HiveServer2 & Beeline
一、HiveServer2服务
在启动Hive的时候,除了必备的Metastore服务外,我们前面提过有2种方式使用Hive:
- 方式1: bin/hive 即Hive的Shell客户端,可以直接写SQL
- 方式2: bin/hive --service hiveserver2
后台执行脚本:nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
bin/hive --service metastore,启动的是元数据管理服务
bin/hive --service hiveserver2,启动的是HiveServer2服务
HiveServer2是Hive内置的一个ThriftServer服务,提供Thrift端口供其它客户端链接
可以连接ThriftServer的客户端有:
- Hive内置的 beeline客户端工具(命令行工具)
- 第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等
HIve的客户端体系如下:
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-1.png)
启动
在hive安装的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
二、beeline
- 在node1上使用beeline客户端进行连接访问。需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务。
- Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://node1:10000
执行以下代码进行通信
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-2.png)
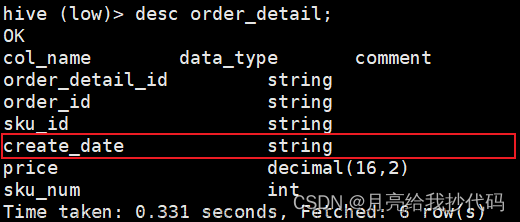
连接成功,查看数据库完毕
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-3.png)
DataGrip & DBeaver
一、Hive第三方客户端
DataGrip、Dbeaver、SQuirrel SQL Client等
可以在Windows、MAC平台中通过JDBC连接HiveServer2的图形界面工具;
这类工具往往专门针对SQL类软件进行开发优化、页面美观大方,操作简洁,更重要的是SQL编辑环境优雅;SQL语法智能提示补全、关键字高亮、查询结果智能显示、按钮操作大于命令操作;
二、DataGrip
DataGrip是由JetBrains公司推出的数据库管理软件,DataGrip支持几乎所有主流的关系数据库产品,如DB2、Derby、MySQL、Oracle、SQL Server等,也支持几乎所有主流的大数据生态圈SQL软件,并且提供了简单易用的界面,开发者上手几乎不会遇到任何困难
1、打开DataGrip,添加数据库
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-4.png)
2、连接测试,Host为HS2所在服务器主机名
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-5.png)
3、连接成功,在里面我们可以看到我们前面章节所创建的表,这样子就可以在里面操作我们的sql语句的。
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-6.png)
三、DBeaver
1、打开DBeaver,创建hive连接
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-7.png)
2、配置驱动,因为DBeaver里内置的驱动有点问题,需要我们手动的去编辑驱动。
删除所有库,上传hive-jdbc-3.1.2-standalone.jar驱动包,点击确定
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-8.png)
3、填下配置
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-9.png)
4、测试链接成功
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-10.png)
5、连接成功,在里面我们可以看到我们前面章节所创建的表,这样子就可以在里面操作我们的sql语句的。文章来源:https://www.toymoban.com/news/detail-860527.html
![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14],hadoop,hadoop,hive,大数据](https://imgs.yssmx.com/Uploads/2024/04/860527-11.png) 文章来源地址https://www.toymoban.com/news/detail-860527.html
文章来源地址https://www.toymoban.com/news/detail-860527.html
到了这里,关于【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!