原文链接:https://arxiv.org/abs/2308.05026
I. 引言
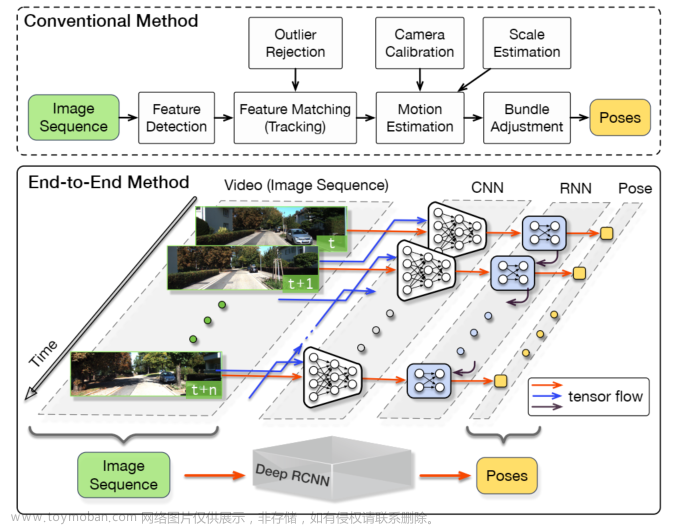
目前的轨迹预测方法多基于道路使用者的真实信息,但在实际自动驾驶系统中这些信息是通过检测和跟踪模块得到的,不可避免的存在噪声。本文将感知模块与轨迹预测整合,进行端到端的检测、跟踪和轨迹预测。
本文感知模块使用单目图像输入,以QD-3DT为基础模型,能有效关联运动智能体并估计3D边界框。预测模块则使用感知模块输出的2D位置信息,使用DCENet作为基础模型,利用注意力机制和条件变分自编码器预测智能体的多模态轨迹。此外,本文将DCENet扩展为以智能体的位置、尺寸和姿态作为输入,并使用感知模块的估计结果作为输入,因此被称为DCENet++。
本文的方法称为ODTP(在线检测、跟踪、预测),流程如上图所示。
III. 方法
A. 问题表达
本文以单目图像序列为输入,检测模块输出每个时刻的3D边界框集合 S t = { s 1 t , ⋯ , s J t } S^t=\{s_1^t,\cdots,s_J^t\} St={s1t,⋯,sJt}。在多目标跟踪模块进行数据关联和运动细化后,得到光滑轨迹集合 T = { τ 1 , ⋯ , τ N } \mathbb T=\{\tau_1,\cdots,\tau_N\} T={τ1,⋯,τN}(其中 τ i ∈ R T × 2 \tau_i\in\mathbb R^{T\times 2} τi∈RT×2),以及细化的边界框集合 S t = { s 1 t , ⋯ , s N t } \mathbb S^t=\{s_1^t,\cdots,s_N^t\} St={s1t,⋯,sNt}。 N < J N<J N<J为跟踪的智能体数量, T ≥ 2 T\geq2 T≥2为时间范围。随后, T \mathbb T T和 S \mathbb S S被送入轨迹预测模块,预测可能的未来轨迹集合 { Y ^ i , 1 T + 1 : T ′ , ⋯ , Y ^ i , K T + 1 : T ′ } \{\hat Y_{i,1}^{T+1:T'},\cdots,\hat Y_{i,K}^{T+1:T'}\} {Y^i,1T+1:T′,⋯,Y^i,KT+1:T′},其中 i ∈ { 1 , ⋯ , N } i\in\{1,\cdots,N\} i∈{1,⋯,N}为智能体索引, K K K为预测轨迹数量, T ′ − T T'-T T′−T为预测的时间范围。
B. QD-3DT
QD-3DT以图像和GPS/IMU信息为输入(后者用于定位自车),将各智能体的3D信息变换到自车坐标系下。图像首先会通过主干和RPN得到2D RoI,RoI会进一步输入两个预测头,分别得到相似性特征嵌入和3D布局。为进行跟踪,利用3D信息、运动信息和特征嵌入计算跟踪轨迹之间的多模态相似度指标,并进行运动感知的数据关联和深度排序的匹配技巧以减轻遮挡问题。最后,物体的3D信息会被细化。
C. DCENet++
与DCENet相比,本文使用估计的智能体位置、尺寸和朝向为输入以获取细化的动态地图。如下图所示(从左到右分别为不考虑大小和朝向、仅考虑大小、同时考虑大小和朝向)。注意仅考虑BEV下的2D信息。
D. 联合3D跟踪和预测
