1.知识蒸馏的原理
在目标检测中,知识蒸馏的原理主要是利用教师模型(通常是大型的深度神经网络)的丰富知识来指导学生模型(轻量级的神经网络)的学习过程。通过蒸馏,学生模型能够在保持较高性能的同时,减小模型的复杂度和计算成本。
知识蒸馏实现的方式有多种,但核心目标是将教师模型学习到的知识迁移到学生中去(通常是通过各种损失函数进行实现)。
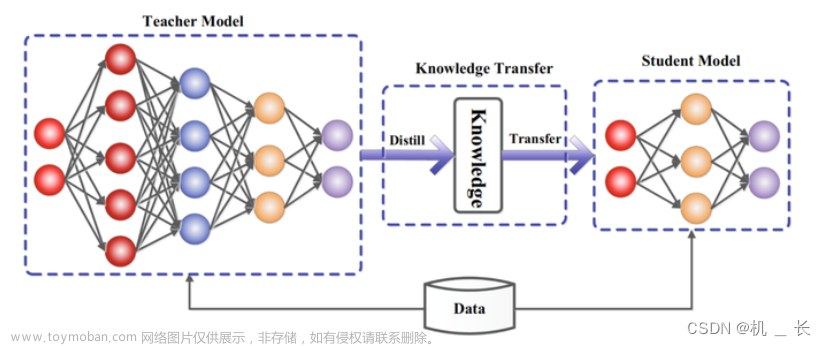
本项目支持yolov8检测、分割、关键点任务的知识蒸馏,并对蒸馏代码进行详解,比较容易上手。蒸馏方式多种,支持 logit和 feature-based蒸馏以及在线蒸馏。:
2.logit 蒸馏原理
Logit蒸馏原理主要基于深度学习中的知识迁移技术,特别是在模型压缩和加速领域。其核心思想是利用大型、复杂的教师模型(Teacher Model)的logits(逻辑层的原始输出得分)来指导小型、轻量的学生模型(Student Model)的学习。
Logits是教师模型在做出最终决策之前的原始得分,这些得分在数值上表示了模型对每个类别的预测置信度。相较于最终的类别概率分布,logits包含了更丰富的信息,尤其是当不同类别之间存在细微差别时。
在Logit蒸馏过程中,教师模型的logits被用作额外的监督信号来训练学生模型。通过最小化教师模型和学生模型在logits层面上的差异(通常使用均方误差MSE或KL散度等损失函数),可以使学生模型学习到教师模型在决策边界附近的细致区分能力。这种蒸馏方式有助于提升学生模型在保持较高性能的同时,减小模型的复杂度和计算成本。
逻辑蒸馏损失定义的代码在:ultralytics/utils/distill_loss.py
class Distill_LogitLoss:
def __init__(self,p, t_p, alpha =0.25):
t_ft = torch.cuda.FloatTensor if t_p[0].is_cuda else torch.Tensor
self.p =p
self.t_p = t_p
self.logit_loss = t_ft([0])
self.DLogitLoss = nn.MSELoss(reduction="none")
self.bs = p[0].shape[0]
self.alpha = alpha
def __call__(self):
# per output
assert len(self.p) == len(self.t_p)
for i, (pi,t_pi) in enumerate(zip(self.p,self.t_p)): # layer index, layer predictions
