的行,且权重
的更新是基于当前状态下U的所有行的加权平均,包括那些全部缺失的行和没有缺失的行,且权重 反映了当前行n与其他行的相关性。这对于V和列都一样。
反映了当前行n与其他行的相关性。这对于V和列都一样。
4. 用于KPMF的随机梯度下降
由于随机梯度下降(SGD)的收敛通常快于梯度下降,因此文章同样推导了使用SGD更新KPMF。这种情况下,我们可以将前文梯度下降中的目标函数改写为:

其中, 表示矩阵X的迹,另外,
表示矩阵X的迹,另外,

相似的,

因此,目标函数可以转化为


其中, 是第n行中未缺失条目的数量,
是第n行中未缺失条目的数量, 是第m列中未缺失条目的数量。最后,对于每一个没有缺失的条目(n, m),
是第m列中未缺失条目的数量。最后,对于每一个没有缺失的条目(n, m), 关于
关于 和
和 的梯度分别是:
的梯度分别是:

5. 利用对角核学习KPMF
如果 和
和 均为对角矩阵,意味着行和列均是独立同分布,那么KPMF就会退化为PMF。如果仅有一个核是对角的,那么对应的潜在矩阵可以被边缘化,从而仅在一个潜在矩阵上产生MAP推理问题。为了解释这个情况,假设
均为对角矩阵,意味着行和列均是独立同分布,那么KPMF就会退化为PMF。如果仅有一个核是对角的,那么对应的潜在矩阵可以被边缘化,从而仅在一个潜在矩阵上产生MAP推理问题。为了解释这个情况,假设 是对角的
是对角的 ,那么R中每一列的似然函数给定如下:
,那么R中每一列的似然函数给定如下:

其中, 表示第m列中未缺失条目的行索引,如果一共有个未缺失值的条目在第m列,
表示第m列中未缺失条目的行索引,如果一共有个未缺失值的条目在第m列, 是一个维向量,
是一个维向量, 是一个
是一个 的矩阵,每一行对应第m列中一个未缺失的条目。由于
的矩阵,每一行对应第m列中一个未缺失的条目。由于 ,可以对V求边际获得
,可以对V求边际获得

目标函数转变为:

其中, 。另外,由于V在目标函数中不再是一项,因此梯度下降仅仅在U中进行。但是,在该例子中,每次迭代中更新U涉及到C的逆,当N很大时就变得难以计算,因此本文在实验中不使用这种范式。
。另外,由于V在目标函数中不再是一项,因此梯度下降仅仅在U中进行。但是,在该例子中,每次迭代中更新U涉及到C的逆,当N很大时就变得难以计算,因此本文在实验中不使用这种范式。
6. 预测
基于梯度下降或随机梯度下降的学习可以有效估计潜在矩阵和。对于任意缺失的条目 ,最大似然估计是相应潜向量的内积,即
,最大似然估计是相应潜向量的内积,即 。
。
7. 核函数选择
(1)基于图的核。为了构建合适的核矩阵以适应文章所研究的问题,作者使用用户社交网络作为一个无向、无权重图G,其中节点和边分别代表用户和他们之间的连接。G的邻阶矩阵的元素表示为,如果用户i和用户j间存在一条边,则取值为1,否则为0。G的拉普拉斯矩阵定义为 ,其中度矩阵D是一个对角矩阵,其对角元素表示为
,其中度矩阵D是一个对角矩阵,其对角元素表示为 。
。
基于图的核提供了一种捕获图中节点之间复杂结构的方法。在文章的案例中,基于图的核定义了用户对某种商品的品味的相似度。通常来说,用户与他们的朋友和家庭通常有相似的品味,因此对于同一件物品的评分应该是存在关联性的。基于图的核可以在社交网络上捕捉这种效应,得到的核矩阵提供了关于用户评分模式的关键信息。
(2)扩散核。扩散核来源于矩阵指数的思想,对热量等物质的扩散过程有很好的解释。具体来说,如果在节点i注入某些物质并沿图的边流动, 可以被认为稳定状态下在节点j处积累的物质量。扩散核直观地捕获了图中节点之间的全局结构,计算方法如下:
可以被认为稳定状态下在节点j处积累的物质量。扩散核直观地捕获了图中节点之间的全局结构,计算方法如下:

其中,是一个带宽参数以决定扩散的规模( 表示没有扩散)。
表示没有扩散)。
(3)通勤时间核。通勤时间核与所谓的平均通勤时间(随机步行者在图中的两个节点之间通勤所需的步数)密切相关,可以使用拉普拉斯矩阵的伪逆来计算: 。另外,由于
。另外,由于 是条件正定的,
是条件正定的, 就像图中节点的欧式距离。因此,节点可以等距嵌入到大小为的子空间中(n是节点的数量),其中节点间的欧氏距离为
就像图中节点的欧式距离。因此,节点可以等距嵌入到大小为的子空间中(n是节点的数量),其中节点间的欧氏距离为 。
。
(4)正则化拉普拉斯核。通过引入一种在图上执行正则化的方法,惩罚相邻节点之间的变化。具体来说,图的拉普拉斯算子可以被等价地定义为图的节点上的线性算子,并在自然地推导出一个半范数。这个半范数量化了相邻节点的变化,可用于设计正则化算子。另外,这种正则化算子产生了一组图核,其中包括正则化拉普拉斯核:


实验研究

文章在两个真实世界的数据集上进行了实验来测试KPMF在矩阵补全方面的有效性,数据集包括社交电影网站数据和用户评论网站数据。实验结果表明,相比于现有先进的方法,KPMF在平均绝对误差和均方根误差等常见指标上,具有更好的性能和精度。感兴趣的读者可以阅读原文实验部分。

结论

本文提出一个全新的矩阵补全算法KPMF,它同时利用数据矩阵的行和列之间的潜在协方差进行缺失值预测。KPMF在生成模型中为潜在矩阵引入高斯过程先验,使学习到的潜在矩阵遵从行、列间的协方差结构,有效整合了侧信息。如实验结果所示,这一特性在提高模型性能方面起着至关重要的作用,特别是当观察到的数据矩阵是稀疏的时候。文章来源:https://www.toymoban.com/news/detail-859857.html
KPMF的另一个优点是即使在整行或整列缺失的情况下,只要给定相应的侧信息,就可以完成缺失值的预测。原则上,KPMF适用于一般的矩阵补全问题,但本文主要关注两个特定的应用:推荐系统和图像恢复。在未来的工作中,可以推广当前的模型来处理加权条目的情况,其中不同的条目根据一些预定义的标准被分配不同的权重。文章来源地址https://www.toymoban.com/news/detail-859857.html
到了这里,关于利用图和侧信息的核概率矩阵的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!