SHAP(SHapley Additive exPlanations)作为一种解释机器学习模型输出的方法,基于Shapley值理论,通过将模型预测结果分解为每个特征的贡献,为模型提供全局和局部的可解释性。

SHAP作为机器学习模型的解释工具,已经是一项重大突破。
在处理医学问题时,我们往往通过构建模型,来寻找病因。此处,会有歧义,谈谈个人见解,此种解释并非因果关系,与Logistic回归的OR值有区别,此种解释不是因果解释,我们不能因为预测变量shap值贡献大,而认为这个变量是结局变量的危险因素。这种关系,只能说明由于变量的贡献,能在多大程度上增加预测模型的准确率。
当前阶段,SHAP实现方法,大多数是基于Python,随着算法的流行,R语言也有了相关的SHAP解释。但是R的SHAP解释,目前应用的包是shapviz,这个包仅能对Xgboost、LightGBM以及H2O模型进行解释,其余的机器学习模型并不适用。

这里通过举例,来展示shap模型的R实现:
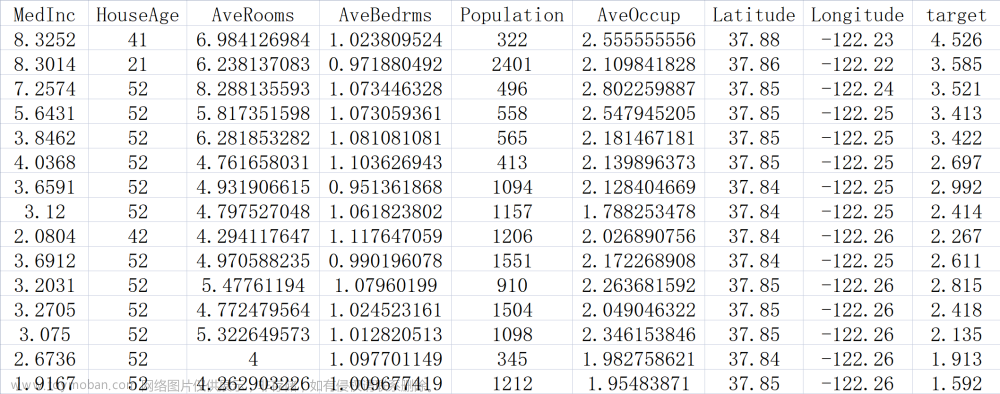
通过Xgboost模型来预测结直肠癌肝转移。最后一列是Liver,0代表未转移,1代表肝转移
1.加载相关的包,读入数据
#install.packages("shapviz")
library(shapviz)
#install.packages("xgboost")
library(xgboost)
library(caret)
library(pROC)
library(tibble)
library(ROCit)
data =read.csv("data.csv",header = T,check.names = F)2.通过caret包划分训练集和测试集数据
# 划分训练集和测试集
set.seed(123)#设置随机数
inTrain<-createDataPartition(y=data[,"Liver"], p=0.7, list=F)#划分训练集,设置训练集的比例为0.7
traindata<-data[inTrain,]#提取训练集数据
testdata<-data[-inTrain,]#提取验证集数据3.构建Xgboost模型
model_xgboost = xgboost(
data = as.matrix(traindata[,c(1:(ncol(traindata)-1))]),#训练集的自变量矩阵
label = traindata$Liver,
max_depth = 3,
eta = 1,
nthread = 2,
nrounds = 10,
objective = "binary:logistic")4.模型的预测结果
#生成预测值
traindata$pred <- predict(model_xgboost, as.matrix(traindata[,c(1:(ncol(traindata)-1))]))
#计算AUC
ROC_train <- round(auc(response=traindata$Liver,predictor=traindata$pred),4)
ROC_train
#计算置信区间
CI_train=ci(response=traindata$Liver,predictor=traindata$pred)
CI_train
#通过那个paste0连接
AUC_CI_train=paste0("AUC=",round(CI_train[2],3),",95%CI (",round(CI_train[1],3)," - ",round(CI_train[3],3),")")
AUC_CI_train5.绘制ROC曲线
这里美化图片的原因是,中华系列杂志需要这样去绘图。
#整理数据,美化图片
ROC_data <- rocit(score=traindata$pred,class=traindata$Liver)
m1=tibble(
name="Model",
TPR=ROC_data$TPR,
FPR=ROC_data$FPR,
AUC=AUC_CI_test
)
pdf("ROC_train.pdf",5,5,family = "serif")
ggplot(m1,aes(x = FPR, y = TPR)) +
geom_path() +
labs(title= " ",
x = "False Positive Rate (1-Specificity)",
y = "True Positive Rate (Sensitivity)")+
geom_abline(lty = 3) +
theme_classic()+
annotate("text", x = 0.6 , y = 0.2,label = AUC_CI_test,colour="black")+
scale_y_continuous(expand=c(0,0))+
scale_x_continuous(expand=c(0,0))+
theme(
axis.ticks.length=unit(-0.1, "cm"),
legend.position = c(0.7, 0.2),
legend.title = element_blank(),
strip.background = element_blank(),
text = element_text(size = 15,color="black")#face="bold"
)
6.计算shap值并绘图

#单个样本力图
sv_force(shap_xgboost,row_id = 2)
#去掉图片灰色背景
sv_importance(shap_xgboost,kind = "beeswarm")+theme_bw()这里图片的背景是灰色的,这里的函数均是基于ggplot2绘制的,因此我们可以通过添加theme主题函数,来修改图片的背景
#变量重要性柱状图sv_importance(shap_xgboost)+theme_bw()

sv_dependence(shap_xgboost, "T",alpha = 0.5,size = 1.5,color_var = NULL)+theme_bw()

#多个变量偏相关依赖图
sv_dependence(shap_xgboost,
v = c("Sex",
"Grade",
"Histologic",
"Surg"))+theme_bw() 文章来源:https://www.toymoban.com/news/detail-860045.html
文章来源:https://www.toymoban.com/news/detail-860045.html
以上就是R的Xgboost模型的SHAP解释。【公众号:小庞统计】文章来源地址https://www.toymoban.com/news/detail-860045.html
到了这里,关于机器学习模型SHAP解释——R语言的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!