assert pi.shape == t_pi.shape
self.logit_loss += torch.mean(self.DLogitLoss(pi, t_pi))
return self.logit_loss[0]*self.alpha3.feature-base蒸馏原理
Feature-based蒸馏原理是知识蒸馏中的一种重要方法,其关键在于利用教师模型的隐藏层特征来指导学生模型的学习过程。这种蒸馏方式旨在使学生模型能够学习到教师模型在特征提取和表示方面的能力,从而提升其性能。
具体来说,Feature-based蒸馏通过比较教师模型和学生模型在某一或多个隐藏层的特征表示来实现知识的迁移。在训练过程中,教师模型的隐藏层特征被提取出来,并作为监督信号来指导学生模型相应层的特征学习。通过优化两者在特征层面的差异(如使用均方误差、余弦相似度等作为损失函数),可以使学生模型逐渐逼近教师模型的特征表示能力。
这种蒸馏方式有几个显著的优势。首先,它充分利用了教师模型在特征提取方面的优势,帮助学生模型学习到更具判别性的特征表示。其次,通过比较特征层面的差异,可以更加细致地指导学生模型的学习过程,使其在保持较高性能的同时减小模型复杂度。最后,Feature-based蒸馏可以与其他蒸馏方式相结合,形成更为复杂的蒸馏策略,以进一步提升模型性能。
需要注意的是,在选择进行Feature-based蒸馏的隐藏层时,需要谨慎考虑。不同层的特征具有不同的语义信息和抽象程度,因此选择合适的层进行蒸馏对于最终效果至关重要。此外,蒸馏过程中的损失函数和权重设置也需要根据具体任务和数据集进行调整。
综上所述,Feature-based蒸馏原理是通过利用教师模型的隐藏层特征来指导学生模型的学习过程,从而实现知识的迁移和模型性能的提升。这种方法在深度学习领域具有广泛的应用前景,尤其在需要提高模型特征提取能力的场景中表现出色。
本文将给出3种feature-base的蒸馏损失方法,代码分别如下
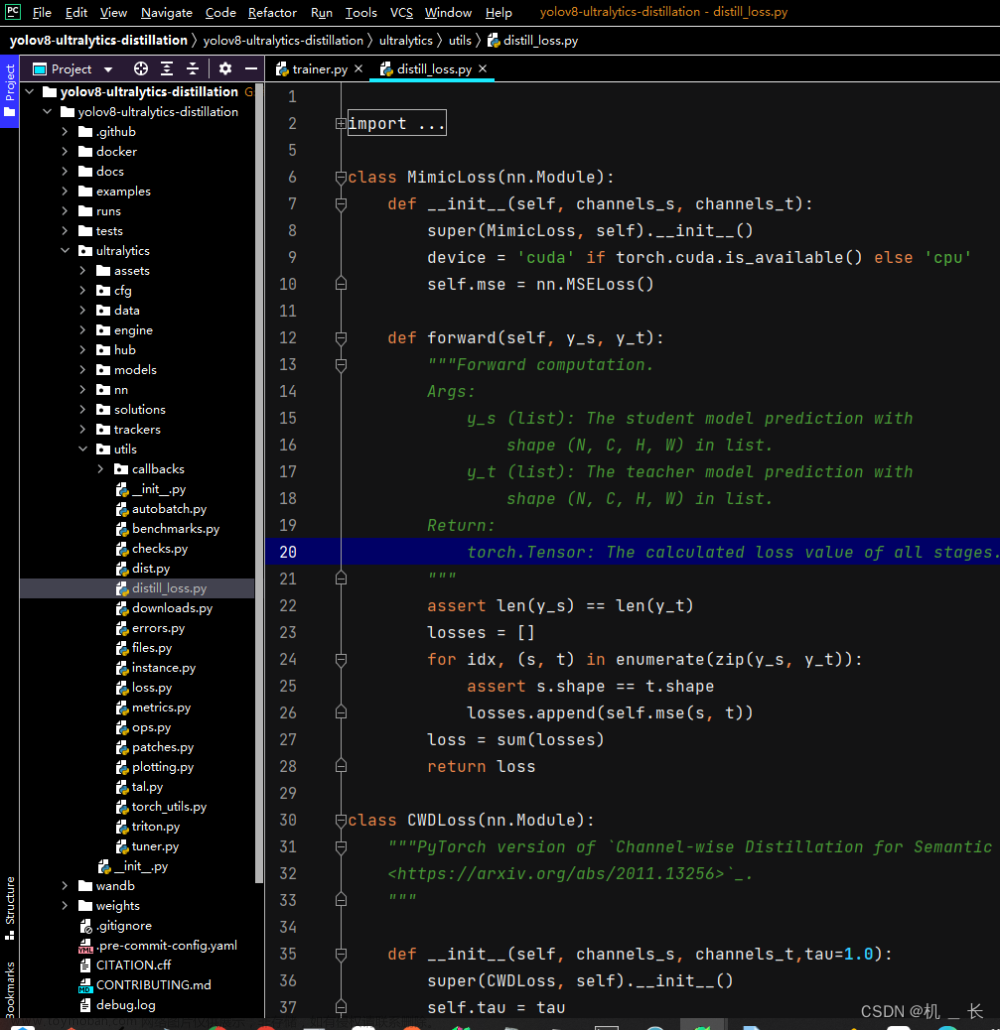
- MimicLoss
class MimicLoss(nn.Module):
def __init__(self, channels_s, channels_t):
super(MimicLoss, self).__init__()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.mse = nn.MSELoss()
def forward(self, y_s, y_t):
"""Forward computation.
