Towards artificial general intelligence via a multimodal foundation model论文阅读
相关资料
Towards artificial general intelligence via a multimodal foundation model论文
Towards artificial general intelligence via a multimodal foundation model官方代码
Abstract
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human. Despite tremendous success in the AI research, most of existing methods have only single-cognitive ability. To overcome this limitation and take a solid step towards artificial general intelligence (AGI), we develop a foundation model pre-trained with huge multimodal data, which can be quickly adapted for various downstream cognitive tasks. To achieve this goal, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that promising results can be obtained on a wide range of downstream tasks. Particularly, with the developed modelinterpretability tools, we demonstrate that strong imagination ability is now possessed by our foundation model. We believe that our work makes a transformative stride towards AGI, from our common practice of “weak or narrow AI” to that of “strong or generalized AI”.
摘要
人工智能(AI)的根本目标是模拟人类的核心认知活动。尽管人工智能研究取得了巨大的成功,但现有的方法大多只有单一的认知能力。为了克服这一限制,并向通用人工智能(AGI)迈出坚实的一步,我们开发了一个预先训练了大量多模态数据的基础模型,该模型可以快速适应各种下游认知任务。为了实现这一目标,我们建议使用从互联网上抓取的弱语义相关数据通过自监督学习预训练我们的基础模型,并表明在广泛的下游任务上可以获得令人满意的结果。特别是,通过开发的模型可解释性工具,我们证明了我们的基础模型现在具有很强的想象能力。我们相信,我们的工作对人工智能的发展迈出了革命性的一步,从我们通常的“弱或狭义人工智能”到“强或广义人工智能”。
引言

作者动机
- 建立基础模型(也称为预训练模型)是因为它们被精确地设计为通过大规模的广泛数据预训练来适应(例如,微调)各种下游认知任务。
- 我们之所以选择从庞大的多模态数据中学习,是因为大多数人类智能行为都是在多模态环境中展示的,使用视觉文本内容作为知识和交流手段的主要载体(见图1a)。
与其他多模态工作不同
- 其他多模态工作
- 假设输入图像文本对(例如图像-标题对)具有强语义相关性,并期望图像中的对象/区域与一段文本中的单词之间具有精确匹配(见图1b)。这严重限制了这些模型的泛化能力,因为强语义关联假设在现实世界中通常是无效的,并且遵循该假设的多模态数据是有限的。
- 最新的多模态基础模型往往采用目标检测器获取有意义的图像区域,并采用单塔网络架构更好地建模细粒度的区域-词匹配(即以图像区域和文本单词的拼接为输入),这种情况变得更加严重。这两种常见的做法(即,对象检测器和单塔架构)在计算上都很昂贵,因此不适合实际应用。
- 本文工作(Bridging-Vision-and-Language, BriVL)
- 构建我们的预训练数据集
我们选择利用互联网上不需要人工注释的弱语义相关数据。如此庞大的弱语义相关性数据包含了复杂/抽象的人类情感和思想。因此,与以往的研究相比,通过直接的图像到文本的“翻译”来建模强语义相关性数据,通过图像-文本匹配来建模弱语义相关性数据将有助于我们获得更具有认知性的模型。 - 网络结构
采用简单的双塔架构(而不是单塔架构),它使用两个单独的编码器对图像和文本输入进行编码(见图1a)。请注意,双塔架构在推理过程中的效率方面具有明显的优势,因为候选项的嵌入可以在查询之前进行计算和索引,从而满足实际应用程序的延迟要求。 - 自监督学习
为了对弱图像-文本相关性进行建模,并在全局级图像/文本嵌入对齐的情况下学习统一的语义空间,我们设计了一种跨模态对比学习(CL)算法。
- 构建我们的预训练数据集
方法
BriVL的预训练目标
