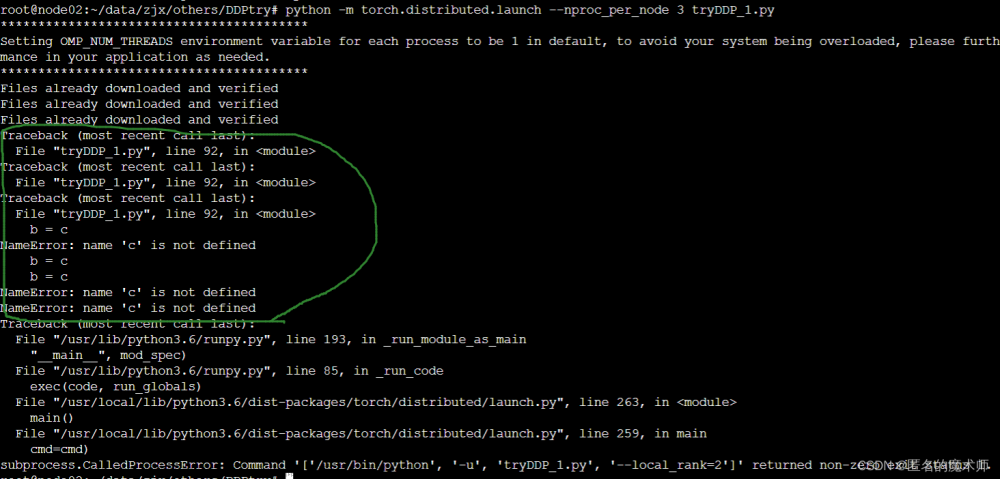
最近遇到个头疼的问题,对于单机多卡的训练脚本,不知道如何使用VSCode进行Debug。
解决方案:
1、找到控制分布式训练的启动脚本,在自己的虚拟环境的/lib/python3.9/site-packages/torch/distributed/launch.py中
2、配置launch.josn文件,按照正确的参数顺序,填入args参数,注意区分位置参数和可选参数,debug文件前面的参数是分布式训练的参数,后面为该文件所需的参数。这个顺序和命令行执行的顺序一致,所以可参考命令行的顺序
 文章来源:https://www.toymoban.com/news/detail-860309.html
文章来源:https://www.toymoban.com/news/detail-860309.html
3、选择到文件,开始debug,选择该配置 launch.josn文件文章来源地址https://www.toymoban.com/news/detail-860309.html
到了这里,关于【VSCode调试技巧】Pytorch分布式训练调试的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!