在之前的文章中,我们学习了回归中的逻辑回归,并带来简单案例,学习用法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-机器学习(4)回归学习之逻辑回归-CSDN博客文章浏览阅读2.6k次,点赞63次,收藏38次。今天的文章,我们来学习我们回归中的逻辑回归,并带来简单案例,学习用法。希望大家能有所收获。同时,希望我的文章能帮助到每一个正在学习的你们。也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/138049507
今天的文章,我们来学习分类学习之朴素贝叶斯算法,并带来简单案例,学习用法。希望大家能有所收获。
目录
一、朴素贝叶斯
什么是朴素贝叶斯
spark朴素贝叶斯
二、示例代码
完整代码
方法解析
代码效果
代码输出
拓展-spark朴素贝叶斯
一、朴素贝叶斯
什么是朴素贝叶斯

朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理与特征之间强(朴素)独立假设的分类方法。它简单、易于实现,并且在很多情况下都有不错的分类效果。朴素贝叶斯分类器常用于文本分类,如垃圾邮件的识别。
这里的“朴素”一词意味着该分类器假设特征之间是相互独立的,即一个特征的出现与另一个特征无关。然而,在现实世界的数据集中,这个假设往往是不成立的,即特征之间往往存在一定的相关性。尽管如此,朴素贝叶斯分类器在很多实际应用中仍然表现得很好。
朴素贝叶斯分类器的工作原理大致如下:
-
训练阶段:
- 对于每个类别,计算每个特征的条件概率,即该特征在给定类别中出现的概率。
- 同时,计算每个类别的先验概率,即训练集中该类别的样本数占总样本数的比例。
-
分类阶段:
- 对于一个新的待分类样本,根据朴素贝叶斯公式(即贝叶斯定理)和训练阶段得到的条件概率、先验概率,计算该样本属于每个类别的后验概率。
- 将样本分类到后验概率最大的那个类别。
朴素贝叶斯分类器有多种变体,如高斯朴素贝叶斯(用于连续特征)、多项式朴素贝叶斯(用于离散特征)和伯努利朴素贝叶斯(用于二元特征)。这些变体在处理不同类型的数据时具有不同的优势。
spark朴素贝叶斯
spark朴素贝叶斯是指在Apache Spark大数据处理框架中实现的朴素贝叶斯算法。朴素贝叶斯算法本身是一类基于贝叶斯定理和特征之间条件独立假设的分类方法。在Spark中,可以使用MLlib(机器学习库)来方便地实现朴素贝叶斯算法,并应用于大规模数据集的分类任务。
Spark朴素贝叶斯分类器的主要工作原理是基于朴素贝叶斯定理,它计算给定特征条件下样本属于不同类别的概率,并将样本分类到概率最大的类别中。在Spark中,可以利用分布式计算的能力来处理大规模数据集,提高分类任务的效率和可扩展性。
使用Spark朴素贝叶斯分类器时,通常需要先准备训练数据集,然后使用MLlib提供的朴素贝叶斯算法进行模型训练。训练完成后,可以使用得到的模型对新的数据进行分类预测。
Spark朴素贝叶斯分类器在实际应用中具有广泛的应用场景,如文本分类、垃圾邮件识别、情感分析等。通过利用Spark的分布式计算能力,可以高效地处理大规模数据集,并提升分类任务的性能和准确性。
二、示例代码
在我的示例代码中主要作用是展示如何使用Apache Spark MLlib来执行以下步骤:
- 准备和预处理数据。
- 训练一个朴素贝叶斯分类器。
- 使用模型进行预测。
- 评估模型的性能。
由于我们数据集很小且简单,该代码主要用于学习。在实际应用中,通常会使用更大、更复杂的数据集,并且可能需要进行更多的数据预处理和模型调优。
完整代码
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.NaiveBayes
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler}
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.linalg.Vectors
object p5 {
def main(args: Array[String]): Unit = {
// 初始化SparkSession
val spark = SparkSession.builder()
.appName("Peng0426.")
