数据结构
我们知道MySQL的存储引擎Innodb默认底层是使用B+树的变种来存储数据的
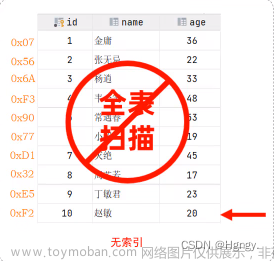
下面我们来复习一下B树存储 + B树存储 + 哈希存储的区别
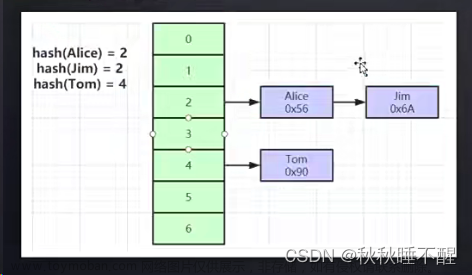
哈希存储,只能使用等值查询
B树与B+树存储
我们知道B+树实际上就是B树的变种
那么为啥使用B+树而不是使用B树呢?
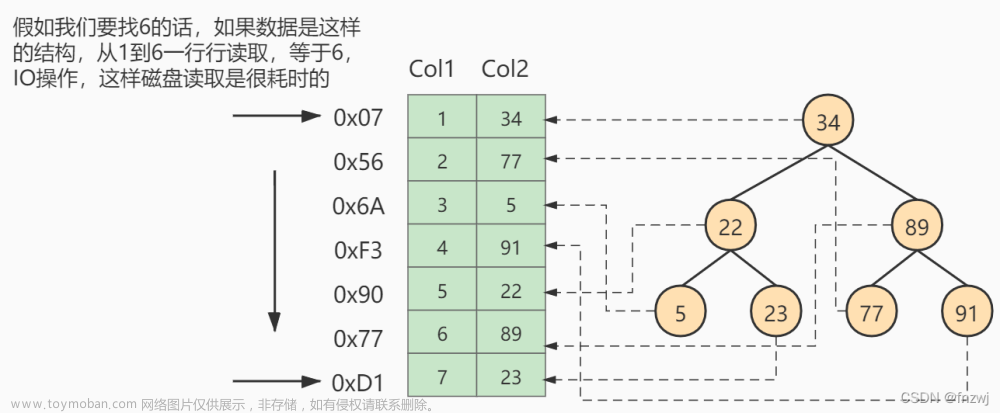
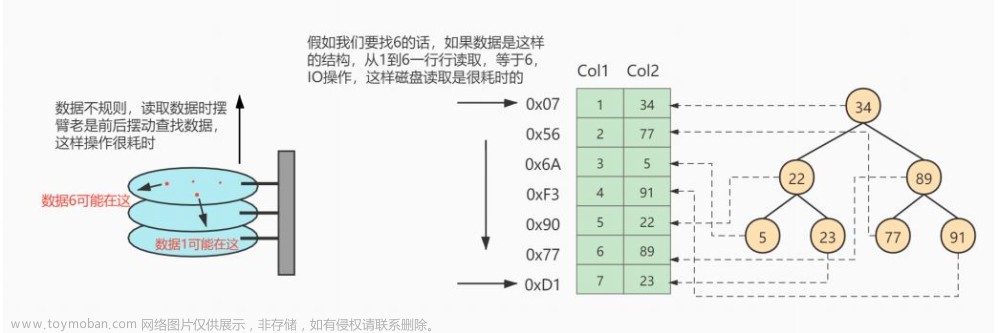
我们知道效率的高低主要取决于load进内存的时候这个load操作的次数
注:数据表中的数据只是逻辑上连续的,在物理内存中其实是不连续的
因为我们知道磁盘是一圈一圈的,磁头是一直在读写的
可能两次读写之间根本不在一个磁道中
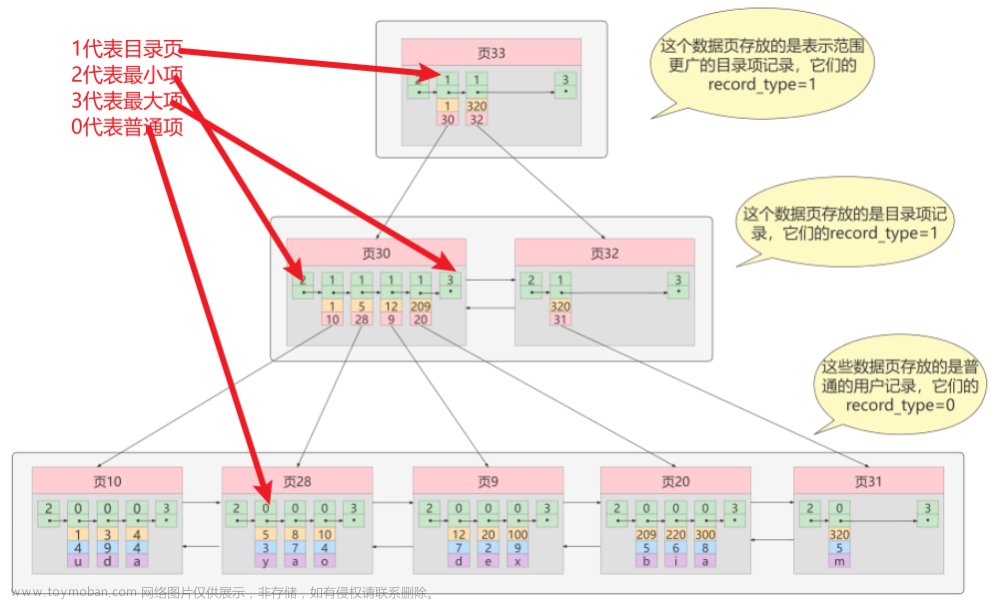
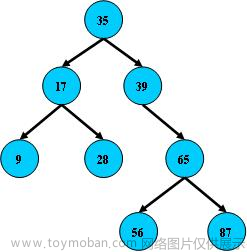
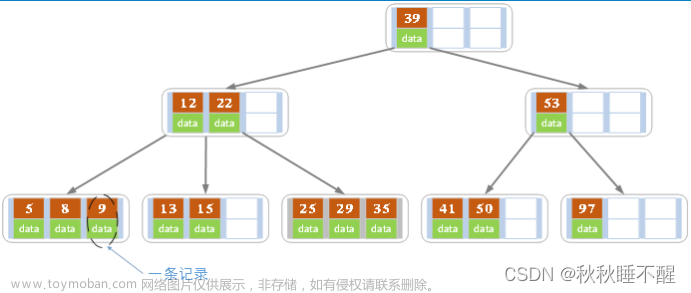
我们先看看B树的数据结构
