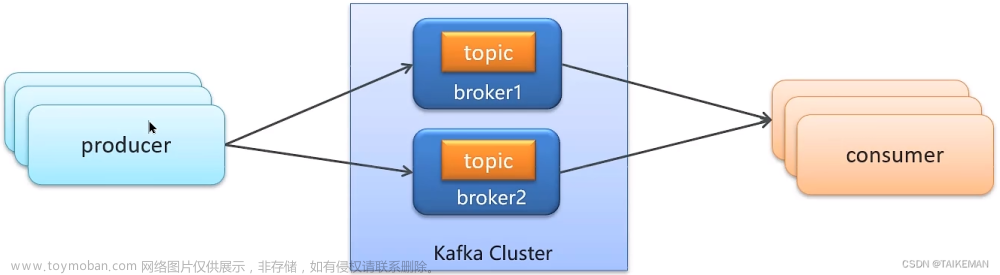
4、深入应用
4.1 springboot-kafka
1)配置文件
kafka:
bootstrap-servers: 192.168.10.30:10903,192.168.10.30:10904
producer: # producer 生产者
retries: 0 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 # 一次最多发送数据量
buffer-memory: 33554432 # 生产端缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # consumer消费者
group-id: javagroup # 默认的消费组ID
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
auto-offset-reset: latest #earliest,latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer2)启动信息

4.2 消息发送
4.2.1 发送类型
KafkaTemplate调用send时默认采用异步发送,如果需要同步获取发送结果,调用get方法
详细代码参考:AsyncProducer.java
消费者使用:KafkaConsumer.java
1)同步发送
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("test", JSON.toJSONString(message));
//注意,可以设置等待时间,超出后,不再等候结果
SendResult<String, Object> result = future.get(3,TimeUnit.SECONDS);
logger.info("send result:{}",result.getProducerRecord().value());通过swagger发送,控制台可以正常打印send result
swagger访问地址:http://localhost:8080/doc.html
2)阻断
在服务器上,将kafka暂停服务
docker-compose -f km.yml pause kafka-1 kafka-2在swagger发送消息
调同步发送:请求被阻断,一直等待,超时后返回错误

而调异步发送的(默认发送接口),请求立刻返回。

那么,异步发送的消息怎么确认发送情况呢???往下看!
3)注册监听
代码参考: KafkaListener.java (释放注解)
可以给kafkaTemplate设置Listener来监听消息发送情况,实现内部的对应方法
kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {});
查看控制台,等待一段时间后,异步发送失败的消息会被回调给注册过的listener
com.itheima.demo.config.KafkaListener:error!message={"message":"1","sendTime":1609920296374}启动kafka
docker-compose unpause kafka-1 kafka-2再次发送消息时,同步异步均可以正常收发,并且监听进入success回调
com.itheima.demo.config.KafkaListener$1:ok,message={"message":"1","sendTime":1610089315395}
com.itheima.demo.controller.PartitionConsumer:patition=1,message:[{"message":"1","sendTime":1610089315395}]可以看到,在内部类 KafkaListener$1 中,即注册的Listener的消息。
4.2.2 序列化
消费者使用:KafkaConsumer.java
1)序列化详解
- 前面用到的是Kafka自带的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer)
- 除此之外还有:ByteArray、ByteBuffer、Bytes、Double、Integer、Long 等
- 这些序列化器都实现了接口 (org.apache.kafka.common.serialization.Serializer)
- 基本上,可以满足绝大多数场景
2)自定义序列化
自己实现,实现对应的接口即可,有以下方法:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
}
//理论上,只实现这个即可正常运行
byte[] serialize(String var1, T var2);
//默认调上面的方法
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {
}
}案例,参考: MySerializer.java
在yaml中配置自己的编码器
value-serializer: com.test.demo.config.MySerializer
重新发送,发现:消息发送端编码回调一切正常。但是消费端消息内容不对!
com.itheima.demo.controller.KafkaListener$1:ok,message={"message":"1","sendTime":1609923570477}
com.itheima.demo.controller.KafkaConsumer:message:"{\"message\":\"1\",\"sendTime\":1609923570477}"3)解码
发送端有编码并且我们自己定义了编码,那么接收端自然要配备对应的解码策略
代码参考:MyDeserializer.java,实现方式与编码器几乎一样!
在yaml中配置自己的解码器
value-deserializer: com.itheima.demo.config.MyDeserializer再次收发,消息正常
com.itheima.demo.controller.AsyncProducer$1:ok,message={"message":"1","sendTime":1609924855896}
com.itheima.demo.controller.KafkaConsumer:message:{"message":"1","sendTime":1609924855896}4.2.3 分区策略
分区策略决定了消息根据key投放到哪个分区,也是顺序消费保障的基石。
- 给定了分区号,直接将数据发送到指定的分区里面去
- 没有给定分区号,给定数据的key值,通过key取上hashCode进行分区
- 既没有给定分区号,也没有给定key值,直接轮循进行分区
- 自定义分区,你想怎么做就怎么做
1)验证默认分区规则
发送者代码参考:PartitionProducer.java
消费者代码使用:PartitionConsumer.java
通过swagger访问setKey:


再访问setPartition来设置分区号0来发送


2)自定义分区
你想自己定义规则,根据我的要求,把消息投放到对应的分区去? 可以!
参考代码:MyPartitioner.java , MyPartitionTemplate.java ,
发送使用:MyPartitionProducer.java
使用swagger,发送0开头和非0开头两种key试一试!

