问题出现场景
为了评估一个 Flink 程序的处理效果,我使用本地模式启动了 Flink 程序,并在上游表中一次性插入了大量数据(大概相当于线上单个并发 4 - 5 分钟的最大处理量),以触发计算。
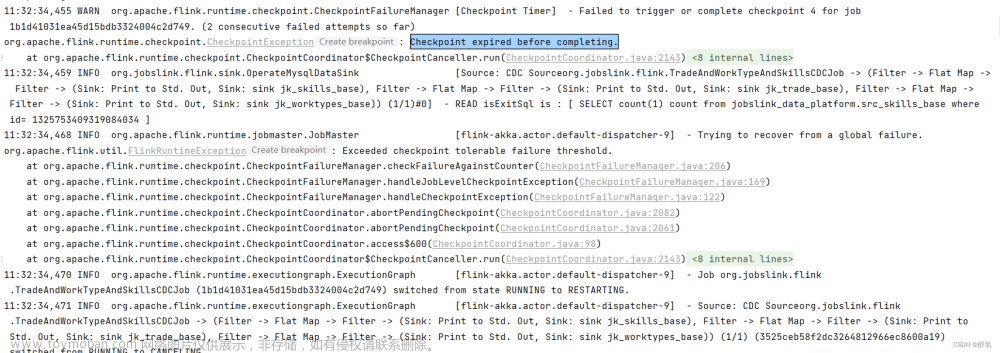
但是,在本地计算中,一直无法计算完成,观察后发现任务在被重复计算,进而发现 Flink 在不断从 checkpoint 恢复。在日志中搜索 checkpoint,发现如下报错信息:
org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold.
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleCheckpointException(CheckpointFailureManager.java:98) ~[flink-runtime_2.11-1.13.5.jar:1.13.5]
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:67) ~[flink-runtime_2.11-1.13.5.jar:1.13.5]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1934) ~[flink-runtime_2.11-1.13.5.jar:1.13.5]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1906) ~[flink-runtime_2.11-1.13.5.jar:1.13.5]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.access$600(CheckpointCoordinator.java:96) ~[flink-runtime_2.11-1.13.5.jar:1.13.5]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator$CheckpointCanceller.run(CheckpointCoordinator.java:1990) ~[flink-runtime_2.11-1.13.5.jar:1.13.5]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_391]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_391]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_391]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) ~[?:1.8.0_391]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_391]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_391]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_391]
该报错大概每 10 分钟左右出现一次,具体如下:
- 11:30:44 - 启动 Flink 程序
- 11:41:17 - 第一次报错(在启动后 10 分钟 33 秒)
- 11:51:48 - 第二次报错(在上次报错后 10 分钟 31 秒)
- 12:02:19 - 第三次报错(在上次报错后 10 分钟 31 秒)
- ……
问题原因
通过定位,发现是 checkpoint 超时报错。Flink 的 checkpoint 的超时时间时 600 秒,但是这个任务需要 11 分钟才能完成。本地之所以比线上慢,一方面是因为本地增加了一部分新的逻辑;另一方面也可能是因为线上运行时,对 MySQL 请求时走的是内网请求,而本地运行走的是外网请求。
Flink 的 checkpoint 超时时间默认值的源码位置如下:文章来源:https://www.toymoban.com/news/detail-860868.html
// org.apache.flink.streaming.api.environment.CheckpointConfig public class CheckpointConfig implements Serializable { public CheckpointConfig() { this.checkpointingMode = DEFAULT_MODE; this.checkpointInterval = -1L; this.checkpointTimeout = 600000L; this.minPauseBetweenCheckpoints = 0L; this.maxConcurrentCheckpoints = 1; this.alignmentTimeout = (Duration)ExecutionCheckpointingOptions.ALIGNMENT_TIMEOUT.defaultValue(); this.failOnCheckpointingErrors = true; this.preferCheckpointForRecovery = false; this.tolerableCheckpointFailureNumber = -1; }
解决方法
在本地测试时,如需较大数据量测试,显式地设置 checkpoint 超时时间即可:文章来源地址https://www.toymoban.com/news/detail-860868.html
env.getCheckpointConfig().setCheckpointTimeout(1200000);
到了这里,关于Flink|checkpoint 超时报错问题处理(FlinkRuntimeException)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!