Args:
y_s (list): The student model prediction with
shape (N, C, H, W) in list.
y_t (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(y_s) == len(y_t)
losses = []
for idx, (s, t) in enumerate(zip(y_s, y_t)):
assert s.shape == t.shape
losses.append(self.mse(s, t))
loss = sum(losses)
return loss- CWDLoss
class CWDLoss(nn.Module):
"""PyTorch version of `Channel-wise Distillation for Semantic Segmentation.
<https://arxiv.org/abs/2011.13256>`_.
"""
def __init__(self, channels_s, channels_t,tau=1.0):
super(CWDLoss, self).__init__()
self.tau = tau
def forward(self, y_s, y_t):
"""Forward computation.
Args:
y_s (list): The student model prediction with
shape (N, C, H, W) in list.
y_t (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(y_s) == len(y_t)
losses = []
for idx, (s, t) in enumerate(zip(y_s, y_t)):
assert s.shape == t.shape
N, C, H, W = s.shape
# normalize in channel diemension
softmax_pred_T = F.softmax(t.view(-1, W * H) / self.tau, dim=1) # [N*C, H*W]
logsoftmax = torch.nn.LogSoftmax(dim=1)
cost = torch.sum(
softmax_pred_T * logsoftmax(t.view(-1, W * H) / self.tau) -
softmax_pred_T * logsoftmax(s.view(-1, W * H) / self.tau)) * (self.tau ** 2)
losses.append(cost / (C * N))
loss = sum(losses)
return loss- MGDLoss
class MGDLoss(nn.Module):
def __init__(self, channels_s, channels_t, alpha_mgd=0.00002, lambda_mgd=0.65):
super(MGDLoss, self).__init__()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.alpha_mgd = alpha_mgd
self.lambda_mgd = lambda_mgd
self.generation = [
nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, kernel_size=3, padding=1)).to(device) for channel in channels_t
]
def forward(self, y_s, y_t):
"""Forward computation.
Args:
y_s (list): The student model prediction with
shape (N, C, H, W) in list.
y_t (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(y_s) == len(y_t)
losses = []
for idx, (s, t) in enumerate(zip(y_s, y_t)):
assert s.shape == t.shape
losses.append(self.get_dis_loss(s, t, idx) * self.alpha_mgd)
loss = sum(losses)
return loss
def get_dis_loss(self, preds_S, preds_T, idx):
loss_mse = nn.MSELoss(reduction='sum')
N, C, H, W = preds_T.shape
device = preds_S.device
mat = torch.rand((N, 1, H, W)).to(device)
mat = torch.where(mat > 1 - self.lambda_mgd, 0, 1).to(device)
masked_fea = torch.mul(preds_S, mat)
new_fea = self.generation[idx](masked_fea)
dis_loss = loss_mse(new_fea, preds_T) / N
return dis_loss以上三种feature-based的蒸馏损失,其中MimicLoss是最常见的特征蒸馏损失,而MGD和CWD是当前的SOTA特征蒸馏方案。
4.yolov8 蒸馏代码实现
(1)蒸馏参数的设置
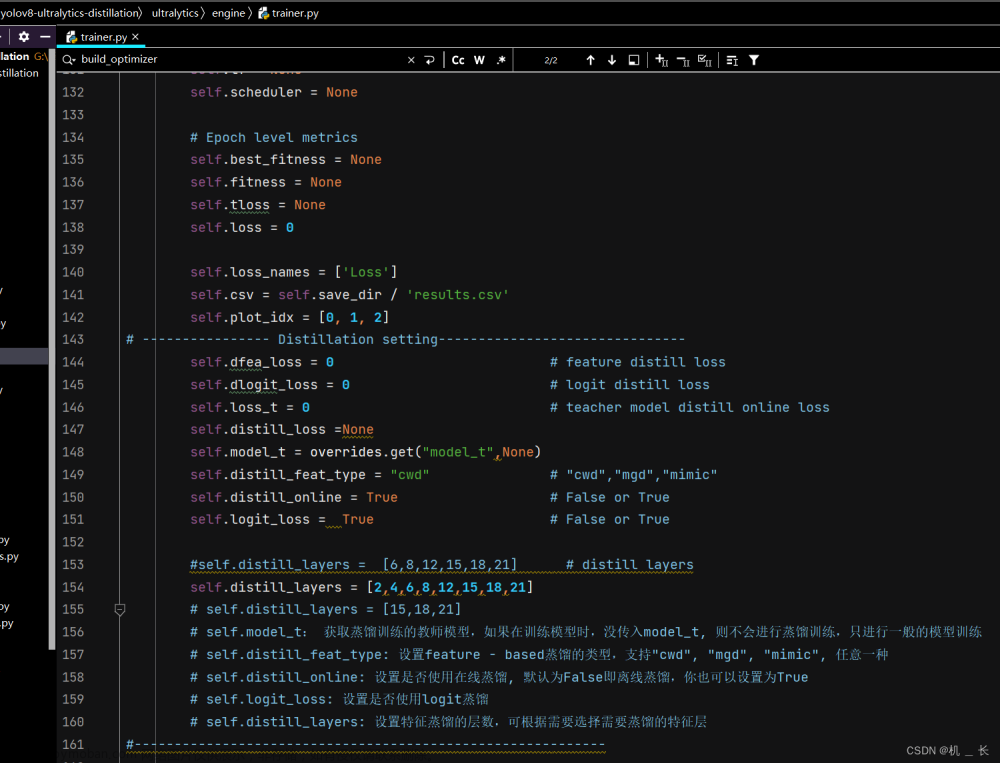
将以下代码放置在ultralytics\engine\trainer.py文件种142行位置处
self.dfea_loss = 0 # feature distill loss
self.dlogit_loss = 0 # logit distill loss
self.loss_t = 0 # teacher model distill online loss
self.distill_loss =None
self.model_t = overrides.get("model_t",None)
self.distill_feat_type = "cwd" # "cwd","mgd","mimic"
self.distill_online = True # False or True
self.logit_loss = True # False or True
#self.distill_layers = [6,8,12,15,18,21] # distill layers
self.distill_layers = [2,4,6,8,12,15,18,21]