假设这里我们向查找一个9号数据,我们内存中就会加载这里的根节点,以二分查找的方式开始查找9,但是这里的查找由于一层存放的节点是带有数据的,相对来说存放相同的数据的节点数就会少,对应的层数也就升高了,所以MySQL决定使用了B树的变种,B+树,B+树只在叶子结点存储数据,这样同一层能存储的数据就多了,虽然每一层都会使用一个冗余节点,但是内存开销也是很小的
一个叶节点最大16K(默认)
假设对于一个千万级的数据,对于B+树只需要三层,对于B树却需要远超3层的一个指数级节点数,而且对于范围查找也是B+树更擅长的,因为B+树在叶子节点之间之间放了一个双向指针,而且是排好序的数据,更方便查找范围数据
注:其实也可以选择使用hash结构存储,但是hash存储是不能解决范围查找的问题的,所以还是B+树更优

索引
索引的定义:索引是帮助mysql高效获取数据的排好序的数据结构
以上的定义对于理解索引的操作非常重要
对于根节点来说,其是常驻内存的
我们知道对于表规范来说我们应该在设计表的时候加上id 开始时间 更新时间
通常id设置为整形自增主键
为啥是自增主键呢??
选择整形是因为其占用的内存小,相对来说查找较快 以前使用uuid占用内存就比较大
自增是为了不导致树的平衡和节点拆分操作
我们举个例子
假设我先插入7 再插入 8 可能就是对树的大节点进行拆分,还对树进行了平衡操作,效率降低了
所以这里建议使用自增主键
相对来说使用自增主键的效率更高
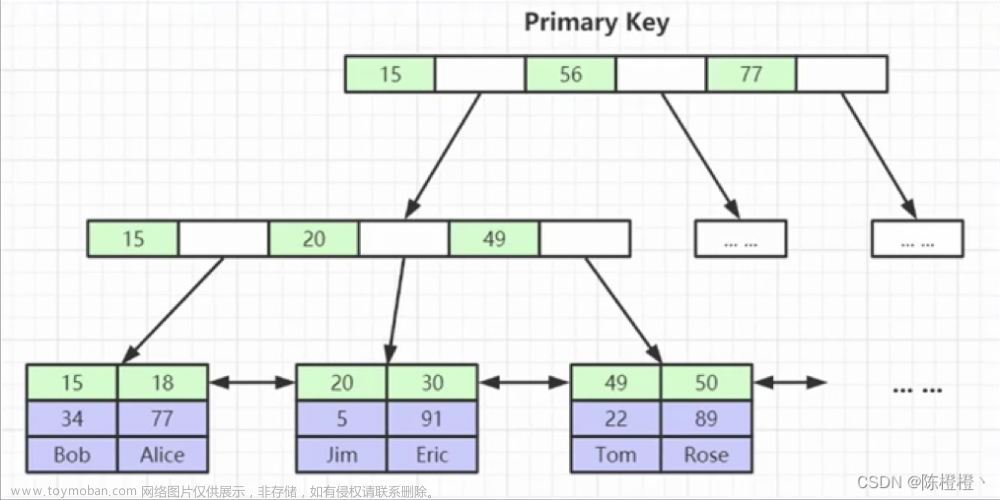
二级索引
我们知道对于mysql还有二级索引
那么二级索引又是怎么存储的呢?
