最近十年中,各类因果推断方法层出不穷。令人欣喜的同时,也让很多人无所适从。虽然借助 Stata,R,Python 等软件很容易「跑出」结果,但很多人应该都经历过如下「囧境」:
-
虽然有很多方法可以用,但由于不清楚原理,不知道该用哪个?
-
虽然自己很努力地跑代码、看文献,但总感觉没啥实质性进展,有一种「有劲没处使」的无力感;
-
很像看看 QJE,AER,JoE,JASA 上那些牛逼的方法,但「一开始就懵了」……。
根源何在?可能是没有清晰地理解「基本概念」,比如条件期望,条件独立,无偏性以及 FWL 定理等。基础不牢,便会导致举步维艰。事实上,一旦理清基本概念和模型,后续的 Lasso,双重机器学习 (DML) 等听起来很高深的东西都不再困难,因为它们都是基础知识和理论的组合和延伸而已。
庄子所言「水之积也不厚,则其负大舟也无力」也正是这个意思。
为此,强基班 的目的在于巩固基础,理清 条件期望函数,条件独立,反事实架构,选择偏差 等基本概念;理解 识别、估计 和 统计推断 的差别。进而在因果推断的架构下讲解 OLS,IV,FE 以及 DID 等方法,让大家能够「选择合适的方法、做出合理的解释」。

编者按:本文参考自 Bryan Pfalzgraf 的 How to Use Selenium to Web-Scrape with Example,以及连享会课程 文本分析-爬虫-机器学习,特此致谢!
本推文将以爬取世界主要股票指数为例,简要介绍 Python 爬虫的方法。
1. Selenium
现在,很多网页通过使用 JavaScript 的 Ajax 技术实现了网页内容的动态改变。在碰到动态页面时,一种方法是精通JavaScript,并使用浏览器跟踪浏览器行为,分析 JavaScript 脚本,进而使用以上的方法模拟浏览器请求。但是这种方法非常复杂,很多时候 JavaScript 可能会复杂到一定程度,使得分析异常困难。
另外一种方法是使用 Selenium 直接调用浏览器,浏览器自动执行 JavaScript,然后调用浏览器的 HTML 即可。这种方法非常方便,但是速度异常之慢。
为了实现这一方法,我们首先要安装 selenium:pip install selenium。selenium 是 Python 中用来自动调用浏览器的一个包,在从网页中爬取数据的过程中可以不需要我们自己去寻找真正的网页源代码。
selenium 中一个重要的类是 webdriver,它能够自动化地打开一个网页,帮助我们自动化进行浏览网页。webdriver 支持 Google Chrome,Internet Explorer,Firefox,Safari 和 Opera。
这里以一个爬取 NBA 球员薪酬网站为例,简要说明 selenium 的使用方法。首先我们需要定义一个 driver 的变量,用来爬取数据的引擎。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pandas as pd
driver = webdriver.Chrome()
然后我们需要使用 Python 去打开一个我们想要爬取的网站。
driver.get('https://hoopshype.com/salaries/players/')
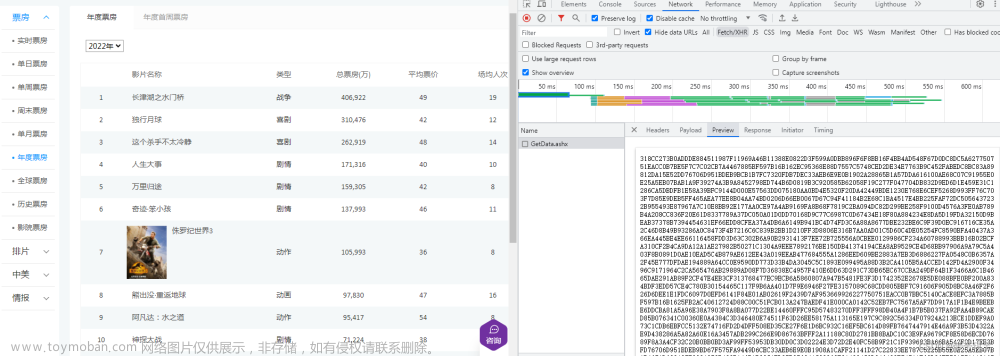
接下来我们需要定位爬取信息的位置,为了提取需要的信息,我们需要定位到这个信息元素的 XPath。XPath 是一个用来寻找一个网页中任何元素的语法,为了找到 XPath, 我们需要右击鼠标,然后选择 检查(inspect)。