学习两个可以将图像和文本输入嵌入到同一语义空间的编码器,以实现有效的图像-文本检索。为了使图像和文本编码器在相同的嵌入空间中学习更好的表示,我们在BriVL中引入了使用InfoNCE loss(对比学习损失)的跨模态对比学习。具体来说,我们的学习目标是从给定的文本嵌入中找到相应的图像嵌入,反之亦然。通过最大化每个标记为正值的图像文本对的余弦相似度,同时最小化标记为负对的图像文本对的余弦相似度,我们共同训练图像和文本编码器来学习对齐的跨模态嵌入空间。
图像编码器
我们引入了一个简单而有效的模块,称为多尺度图像块池化模块(Multi-Scale Patch Pooling, MSPP)来解决图像检测器性能问题。
对于每个输入图像
x
(
i
)
x^{(i)}
x(i),我们首先将其分割成不同尺度的多个patch,并记录patch坐标。在所有的实验中,我们采用1 × 1和6 × 6两个尺度,总共得到37个patch。接下来,我们将每一组patch坐标投影到由CNN主干(例如,EfficientNet)获得的feature map上,并生成由37个区域feature map组成的序列。最后,我们对每个区域特征图进行平均池化,得到patch特征序列
S
∈
R
c
×
N
p
S\in R^{c\times N_p}
S∈Rc×Np。其中每列对应一个patch,
N
p
N_p
Np为patch的个数(即本文中
N
p
N_p
Np = 37) ,每行
c
c
c为feature map中的通道数。
为了更好地捕捉图像patch特征之间的关系,我们部署了一个包含多个Transformer编码器层的自注意力块。每个Transformer编码器层由一个多头部注意(MultiHeadAttn)层和一个前馈网络(FFN)层组成:
S
′
=
L
a
y
e
r
N
o
r
m
(
S
+
M
u
l
t
i
H
e
a
d
A
t
t
n
(
S
)
)
\begin{equation} S' = LayerNorm(S+MultiHeadAttn(S)) \end{equation}
S′=LayerNorm(S+MultiHeadAttn(S))
S
=
L
a
y
e
r
N
o
r
m
(
S
′
+
F
F
N
(
S
′
)
)
\begin{equation} S = LayerNorm(S'+FFN(S')) \end{equation}
S=LayerNorm(S′+FFN(S′))
然后,我们通过应用平均池化层融合提取的patch特征,得到最终的d维图像嵌入
z
(
i
)
∈
R
d
z^{(i)}\in R^d
z(i)∈Rd。
文本编码器
给定一个句子 x ( t ) x^{(t)} x(t),我们首先对它进行标记化,得到一个标记序列 T = { t j ∣ j = 1 , . . . , l } T=\{t_j |j = 1,..., l\} T={tj∣j=1,...,l},其中 l l l表示句子的长度(例如,单词的数量), t j t_j tj表示 T T T的第j个标记。然后使用预训练的Transformer编码器(例如RoBERTa)将文本标记映射到特征向量序列(每个特征向量对应一个单词)。同样,为了更好地捕捉单词之间的关系,我们使用与图像编码器中相同的自注意机制来提取文本表示 r ( t ) r^{(t)} r(t)。还使用带有ReLU激活层的两层MLP块将文本表示 r ( t ) r^{(t)} r(t)映射到联合跨模态嵌入空间,从而得到最终的d维文本嵌入 z ( t ) ∈ R d z^{(t)}\in R^d z(t)∈Rd。
对比损失
我们的BriVL中的跨模态对比损失是基于MoCo定义的,它提供了一种为对比学习构建动态样本队列的机制。由于我们的BriVL中使用的两个负队列将队列大小与迷你批处理大小解耦,因此我们可以拥有比迷你批处理大小大得多的负样本大小(从而节省gpu资源)。
实验
预训练数据收集
我们构建了一个巨大的网络抓取多源图像文本数据集,称为弱语义相关数据集(weak semantic correlation dataset, WSCD)作为我们的预训练数据集。WSCD从网络上的多个来源收集中文图像-文本对,包括新闻,百科全书和社交媒体。具体地说,来自这些数据源的图像及其相应/周围的文本描述被用来形成图像-文本对。由于获得的图像-文本对是从网络上抓取的,因此期望每对图像和文本是弱相关的。
- 例如,社交媒体上人们与朋友共度美好时光的图片往往有一个简单的标题: “多么美好的一天!” ,而无需对图像内容进行任何细粒度的描述并且包含情感色彩,更接近人类的认知。
请注意,我们只过滤掉WSCD中的色情/敏感数据,而没有对原始数据进行任何形式的编辑或修改,以保持数据的自然分布。
神经网络可视化
人类有一种能力(甚至是本能),当我们听到单词或描述性句子时,相关场景会进入我们的脑海。至于我们的BriVL,一旦在如此大量的松散对齐的图像-文本对上进行预训练,我们就会着迷于当给定文本时它究竟会想象什么。我们不是通过下游任务间接地检查它,而是扩展了特征可视化(Feature Visualization, FeaVis),以直接查看BriVL对语义输入的视觉响应(即想象)。FeaVis是一种仅用于将卷积神经网络的特征可视化的算法。然而,对于像我们的BriVL这样的大规模跨模态基础模型,我们可以通过使用联合图像-文本嵌入空间作为桥梁来可视化任何文本输入。
BriVL对高级概念的想象能力