.master("local[*]") // 使用所有可用的核心在本地运行
.getOrCreate()
import spark.implicits._
val data = Seq(
(0.0, Vectors.dense(0.0, 1.0)),
(1.0, Vectors.dense(1.0, 0.0)),
(0.0, Vectors.dense(2.0, 1.0)),
(1.0, Vectors.dense(0.0, 3.0))
).toDF("label", "features")
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(data)
// 创建朴素贝叶斯分类器
val nb = new NaiveBayes()
.setLabelCol("indexedLabel")
.setFeaturesCol("features")
val pipeline = new Pipeline()
.setStages(Array(labelIndexer, nb))
val model = pipeline.fit(data)
val predictions = model.transform(data)
// 选择并展示预测结果
predictions.select("label", "indexedLabel", "prediction").show()
// 选择(预测标签,实际标签)并计算测试误差
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test Error = ${(1.0 - accuracy)}")
}
}方法解析
-
SparkSession:这是Apache Spark MLlib的入口点,用于创建DataFrame和注册DataFrame相关的函数。
-
Pipeline:在Spark ML中,Pipeline用于将多个转换(Transformations)和模型(Models)串联在一起,形成一个统一的工作流。
-
StringIndexer:将标签列(通常是字符串类型)转换为索引标签,以便可以用于分类算法。
-
NaiveBayes:朴素贝叶斯分类器,用于执行分类任务。
-
VectorAssembler:VectorAssembler通常用于将多个列组合成一个特征向量。
-
MulticlassClassificationEvaluator:用于评估多分类模型性能的评估器,此处用于计算准确率。
-
Vectors:用于创建密集向量。
代码效果
-
数据准备:创建一个包含标签和特征的数据集。
-
数据预处理:使用StringIndexer将标签转换为索引形式。
-
模型训练:通过Pipeline训练朴素贝叶斯分类器。
-
预测:使用训练好的模型对数据进行预测。
-
评估:使用MulticlassClassificationEvaluator计算模型的准确率。
代码输出
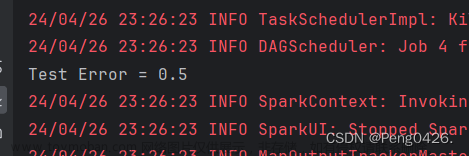
运行代码我们应该得到如下两段内容:
-
预测结果:使用
predictions.select("label", "indexedLabel", "prediction").show()展示原始标签、索引标签和预测标签。 -
测试误差:计算并打印出测试误差(1减去准确率)。

 文章来源:https://www.toymoban.com/news/detail-860737.html
文章来源:https://www.toymoban.com/news/detail-860737.html
成功得到两段我们所需内容。文章来源地址https://www.toymoban.com/news/detail-860737.html
拓展-spark朴素贝叶斯
| 说明 | 描述 | 示例 |
|---|---|---|
| 算法名称 | 朴素贝叶斯(Naive Bayes) | 假设特征之间相互独立,利用贝叶斯定理进行分类 |
| 所属框架 | Apache Spark MLlib | Spark MLlib提供了朴素贝叶斯分类器的实现 |
| 适用场景 | 文本分类、垃圾邮件过滤、情感分析等 | 使用Spark MLlib的朴素贝叶斯分类器对文本数据进行分类 |
| 算法原理 | 基于贝叶斯定理和特征条件独立假设 | 计算每个类别的先验概率和特征的条件概率,然后利用贝叶斯定理计算后验概率 |
| 数据要求 | 特征通常是离散的 | 将文本数据转换为TF-IDF向量,然后作为朴素贝叶斯分类器的输入 |
| 优点 | 实现简单、计算效率高、对缺失数据不敏感 | 使用Spark的分布式计算能力,可以快速处理大规模数据集 |
| 缺点 | 假设特征之间相互独立,可能不适用于所有场景 | 当特征之间存在依赖关系时,分类效果可能不佳 |
| 使用步骤 | 1. 准备数据集<br>2. 加载数据集到Spark<br>3. 转换数据为MLlib格式<br>4. 训练朴素贝叶斯模型<br>5. 使用模型进行预测 | 使用Spark MLlib的API,编写代码进行数据处理、模型训练和预测 |
到了这里,关于Spark-机器学习(5)分类学习之朴素贝叶斯算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