# self.distill_layers = [15,18,21]
# self.model_t: 获取蒸馏训练的教师模型,如果在训练模型时,没传入model_t, 则不会进行蒸馏训练,只进行一般的模型训练
# self.distill_feat_type: 设置feature - based蒸馏的类型,支持"cwd", "mgd", "mimic", 任意一种
# self.distill_online: 设置是否使用在线蒸馏, 默认为False即离线蒸馏,你也可以设置为True
# self.logit_loss: 设置是否使用logit蒸馏
# self.distill_layers: 设置特征蒸馏的层数,可根据需要选择需要蒸馏的特征层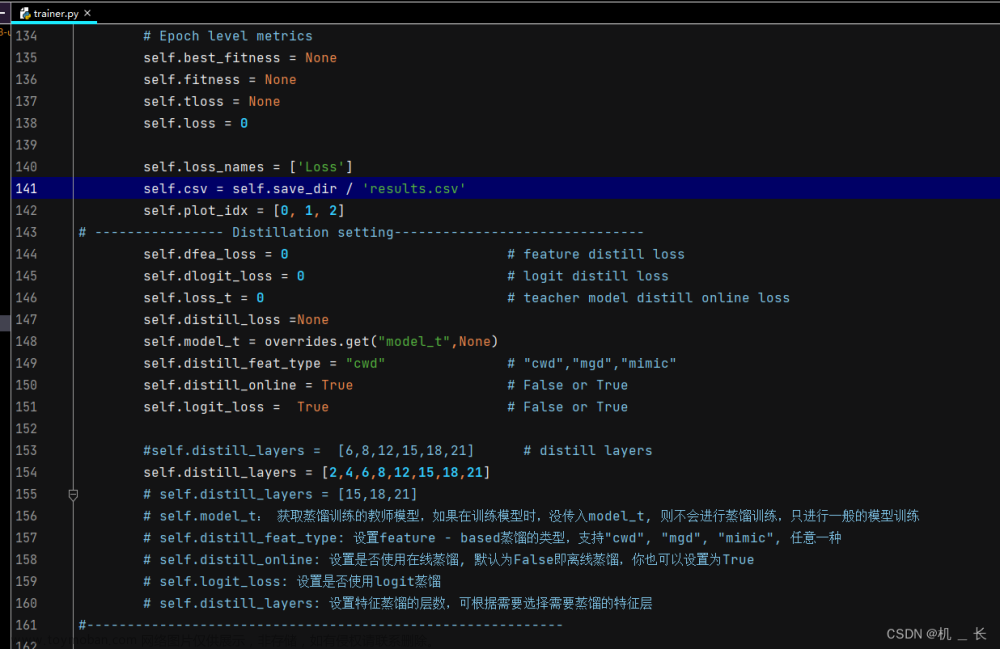
(2)蒸馏损失代码实现
新建ultralytics/utils/distill_loss.py文件,并将以上有关蒸馏损失放置在其中(完整代码可关注博主加私信获取)
(3) 优化器optimizer修改
(完整代码可关注博主加私信获取。获取后直接替换trainer.py即可)代码在ultralytics/engine/trainer.py的build_optimizer函数中
将如下的300行左右build_optimizer,按下图进行修改
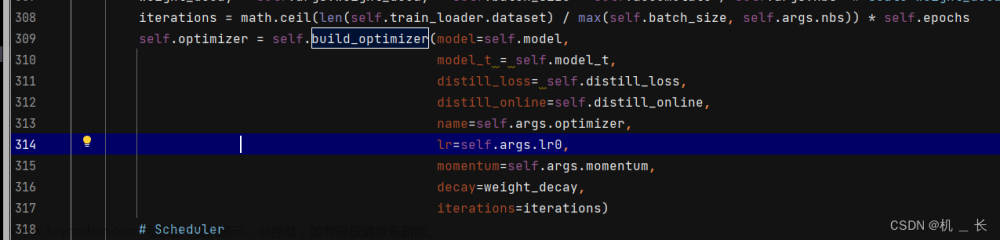
build_optimizer函数内容如下
def build_optimizer(self, model, model_t,distill_loss,distill_online=False,name='auto', lr=0.001, momentum=0.9, decay=1e-5, iterations=1e5):
"""
Constructs an optimizer for the given model, based on the specified optimizer name, learning rate, momentum,
weight decay, and number of iterations.
Args:
model (torch.nn.Module): The model for which to build an optimizer.
name (str, optional): The name of the optimizer to use. If 'auto', the optimizer is selected
based on the number of iterations. Default: 'auto'.
lr (float, optional): The learning rate for the optimizer. Default: 0.001.
momentum (float, optional): The momentum factor for the optimizer. Default: 0.9.
decay (float, optional): The weight decay for the optimizer. Default: 1e-5.
iterations (float, optional): The number of iterations, which determines the optimizer if
name is 'auto'. Default: 1e5.
Returns:
(torch.optim.Optimizer): The constructed optimizer.
