1、引言
小屌丝:鱼哥, 你说什么是LSTM
小鱼:LSTM… LSTM …
小屌丝:鱼哥, LSTM是啥?
小鱼:LSTM是… 不好意思说啊
小屌丝:这,有啥不好意思说的?
小鱼:你自己用输入法敲一下不就知道了。
小屌丝:…
小鱼:是啥啊, 让我看看?
小鱼:咋了,还不让我看,一定是…
小屌丝: 乱了乱了, 不是这样的。
小鱼:你看着你屏幕敲出的,还不承认
小屌丝:… 乱了乱了, 我说的LSTM算法模型,
小鱼:… 哦,这个啊,你都知道是算法模型,还问我啥?
小屌丝:这不是触碰到我的知识盲区了嘛,所以特来请教。
小鱼: 最后两个字是重点,待会可以考试哦
小屌丝:给我讲的明明白白的,我就告诉你刚刚输入法输出的是啥。
小鱼:嘿嘿~~
2、LSTM
2.1 定义
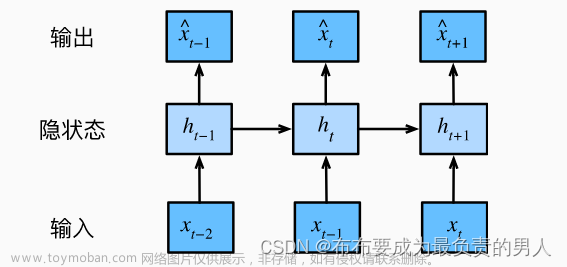
长短期记忆网络(Long Short-Term Memory,简称LSTM)是一种特殊的循环神经网络(RNN),旨在解决传统RNN在处理长序列时出现的梯度消失和爆炸问题。
LSTM通过引入门控机制,有效地捕获序列中的长期依赖关系,因此在自然语言处理、语音识别、时间序列预测等领域有着广泛的应用。
2.2 原理
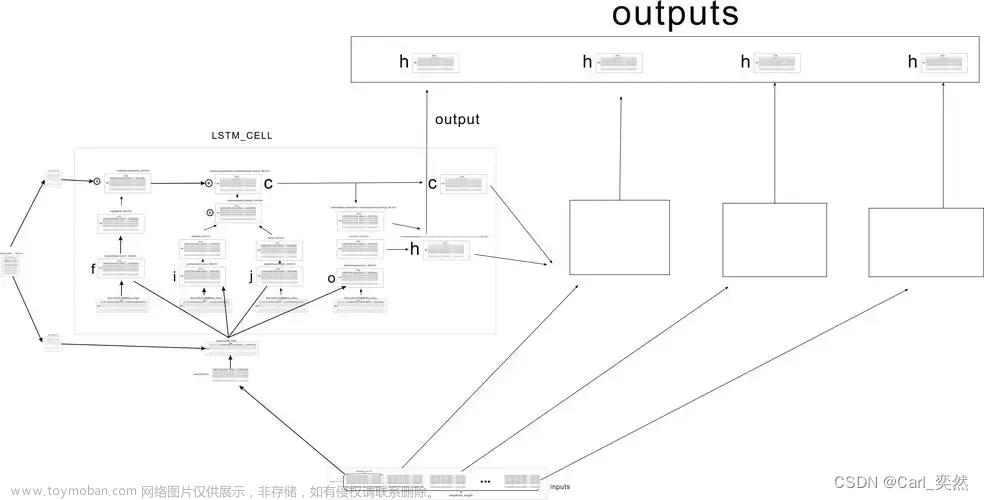
LSTM的核心思想是通过三个门(输入门、遗忘门和输出门)来控制信息的流动。这些门通过sigmoid函数将输入映射到0到1之间的值,从而决定信息的保留或丢弃。
- 输入门:决定当前时刻的输入和上一时刻的隐状态中有哪些信息需要保留下来。
- 遗忘门:决定上一时刻的细胞状态中哪些信息需要被遗忘。
- 输出门:基于当前的细胞状态来决定输出什么值。
LSTM的单元内部还包括一个细胞状态(cell state),用于保存长期记忆。通过这三个门和细胞状态的共同作用,LSTM能够在处理长序列时保持稳定的性能。
2.3 算法公式
LSTM的算法公式如下:
- 遗忘门: ( f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) ) (f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)) (ft=σ(Wf⋅[ht−1,xt]+bf))
- 输入门: ( i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) ) (i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)) (it=σ(Wi⋅[ht−1,xt]+bi))
- 细胞状态更新: ( C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) ) (\tilde{C}t = \tanh(W_C \cdot [h{t-1}, x_t] + b_C)) (C~t=tanh(WC⋅[ht−1,xt]+bC))
- 细胞状态: ( C t = f t ∗ C t − 1 + i t ∗ C ~ t ) (C_t = f_t * C_{t-1} + i_t * \tilde{C}_t) (Ct=ft∗Ct−1+it∗C~t)
- 输出门: ( o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) ) (o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)) (ot=σ(Wo⋅[ht−1,xt]+bo))
- 隐状态: ( h t = o t ∗ tanh ( C t ) ) (h_t = o_t * \tanh(C_t)) (ht=ot∗tanh(Ct))
其中,
- ( W f , W i , W C , W o ) (W_f, W_i, W_C, W_o) (Wf,Wi,WC,Wo) 是权重矩阵,
- ( b f , b i , b C , b o ) (b_f, b_i, b_C, b_o) (bf,bi,bC,bo) 是偏置项,
- ( σ ) (\sigma) (σ) 是sigmoid函数,
- ( tanh ) (\tanh) (tanh) 是双曲正切函数,
- ( h t − 1 ) (h_{t-1}) (ht−1) 是上一时刻的隐状态,
- ( x t ) (x_t) (xt)是当前时刻的输入,
- ( f t ) (f_t) (ft) 是遗忘门输出,
- ( i t ) (i_t) (it) 是输入门输出,
- ( C ~ t ) (\tilde{C}_t) (C~t) 是候选细胞状态,
- ( C t ) (C_t) (Ct) 是当前时刻的细胞状态,
- ( o t ) (o_t) (ot) 是输出门输出,
- ( h t ) (h_t) (ht) 是当前时刻的隐状态。
2.4 基本流程
LSTM算法模型的基本流程:
-
数据预处理:首先,需要对输入数据进行预处理,包括标准化、归一化等操作,以便模型能够更好地学习数据的特征。
-
创建模型:在Keras等深度学习框架中,LSTM模型通常通过Sequential类来创建。然后,按照所需的顺序添加LSTM层和其他必要的层,如Dense层(全连接层)用于输出预测。
-
定义网络结构:在LSTM中,每个时间步的输入都会经过三个主要的“门”结构:遗忘门、输入门和输出门。这些门结构通过特定的计算公式和控制机制,来决定哪些信息应该被保留,哪些应该被遗忘。
- 遗忘门:控制是否遗忘上一层的隐藏细胞状态,以一定的概率决定哪些信息需要保留。
-
输入门:负责处理当前序列位置的输入,并更新细胞状态。它包含两部分:
- 一部分使用sigmoid激活函数计算输入门的值,
- 另一部分使用tanh激活函数计算候选记忆单元的值。
- 输出门:根据更新后的细胞状态,计算并输出当前时间步的隐藏状态。
-
模型训练:使用预处理后的数据对模型进行训练。在训练过程中,模型会学习如何调整其参数以最小化预测误差。这通常通过反向传播算法和梯度下降优化器来实现。