- “自然”
像草一样的植物 - “time”
时钟 - “科学”
一张戴着眼镜和圆锥形烧瓶的脸 - “梦”
云,通向门的桥,梦幻般的气氛
可以看出,尽管这些概念是相当抽象的,但可视化能够表现出这些概念的具体体现。这种将抽象概念推广到一系列更具体的对象的能力是习得的常识的标志,也是我们仅使用弱语义相关数据(用抽象概念暴露模型)进行多模态预训练的有效性的标志。
BriVL对句子的想象能力

- “黑暗中总有一线光明”
不仅从字面上体现了乌云背后的阳光,而且似乎表现了海上的危险情况(左边的船状物体和波浪),表达了这句话的隐含意义。 - “让生命像夏天的花朵一样美丽”
我们可以看到一个花灌木。
接下来的两个文本输入描述了更复杂的场景,它们都来自中国古代诗歌,其语法与数据集中大多数其他文本完全不同,但是BriVL也表现不错。
- “竹外桃花三两枝”。
有竹子,有粉花。 - “白日依山尽,黄河入海流。”
我们可以看到山上的树木遮住了夕阳,还有河上的小船。
总的来说,我们发现BriVL在复杂句子作为提示语的情况下具有很强的想象能力。
BriVL对包含共享提示符的相似文本输入的想象能力

- “有森林的山脉”
图像中绿色区域较多。 - “有石头的山脉”
形象多为岩石。 - “有积雪的山脉”
中央树木周围的地面变成了白色/蓝色。 - “有瀑布的山脉”
我们可以看到蓝色的水落下,甚至可以看到蒸汽。
这些想象结果表明,我们的模型能够将特定对象与更一般的视觉环境联系起来。
BriVL对带有语义约束的神经元的想象能力

具体来说,除了上面描述的图像-文本匹配损失外,我们在图像编码器的池化层(LLP, last layer before pooling)之前的最后一层的特征映射中选择神经元(即通道),并使每个神经元的值最大化。由于每个文本输入可能包含许多语义内容,我们可以看到在一定的语义约束下激活一个神经元是什么。选择三个神经元LLP-108, LLP-456和LLP-678(数字表示每个通道在特征图中的位置)进行神经元可视化。
即使在相同的语义约束下,激活不同的神经元也会导致不同的想象结果,这表明每个文本输入都具有丰富的语义,不同的神经元捕获了不同的方面。
文字到图片的生成
我们利用VQGAN在BriVL的引导下生成图像,并与CLIP生成的图像进行对比。在ILSVRC-2012数据集上预训练的VQGAN在给定一系列token的情况下生成逼真的图像方面表现出色。每个这样的token都是来自VQGAN的预训练令牌集(即码本)的向量。我们首先随机抽取一系列token,并从预训练的VQGAN中获得生成的图像。接下来,我们将生成的图像输入到CLIP/BriVL的图像编码器中,并在文本编码器中输入一段文本。最后,我们定义了图像和文本嵌入匹配的目标,并反向传播结果梯度来更新初始标记序列。与网络/神经元可视化一样,VQGAN和CLIP/BriVL在生成过程中都是冻结的。生成的示例如图3所示:
- 在图3a, b中,我们选择了四个文本输入,分别展示了CLIP和我们的BriVL得到的结果。
- 在图3c中,我们考虑了一个更具挑战性的任务,即根据多个连贯的句子生成一系列图像。每一幅图像都是独立生成的,我们可以看到,这四幅生成的图像在视觉上是一致的,并且具有相同的风格。
- 图3d中展示了使用BriVL进行VQGAN反演获得的更多文本到图像生成示例。
遥感场景分类
为了展示我们预训练的BriVL的跨域知识转移能力和域外想象能力,我们在两个遥感场景分类基准上进行了zero-shot实验。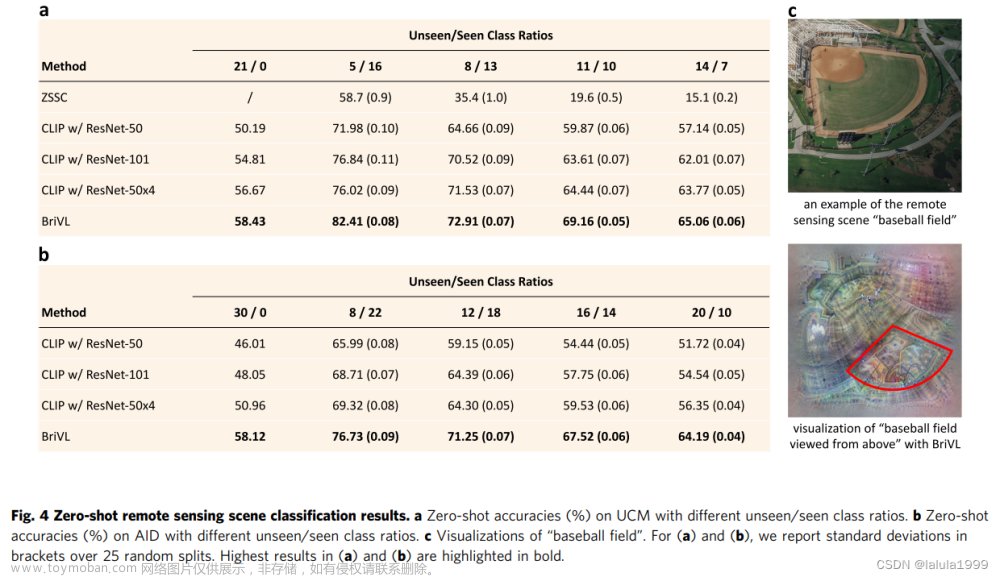
Towards artificial general intelligence via a multimodal foundation model代码复现
配置实验环境
- python 3.8.3
conda create -n BriVL python=3.8.3 -y
conda activate BriVL
- pathlib 2.3.5
pip install pathlib2==2.3.5
- yaml 0.2.5
pip install pyyaml
- easydict 1.9
pip install easydict==1.9
- pillow 7.2.0
pip install Pillow==7.2.0
- numpy 1.18.5
pip install numpy==1.18.5
- pytorch 1.7.1
- torchvision 0.8.2
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
-
安装pytorch对应版本CUDA
下载CUDA11.0 安装CUDA11.0,不安装驱动
安装CUDA11.0,不安装驱动
-
transformers 4.6.1 (installation instructions)
pip install transformers==4.6.1
- timm 0.4.9
pip install timm==0.4.9
运行代码
- 克隆环境
git clone https://github.com/neilfei/brivl-nmi.git
-
将预训练模型放入
./pretrained/文件夹
-
将找好的图片放入图像文件夹

-
编写输入数据的描述

-
修改推理代码进行推理