"""
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
if name == 'auto':
LOGGER.info(f"{colorstr('optimizer:')} 'optimizer=auto' found, "
f"ignoring 'lr0={self.args.lr0}' and 'momentum={self.args.momentum}' and "
f"determining best 'optimizer', 'lr0' and 'momentum' automatically... ")
nc = getattr(model, 'nc', 10) # number of classes
lr_fit = round(0.002 * 5 / (4 + nc), 6) # lr0 fit equation to 6 decimal places
name, lr, momentum = ('SGD', 0.01, 0.9) if iterations > 10000 else ('AdamW', lr_fit, 0.9)
self.args.warmup_bias_lr = 0.0 # no higher than 0.01 for Adam
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
g[2].append(v.bias)
if isinstance(v, bn): # weight (no decay)
g[1].append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g[0].append(v.weight)
if model_t is not None and distill_online:
for v in model_t.modules():
# print(v)
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
g[2].append(v.bias)
if isinstance(v, bn): # weight (no decay)
g[1].append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g[0].append(v.weight)
if model_t is not None and distill_loss is not None:
for k, v in distill_loss.named_modules():
# print(v)
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
g[2].append(v.bias)
if isinstance(v, bn) or 'bn' in k: # weight (no decay)
g[1].append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g[0].append(v.weight)
if name in ('Adam', 'Adamax', 'AdamW', 'NAdam', 'RAdam'):
optimizer = getattr(optim, name, optim.Adam)(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
elif name == 'RMSProp':
optimizer = optim.RMSprop(g[2], lr=lr, momentum=momentum)
elif name == 'SGD':
optimizer = optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
else:
raise NotImplementedError(
f"Optimizer '{name}' not found in list of available optimizers "
f'[Adam, AdamW, NAdam, RAdam, RMSProp, SGD, auto].'
'To request support for addition optimizers please visit https://github.com/ultralytics/ultralytics.')
optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
LOGGER.info(
f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}, momentum={momentum}) with parameter groups "
f'{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias(decay=0.0)')
return optimizer5.yolov8 蒸馏训练步骤
在项目中,教师模型model_t选择是yolov8l, 学生模型model_s,选择的是yolov8n
(1) 训练教师模型
from ultralytics import YOLO
data = r"ultralytics\datasets\coco128.yaml"
model_t = YOLO(r'weights\yolov8l.pt')
model_t.train(data=data, epochs=300, imgsz=640)(2) 训练学生模型baseline
from ultralytics import YOLO
data = r"ultralytics\datasets\coco128.yaml"
model_s = YOLO(r'weights\yolov8n.pt')
model_s.train(data=data, epochs=300, imgsz=640)(3) 蒸馏训练
将已经训练好的教师模型model_t的知识通过logit与feature-base知识蒸馏的方式迁移到学生模型model_s上,从而提升学生模型的性能。
import torch
from ultralytics import YOLO
data = r"/home/xxx/project/public/yolov8-ultralytics-main/yolov8-ultralytics-main/ultralytics/cfg/datasets/coco128.yaml"
model_t = YOLO(r'/home/xxx/project/public/yolov8-ultralytics-main/yolov8-ultralytics-main/weights/yolov8l.pt')
model_t.model.model[-1].set_Distillation = True
model_s = YOLO(r'/home/yuanwushui/project/public/yolov8-ultralytics-main/yolov8-ultralytics-main/yolov8n.pt')
model_s.train(data=data, epochs=300, imgsz=640, model_t= model_t.model)如果传入了model_t,则会进行蒸馏训练,否则为普通训练
注:feature-based蒸馏的类型设置(支持"cwd","mgd","mimic", 任意一种);设置是否使用在线蒸馏, (默认为False即离线蒸馏,你也可以设置为True);设置是否使用logit蒸馏;设置特征蒸馏的层数,(可根据需要选择需要蒸馏的特征层)。均在ultralytics/engine/trainer.py中的BaseTrainer类的初始化函数中__init__.py中进行设置。如下图
6.训练成功文章来源:https://www.toymoban.com/news/detail-861216.html
注,以上全部代码均可关注博主,私信后获取,仅需在某些位置进行代码与文件的替换即可,基于你的代码改写后并不影响你的原始代码使用,是否开启蒸馏、开启什么样的蒸馏取决于你的参数设置文章来源地址https://www.toymoban.com/news/detail-861216.html
到了这里,关于yolov8(目标检测、图像分割、关键点检测)知识蒸馏:logit和feature-based蒸馏方法的实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!