二级索引的索引树叶子节点存储的就是索引信息和主键信息
对于二级索引索引树包含的信息使用它会更快
但是一旦超出的他的数据范围,就需要一个回表的操作了
因为二级索引树的信息不能包含所有的信息
只能根据其主键来去主键的索引树查询了
这样来说效率反而会降低,不如直接使用主键索引树的聚集查询
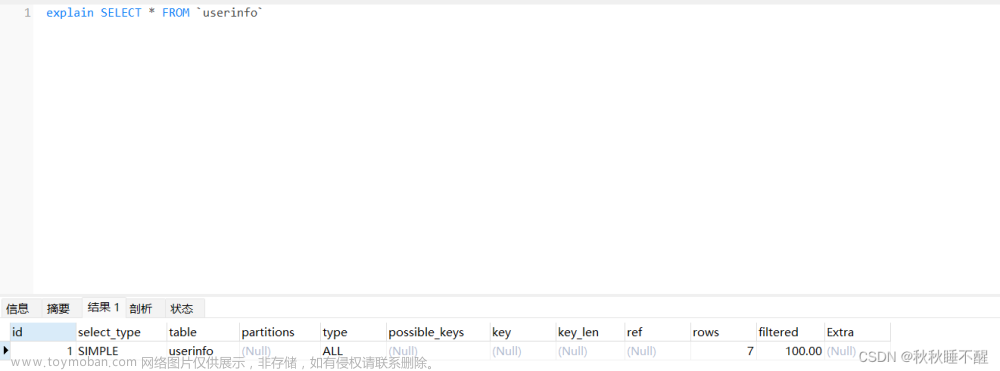
explain工具
我们知道explain关键字可以查询到sql语句中对应的sql执行信息,方便我们进行sql的优化
下面我们来介绍一下有关的信息
1.select_type 语句的复杂程度
一般有三种
simple sqlquery子查询 derived延伸查询
延伸查询是在from后面临时生成的临时表
2.partitions
分区 一般不使用
对于数据多的直接使用分库分表了
3.type
可以查看估算到sql语句执行的效率
下面我们来一个一个介绍一下这里的表示
1.system
表示这个表只有一个字段,使用唯一索引直接就查找到了
2.const
表示查找的时候使用唯一索引 就跟查询一个常量一样快
我们可以理解为system是const 的一个特殊情况
system的数据更少
3.eq_ref
equal_reference 表示连接的时候使用主键索引
这时候因为使用了唯一性索引就出来不需要比较
4.ref
在连接的时候没有使用唯一性索引
但是使用了索引可能使用了二级索引等等
查出来可能是多条数据要进行比较
5.range
范围查找
使用主键索引来检索给定范围的行
因为是有序的,还是能使用索引的
6.index
全索引扫描
这里使用的是二级索引进行范围查找
7.all
效率最低的全表扫描
不使用索引
key_len
这里表示的就是使用联合索引的哪个字段
比如说使用了int类的字段就是4表示4个字节...
extra
额外信息
这里说几个常见的
Using index
使用覆盖索引
这里的覆盖索引指的不是一种索引 而是一种查找索引的方式
这里就是表示二级索引的索引树叶子节点已经包含了全部信息
这里就无需再进行回表使用主键索引树继续查找了
Using where
查询的列没被索引覆盖
Using index condition
用到了临时表 比如使用了distinct进行去重 ,这里如果用到索引树就直接去拿
没用到索引树就得创建一个临时表
Using filesort
使用外部排序 在orderby的时候会出现
如果没使用索引就会出现外部排序
这里使用临时表和外部排序的都需要被优化掉,使用索引去覆盖即可
使用全值索引更快
顺序换了一下也会走索引,但是最好不要,因为mysql底层会进行一定程度的运算,会降低效率文章来源:https://www.toymoban.com/news/detail-861257.html
注:不要在索引上做一些运算操作,因为这样会导致索引树无法定位文章来源地址https://www.toymoban.com/news/detail-861257.html




到了这里,关于MySQL 底层数据结构 聚簇索引以及二级索引 Explain的使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!