- 安装anaconda的kernel管理工具
pip install ipykernel- 新建kernel
python -m ipykernel install --user --name BriVL- 导入相关库
import os import argparse import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import DataLoader import numpy as np import random from datasets import ImageData, TextData from models import build_network from utils import getLanMask from utils.config import cfg_from_yaml_file, cfg- 相关参数
parser = argparse.ArgumentParser() parser.add_argument('--load_checkpoint', type=str, default='./pretrained/brivl-with-roberta-base.pth') parser.add_argument('--gpu_ids', type=str, default='0') parser.add_argument('--img_bsize', type=int, default=64) # adjust the value according to GPU memory parser.add_argument('--txt_bsize', type=int, default=64) # adjust the value according to GPU memory parser.add_argument('--max_text_len', type=int, default=32) # adjust the value according to the maximum number of Chinese characters in each piece of text # if the maximum number of Chinese characters for all texts is N, then this value should be at least N+2 # this value should not be more than 80 parser.add_argument('--data_root', type=str, default='./imgs') # your path to the folder of images parser.add_argument('--seed', type=int, default=222) parser.add_argument('--cfg_file', type=str, default='./cfg/eval.yml') args = parser.parse_args() cfg_from_yaml_file(args.cfg_file, cfg) if args.max_text_len < cfg.MODEL.MAX_TEXT_LEN: cfg.MODEL.MAX_TEXT_LEN = args.max_text_len- 报错
usage: ipykernel_launcher.py [-h] [--load_checkpoint LOAD_CHECKPOINT] [--gpu_ids GPU_IDS] [--img_bsize IMG_BSIZE] [--txt_bsize TXT_BSIZE] [--max_text_len MAX_TEXT_LEN] [--data_root DATA_ROOT] [--seed SEED] [--cfg_file CFG_FILE] ipykernel_launcher.py: error: unrecognized arguments: -f /root/.local/share/jupyter/runtime/kernel-2ef648cf-4761-4520-a9e7-b501bad7d183.json An exception has occurred, use %tb to see the full traceback. SystemExit: 2报错原因为使用argparse模块,argparse模块和ipykernel_launcher.py识别参数会出现冲突,将
args = parser.parse_args()替换为args = parser.parse_known_args()[0]即可- GPU相关设置
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_ids torch.manual_seed(args.seed) # cpu torch.cuda.manual_seed(args.seed) #gpu np.random.seed(args.seed) #numpy random.seed(args.seed) #random and transforms torch.backends.cudnn.deterministic=True # cudnn- 加载预训练模型
