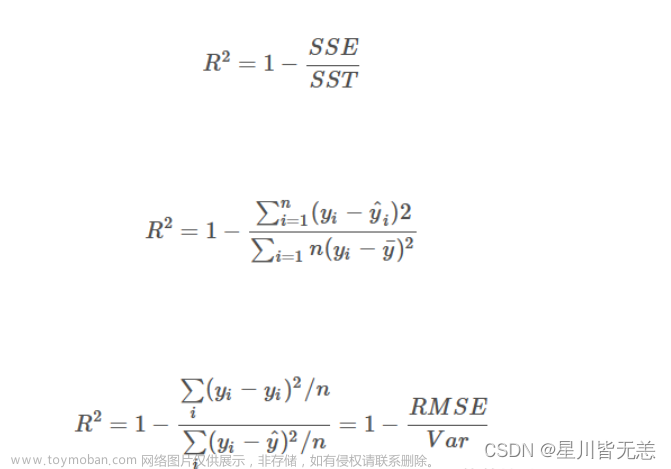1分析
回归当中的数据大小不一致,是否会导致结果影响较大。所以需要做标准化处理。
- 数据分割与标准化处理
- 回归预测
- 线性回归的算法效果评估
2回归性能评估
均方误差(Mean Squared Error)MSE)评价机制:
注:y^i为预测值,y-为真实值
- sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均方误差回归损失
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
3代码


我们也可以尝试去修改学习率
estimator =SGDRegressor(learning_rate='constant',eta0=0.001)
此时我们可以通过调参数,找到学习率效果更好的值。
4正规方程和梯度下降对比

- 文字对比
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要迭代求解 | 一次运算得出 |
| 特征数量较大可以使用 | 需要计算方程,时间复杂度高O(n3) |
- 选择:
- 小规模数据:
- LinearRegression(不能解决拟合问题)
- 岭回归
- 大规模数据:SGDRegressor
- 小规模数据:
拓展-关于优化方法GD、SGD、SAG
1、GD 梯度下降,原始的梯度下降法需要计算所有样本的值才能够得出梯度,计算量大,所以后面才有会一系列的改进。
2、SGD随机梯度下降。它在一次迭代时只考虑一个训练样本。文章来源:https://www.toymoban.com/news/detail-859878.html
- SGD的优点是:
- 高效
- 容易实现
- SGD的缺点是:
- SGD需要许多超参数:比如正则项参数、选代数
- SGD对于特征标准化是敏感的。
3、SAG随机平均梯度法,由于收敛的速度太慢,有人提出SAG等基于梯度下降的算法。
Scikit-learn:岭回归、逻辑回归等当中都会有SAG优化文章来源地址https://www.toymoban.com/news/detail-859878.html
到了这里,关于回归与聚类——性能评估(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!