随着软件复杂度的提升,消息代理在系统不同模块之间的通信中起着至关重要的作用。在众多可用的消息代理中,Kafka和RabbitMQ是两个流行的选择。虽然它们用途相似,但具有不同的特性和业务场景。本文将深入探讨Kafka和RabbitMQ之间的区别,以帮助您根据自己的业务场景选择合适的消息代理软件。
Kafka简介
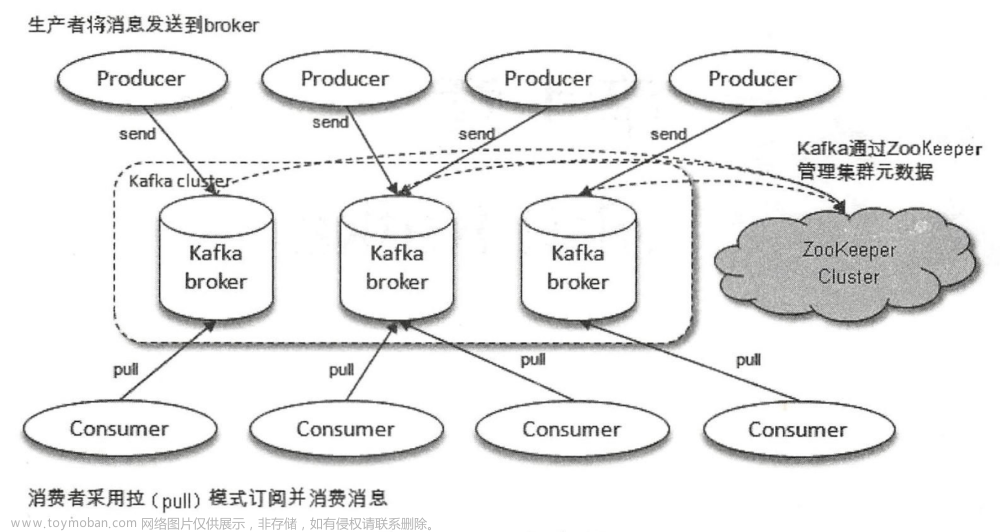
Kafka最初是由LinkedIn开发的分布式事件流平台,后被Apache软件基金会接管。它旨在处理高吞吐量的实时数据流,并以其可扩展性和容错性而闻名。Kafka遵循分布式发布-订阅模型,其中生产者将消息发布到主题,消费者订阅这些主题以接收消息。

Kafka的适应场景
实时数据处理:Kafka非常适合需要实时处理大量数据的场景,如日志聚合、监控和分析。
事件溯源:Kafka的不可变事件日志架构可以帮助应用程序捕获和存储每一个变化的状态。
流处理:Flink和Strom等流处理框架与Kafka可以实现无缝集成,使开发人员能够构建持续处理数据流的实时应用程序。
RabbitMQ简介
RabbitMQ是使用AMQP(高级消息队列协议)标准开发的开源消息代理软件。它提供了强大的消息传递功能,如消息排队、路由和传递确认。RabbitMQ支持多种消息传递模式,包括点对点、发布-订阅和请求-响应。

RabbitMQ的用例
任务队列:RabbitMQ擅长管理任务队列,适应于需要多个异步处理任务的场景。
微服务之间的通信:在微服务架构中,RabbitMQ可以实现不同服务之间的通信,确保低耦合和高可扩展。
工作流程和业务流程:涉及协调复杂工作流程或业务流程的应用程序,可以利用RabbitMQ的路由功能,将消息路由到恰当的处理程序。
Kafka和RabbitMQ之间的区别:
消息持久性:Kafka将消息持久化地存储在磁盘上,使其适用于需要持久消息存储的用例。相比之下,RabbitMQ默认将消息存储在内存中,尽管它提供了通过消息队列进行持久化的选项。
消息语义:Kafka保证分区内的消息是有序的,使其适用于依赖严格消息排序的事件溯源和流处理应用程序。RabbitMQ不提供对有序消息传递的原生支持,但可以通过自定义配置来实现。
可扩展性:Kafka是水平可扩展的,允许它在多个服务器或集群上处理大量工作负载。RabbitMQ的可扩展性更多地依赖于集群,这需要更多的管理开销。
选择合适的消息代理:
评估功能:评估应用程序的特定要求,如消息吞吐量、消息排序和可扩展性。
评估性能:在类似于生产环境的条件下对Kafka和RabbitMQ进行基准测试,以衡量其性能和适用性。
评估开销:在选择Kafka和RabbitMQ时,考虑部署复杂性、监控能力和维护要求等因素。文章来源:https://www.toymoban.com/news/detail-860736.html
总结:
Kafka和RabbitMQ都是功能强大的消息代理,具有不同的特性和用例。虽然Kafka在需要高吞吐量、实时数据处理的场景中表现出色,但RabbitMQ非常适合管理任务队列、微服务之间的通信和工作流程协调。通过了解这两个平台之间的差异并评估您的特定需求,您可以选择最适合您的消息代理。文章来源地址https://www.toymoban.com/news/detail-860736.html
到了这里,关于Kafka与RabbitMQ的主要区别,分别适合什么业务场景?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!