##### load the pre-trained model print('Loading the pre-trained model...') model = build_network(cfg.MODEL) model = model.cuda() model_component = torch.load(args.load_checkpoint, map_location=torch.device('cpu')) model.learnable.load_state_dict(model_component['learnable']) img_encoder = model.learnable['imgencoder'].eval() txt_encoder = model.learnable['textencoder'].eval() print('Done')- 加载图像数据并提取信息
##### image data img_set = ImageData(cfg, args.data_root) img_loader = DataLoader( img_set, batch_size = args.img_bsize, shuffle = False, num_workers = 8, pin_memory = True, drop_last = False ) ##### extract image features imgFea_all = [] with torch.no_grad(): for i, batch in enumerate(img_loader): images, img_lens, img_boxs = batch[0], batch[1].reshape(-1), batch[2] images = images.cuda() img_boxs = img_boxs.cuda() # get image mask imgMask = getLanMask(img_lens, cfg.MODEL.MAX_IMG_LEN) imgMask = imgMask.cuda() imgFea = img_encoder(images, imgMask, img_boxs) imgFea_l2 = F.normalize(imgFea, p=2, dim=-1) imgFea_all.append(imgFea_l2) imgFea_all = torch.cat(imgFea_all, 0)- 加载文字数据并提取信息
##### text data txt_set = TextData(cfg) txt_loader = DataLoader( txt_set, batch_size = args.txt_bsize, shuffle = False, num_workers = 8, pin_memory = True, drop_last = False ) ##### extract text features txtFea_all = [] with torch.no_grad(): for i, batch in enumerate(txt_loader): texts, text_lens = batch[0], batch[1] texts = texts.cuda() # get language mask textMask = getLanMask(text_lens, args.max_text_len) textMask = textMask.cuda() txtFea = txt_encoder(texts, textMask) txtFea_l2 = F.normalize(txtFea, p=2, dim=-1) txtFea_all.append(txtFea_l2) txtFea_all = torch.cat(txtFea_all, 0) ##### compute similarities similarity_matrix = torch.mm(imgFea_all, txtFea_all.t()) similarity_matrix
源代码只会输出相似矩阵的尺寸,这里输出了相似性矩阵文章来源:https://www.toymoban.com/news/detail-861318.html- 相似矩阵可视化

实验结论
由我们的数据可知在配置文件中的第一行、第二行和第五行是正确描述,第三行和第四行是错误描述,然而相似性矩阵的输出结果表明并不能区分正确还是错误描述,这可能和文字的描述过于简单有关。
对于第六行的COCO数据集的小狗,虽然有较长的文字描述,仍然和前几张猫猫狗狗的推理结果一样,并不能有这很好的对应结果。
对于第七行的复杂内容数据,可能由于不是常见的场景类型,也没有很好的结果。
而第八行到第九行的数据我们给出了更加精准的文字描述并且图片内容较为简单,图文相似度显著提高。文章来源地址https://www.toymoban.com/news/detail-861318.html
到了这里,关于【代码复现】BriVL:人大在Nature上发布的多模态图文认知基础模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!