得到轨迹 T = { τ 1 1 : T , ⋯ , τ N 1 : T } \mathbb T=\{\tau^{1:T}_1,\cdots,\tau^{1:T}_N\} T={τ11:T,⋯,τN1:T}和 T T T时刻的边界框 S T = { s 1 T , ⋯ , s N T } \mathbb S^T=\{s_1^T,\cdots,s_N^T\} ST={s1T,⋯,sNT}后,本文将DCENet++的批量大小设置为 N N N,并根据 S T \mathbb S^T ST将各智能体投影到动态地图的网格中,将位置、速度、姿态信息放入不同通道。同时,各智能体的偏移量序列 Δ X i 1 : T − 1 = { Δ x i 1 , ⋯ , Δ x i T − 1 } ∈ R ( T − 1 ) × 2 \Delta X_i^{1:T-1}=\{\Delta x_i^1,\cdots,\Delta x_i^{T-1}\}\in\mathbb R^{(T-1)\times 2} ΔXi1:T−1={Δxi1,⋯,ΔxiT−1}∈R(T−1)×2会与动态图序列组合,作为预测模块的联合条件,预测多模态轨迹 { Y ^ i , 1 T + 1 : T ′ , ⋯ , Y ^ i , K T + 1 : T ′ } \{\hat Y_{i,1}^{T+1:T'},\cdots,\hat Y_{i,K}^{T+1:T'}\} {Y^i,1T+1:T′,⋯,Y^i,KT+1:T′}。
IV. 实验
B. 评估指标
MOT指标:使用AMOTA(组合FP、FN和IDS指标)和AMOTP(衡量定位精度)。
轨迹预测指标:使用平均位移误差(ADE,预测轨迹和真实轨迹的欧式距离)和最终位移误差(FDE,预测轨迹和真实轨迹最终点的距离)。使用 K K K个预测轨迹的ADE/KDE最小值作为最终预测结果。
C. 实验设置
为减小积累的跟踪误差,本文使用下一步的预测边界框计算轨迹和检测物体状态的亲和度,而非连续预测物体状态。
V. 结果
A. 感知性能
实验表明,本文对QD-3DT做出的改进能提高跟踪性能。
B.轨迹预测性能
实验表明,在动态地图中引入物体的尺寸和朝向能达到最高的性能,但单独使用之一带来的性能提升并不明显(因为缺少信息会导致动态图的次优对齐)。
此外,DCENet++能超过现有方法的性能。
若在MOT得到的轨迹上进行测试,则在真实轨迹上进行训练的模型性能 与 在MOT得到的轨迹上训练的模型 相比会有大幅下降。这说明在真实轨迹上训练的模型泛化能力差,无法处理实际系统中的噪声。若在MOT得到的轨迹上进行训练,在真实轨迹上进行测试,性能仅略低于在真实轨迹上训练和测试的性能。
C. 定性结果
可视化表明,本文方法能在输出轨迹含噪声的情况下预测更光滑的轨迹。文章来源:https://www.toymoban.com/news/detail-860411.html
局限性:本文的方法必须分开训练感知模块和轨迹预测模块,且无法共享中间特征图。此外,当感知模块出现漏检时,预测模块不能处理。文章来源地址https://www.toymoban.com/news/detail-860411.html
到了这里,关于【论文笔记】An End-to-End Framework of Road User Detection, Tracking, and Prediction from Monocular Images的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!