本文重点
在深度学习和人工智能的浪潮中,神经网络作为其中的核心力量,发挥着举足轻重的作用。然而,神经网络的性能并非一蹴而就,而是需要经过精心的参数选择和调优。
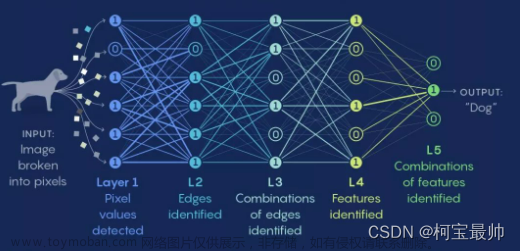
神经网络由大量的神经元组成,每个神经元之间通过权重进行连接。这些权重,以及神经元的偏置、激活函数等,共同构成了神经网络的模型参数。模型参数的选择直接影响到神经网络的性能,包括学习速度、收敛性、泛化能力等。

初始化方法的选择
初始化是神经网络训练的第一步,其重要性不言而喻。权重和偏置的初始化方法主要有随机初始化和预训练模型初始化两种。
随机初始化:为了避免权重的对称性,通常采用随机初始化方法。然而,随机初始化需要设置合适的范围,以避免权重过小导致信号传播过弱或过大导致梯度消失或爆炸。
预训练模型初始化:在某些情况下,可以使用预训练的模型作为初始参数。这种方法可以利用已有模型的知识,加速新模型的训练过程。
激活函数的选择
激活函数是神经网络中不可或缺的一部分,它决定了神经元的输出方式。常用的激活函数包括ReLU、Sigmoid、Tanh等。不同的激活函数具有不同的特性,需要根据实际任务进行选择。
ReLU:ReLU函数具有简单、高效的特点,可以解决梯度消失的问题,并加速网络的收敛速度。然而,ReLU在负输入时会将神经元置为零,可能导致部分神经元“死亡”。文章来源:https://www.toymoban.com/news/detail-861392.html
Sigmoid:Sigmoid函数可以将输入映射到0到1之间,但其梯度在饱和区接近于零&#x文章来源地址https://www.toymoban.com/news/detail-861392.html
到了这里,关于每天五分钟机器学习:神经网络模型参数的选择的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!