我们可以看到 Stephen Curry 的 HTML 代码是:
<td class=”name”>
<a href=”https://hoopshype.com/player/stephen-curry/salary/">
Stephen Curry </a>
</td>
在将其转换成 XPath 之前,让我们再检查一下另外一个明星 Russell Westbrook:
<td class=”name”>
<a href=”https://hoopshype.com/player/russell-westbrook/salary/">
>Russell Westbrook </a>
</td>
可以看到两者的相似之处在于 <td class=”name”>,也就是说我们可以据此来得到所有明星的名字。我们将其转换为 XPath: //td[@class=”name”]。所有的 XPath 以两条 // 开始,然后我们需要 td 标签,以及 td 标签下的 name 类。
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://hoopshype.com/salaries/players/')
players = driver.find_elements(By.XPATH, '//td[@class="name"]')
players_list = []
for p in range(len(players)):
players_list.append(players[p].text)
通过相同的办法,我们也可以找到这些球星的薪水。
salaries_list = []
for item in salaries:
salaries_list.append(item.text)
df = pd.DataFrame(list(zip(players_list, salaries_list)))

2. 爬取雅虎财经数据
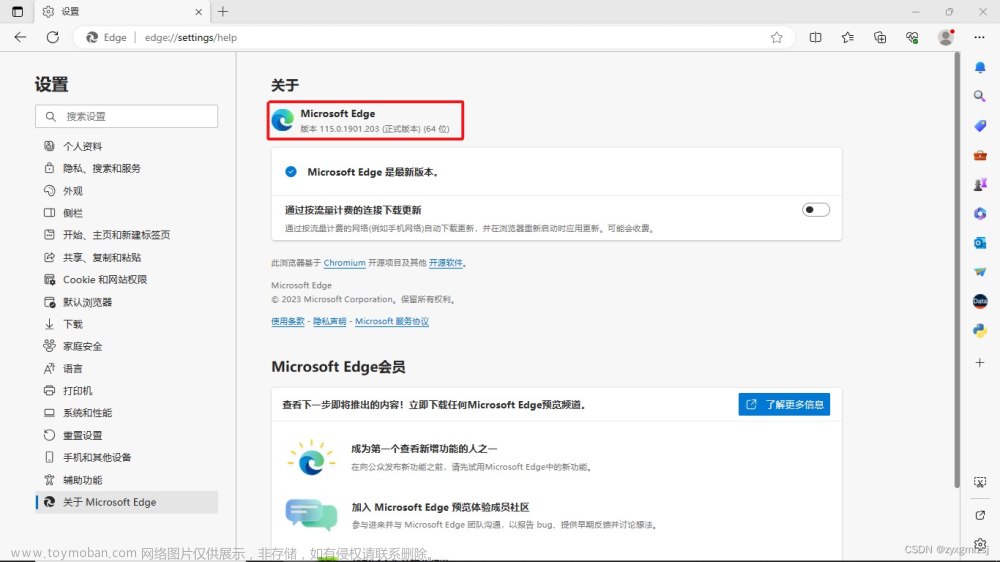
在了解如何使用 Selenium 之后,我们来爬取 Yahoo Finance 中的 世界主要股票指数。这次我们选择的浏览器是微软的 Edge 浏览器:
driver2 = webdriver.Edge()
这次采取和前文爬取 NBA 明星薪酬数据不太相同的方法,我们引入了 BeautifulSoup 包,将网页的 HTML 爬取下来。
driver2.get("https://finance.yahoo.com/world-indices/")
html2 = driver2.execute_script('return document.body.innerHTML;')
soup2 = BeautifulSoup(html2,'lxml')
接下来,我们按照前文的办法寻找对应的标签,以及标签下面的类,分别获得指数简称,指数全称,实时价格,价格数值变化,价格的百分比变化,以及成交量.
indices = [entry.text for entry in \
soup2.find_all("a", {"class":"Fw(600) C($linkColor)"})]
names = [item.text for item in \
soup2.find_all("td", {"class":"Va(m) Ta(start) Px(10px) Fz(s)","aria-label":"Name"})]
lastprice = [entry.text for entry in \
soup2.find_all("fin-streamer", {"data-test":"colorChange", "data-field":"regularMarketPrice"})]
change = [entry.text for entry in \
soup2.find_all("td", {"class":"Va(m) Ta(end) Pstart(20px) Fw(600) Fz(s)", "aria-label":"Change"})]
perc_change = [entry.text for entry in \
soup2.find_all("td", {"class":"Va(m) Ta(end) Pstart(20px) Fw(600) Fz(s)", "aria-label":"% Change"})]
volumne = [item.text for item in \
soup2.find_all("td", {"class":"Va(m) Ta(end) Pstart(20px) Fz(s)", "aria-label":"Volume"})]
df2 = pd.DataFrame((list(zip(indices, names, lastprice, change, perc_change, volumne))), \
columns=["indices", "names", "lastprice", "change", "perc_change", "volume"])

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典
 文章来源:https://www.toymoban.com/news/detail-860422.html
文章来源:https://www.toymoban.com/news/detail-860422.html
 文章来源地址https://www.toymoban.com/news/detail-860422.html
文章来源地址https://www.toymoban.com/news/detail-860422.html
简历模板
若有侵权,请联系删除 到了这里,关于Python:爬虫财经数据-selenium的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!