-
模型评估:在训练完成后,使用验证集或测试集对模型进行评估,以检查其性能。评估指标可能包括准确率、损失函数值等。
-
模型应用:一旦模型经过训练和评估,并达到预期的性能要求,就可以将其应用于实际任务中,如时间序列预测、自然语言处理等。
2.5 代码示例
# -*- coding:utf-8 -*-
# @Time : 2024-03-16
# @Author : Carl_DJ
'''
实现功能:
PyTorch 和 torchtext 库来加载 IMDB 电影评论数据集,并训练一个 LSTM 模型来预测评论的情感(正面或负面)
'''
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy import data, datasets
# 定义字段处理器
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm')
LABEL = data.LabelField(dtype=torch.float)
# 定义数据集和迭代器
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_iterator, test_iterator = data.BucketIterator.splits(
(train_data, test_data),
batch_size=64,
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
)
# 定义 LSTM 模型
class LSTMClassifier(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, drop_prob=0.5):
super().__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, n_layers, dropout=drop_prob, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.drop = nn.Dropout(drop_prob)
def forward(self, text):
embedded = self.embedding(text)
lstm_out, _ = self.lstm(embedded)
lstm_out = self.drop(lstm_out)
return self.fc(lstm_out[:, -1, :])
# 超参数
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 32
OUTPUT_DIM = 1
N_LAYERS = 2
DROP_PROB = 0.5
# 实例化模型、损失函数和优化器
model = LSTMClassifier(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, N_LAYERS, DROP_PROB)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters())
# 将模型移动到 GPU(如果可用)
model = model.to(device)
criterion = criterion.to(device)
# 训练模型
N_EPOCHS = 5
for epoch in range(N_EPOCHS):
for batch in train_iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label.float())
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1:02}, Loss: {loss.item():.6f}')
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for batch in test_iterator:
predictions = model(batch.text).squeeze(1) > 0.5
correct += (predictions == batch.label).sum().item()
total += batch.batch_size
print(f'Accuracy: {100 * correct / total:.2f}%')
解析
- 使用 torchtext 加载 IMDB 电影评论数据集,并将其分为训练集和测试集。
- 定义了一个 LSTMClassifier 类,它继承自 nn.Module。这个类包含一个嵌入层、一个 LSTM 层和一个全连接层。
- 初始化模型、损失函数和优化器。
- 在多个 epoch 中训练模型,并在每个 epoch 后打印损失。
- 在测试集上评估模型,并打印出准确率。
3、总结
LSTM 作为一种强大的循环神经网络变体,通过引入门控机制和细胞状态,有效地解决了传统 RNN 在处理长序列时遇到的梯度消失和爆炸问题。
这使得 LSTM 在处理具有长期依赖关系的序列数据时表现出色,广泛应用于自然语言处理、语音识别、时间序列预测等领域。
我是小鱼:文章来源:https://www.toymoban.com/news/detail-861286.html
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)测评一、二等奖获得者;
关注小鱼,学习机器学习领域的知识。文章来源地址https://www.toymoban.com/news/detail-861286.html
到了这里,关于【机器学习】一文搞懂算法模型之:LSTM的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!