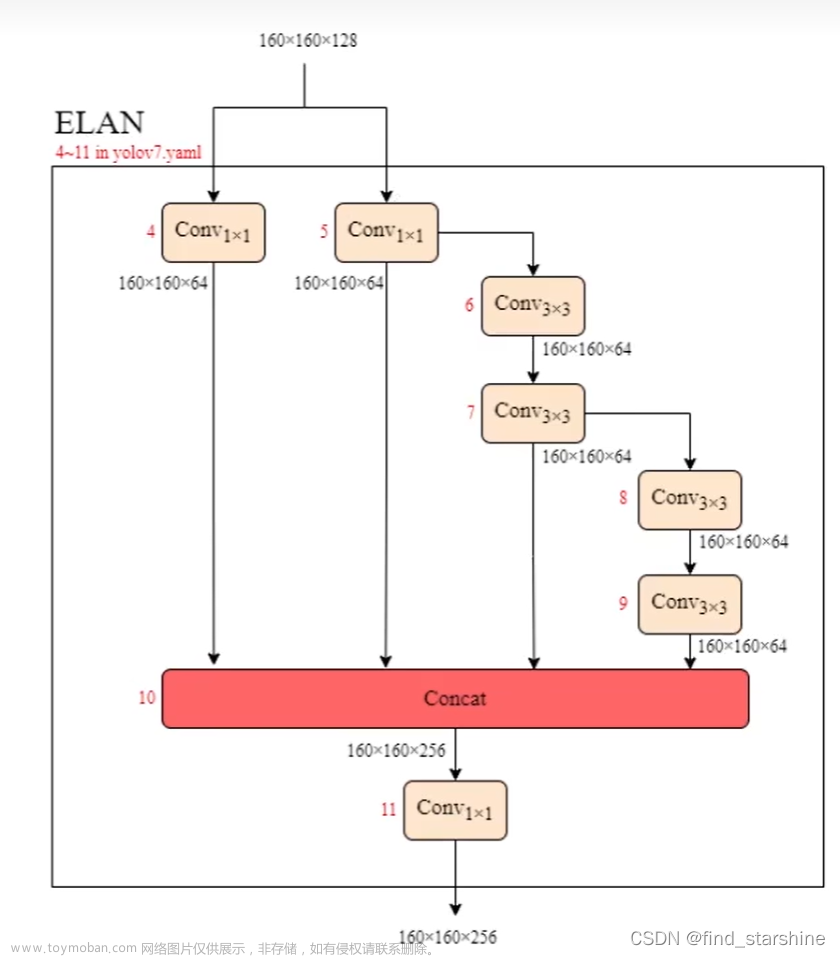
在视觉深度学习中,通常将模型分为 2~3 个组成部分:backbone、neck(可选) 和 head。
-
Backbone(主干网络)负责从输入图像中
提取特征,将图像转化为具有丰富语义信息的特征表示。 -
Neck(颈部,连接部)是一个中间层,用于对来自 backbone 的
特征进行融合,以提升模型的性能。 -
Head(任务头)是模型的最后一层,其结构会根据不同的任务而有所不同。例如,在图像分类任务中,我们通常会使用
softmax 分类器作为 Head,而在目标检测任务中,我们则可能会使用边界框回归器和分类器作为 Head。
YOLOv8 架构图
关于下面经典的架构图的简要说明:
- 图的上面部分为 YOLOv8 架构的概要图(包括 Backbone,Head)。
YOLOv8 没有适用 Neck这个概念,但其架构图中Head中类似 PANet 功能的部分也可以归为 Neck。 - 图右中位置 Detail 为各个组件的详细架构示例,另说明了不同模型大小的参数选择。
- 图左 + 图下部分,以分步的方式列出了完整的数据流。
- 每个框的右上角的数字为层的编号,可以和后面的示例输出 1 对照看。
可以看出,YOLOv8 Backbone 为 0~9 层,10~21 层为 YOLOv8 Head。

YOLOv8 Backbone 整体
见图中第 0~9 层。分别为
- Conv + Conv + C2f
- Conv + C2f(对齐特征金字塔 P3)
- Conv + C2f(对齐特征金字塔 P4)
- Conv + C2f + SPPF(对齐特征金字塔 P5)
YOLOv8 Head 整体
neck和head 结构
在yolo v8 的yaml文件中并没有显示地划分出neck部分,实际上neck网络结构就是其head网络结构中部分的前半部分。
head部分整体图:
head:
###neck###
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
###########
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
yaml配置文件中,注释段落即为neck结构
分清楚neck和head部分,可以很方便的对YOLOv8不同部分进行改进,实现任务涨点!文章来源:https://www.toymoban.com/news/detail-861181.html
整理不易🚀🚀,关注和收藏后拿走📌📌欢迎留言🧐👋📣
欢迎专注我的公众号AdaCoding 和 Github:AdaCoding123 文章来源地址https://www.toymoban.com/news/detail-861181.html
文章来源地址https://www.toymoban.com/news/detail-861181.html
到了这里,关于YOLOv8架构详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!