备注:
自己定义config参数,比较麻烦,需要打破默认的KafkaTemplate设置
可以将KafkaConfiguration.java中的getTemplate加上@Bean注解来覆盖系统默认bean
这里为了避免混淆,采用@Autowire注入。
4.3 消息消费
4.3.1 消息组别
发送者使用:KafkaProducer.java
1)代码参考:GroupConsumer.java,Listener拷贝3份,分别赋予两组group,验证分组消费:


通过swagger发送2条消息

- 同一group下的两个消费者,在group1均分消息
- group2下只有一个消费者,得到全部消息
4)消费端闲置
注意分区数与消费者数的搭配,如果 ( 消费者数 > 分区数量 ),将会出现消费者闲置,浪费资源!
验证方式:
停掉项目,删掉test主题,重新建一个 ,这次只给它分配一个分区。
重新发送两条消息,试一试

解析:
group2可以消费到1、2两条消息
group1下有两个消费者,但是只分配给了 -1 , -2这个进程被闲置
4.3.2 位移提交
1)自动提交
前面的案例中,我们设置了以下两个选项,则kafka会按延时设置自动提交
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)2)手动提交
有些时候,我们需要手动控制偏移量的提交时机,比如确保消息严格消费后再提交,以防止丢失或重复。
下面我们自己定义配置,覆盖上面的参数
代码参考:MyOffsetConfig.java
通过在消费端的Consumer来提交偏移量,有如下几种方式:
代码参考:MyOffsetConsumer.java
同步提交、异步提交:manualCommit() ,同步异步的差别,下面会详细讲到。
指定偏移量提交:offset()
3)重复消费问题
如果手动提交模式被打开,一定不要忘记提交偏移量。否则会造成重复消费!
代码参考和对比:manualCommit() , noCommit()
验证过程:
用km将test主题删除,新建一个test空主题。方便观察消息偏移 注释掉其他Consumer的Component注解,只保留当前MyOffsetConsumer.java 启动项目,使用swagger的KafkaProducer发送连续几条消息 留心控制台,都能消费,没问题:

但是!重启试试:

无论重启多少次,不提交偏移量的消费组,会重复消费一遍!!!
再通过命令行查询偏移量试试:

4)经验与总结
commitSync()方法,即同步提交,会提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,commitSync()会一直重试,但是commitAsync()不会。
这就造成一个陷阱:
如果异步提交,针对偶尔出现的提交失败,不进行重试不会有太大问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。只要成功一次,偏移量就会提交上去。
但是!如果这是发生在关闭消费者时的最后一次提交,就要确保能够提交成功,如果还没提交完就停掉了进程。就会造成重复消费!
因此,在消费者关闭前一般会组合使用commitAsync()和commitSync()。
详细代码参考:MyOffsetConsumer.manualOffset()5、高级特性
5.1 扩展性
5.1.1 broker扩容
1)在yaml中复制kafka-2,拷贝为新的节点,注意以下标注修改的地方!
#修改后的内容参考:cluster.yml
kafka-3: #改
container_name: kafka-3 #改
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10905:9092 #改
environment:
KAFKA_BROKER_ID: 3 #改
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10905 #改
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper 完整的 cluster.yml
version: '3'
services:
zookeeper:
image: zookeeper:3.4.13
kafka-1:
container_name: kafka-1
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10903:9092
environment:
KAFKA_BROKER_ID: 1
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#docker部署必须设置外部可访问ip和端口,否则注册进zk的地址将不可达造成外部无法连接
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10903
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
kafka-2:
container_name: kafka-2
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10904:9092
environment:
KAFKA_BROKER_ID: 2
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10904
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
km:
image: liggdocker/km:2002
ports:
- 10906:9000
depends_on:
- zookeeper
kafka-3: #改
container_name: kafka-3 #改
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10905:9092 #改
environment:
KAFKA_BROKER_ID: 3 #改
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10905 #改
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
2)更新docker集群信息
docker-compose -f cluster.yml up -d
#启动消息
kafka_zookeeper_1 is up-to-date
kafka_km_1 is up-to-date
kafka-1 is up-to-date
kafka-2 is up-to-date
Creating kafka-3 ... done3)进命令行,或打开km查看新的broker信息

5.1.2 分区扩容
1)使用km对test主题增加分区到3个,看分区分配机器情况
 可以指定新分区数量,及分配到的机器
可以指定新分区数量,及分配到的机器

2)注意问题
新加分区或重新调整分区,已经启动的客户端会动态更新对应的分配信息,不需要重启。
但是!!!
在同步变更消息的过程中有可能会丢失消息!想想为什么?(答案在下面)
(注意!以下场景不保证100%会重现!)

答案:
回顾一下消费偏移量的默认提交配置:latest,因为新分区没有任何offset提交记录
所以会在重新分配分区后从末尾开始消费!
那么分配前的那些消息就不会消费到。而分配后再发送的不会受影响,可以正常消费
分区分配正常后,查看偏移量提交信息,没问题:

km的Consumer页签里也可以查看偏移量信息:

5.2 高可用
以上动态扩容操作是怎么实现的呢?集群中必然有一个节点协调了相关操作。
这台协调者,就是controller节点。
controller节点是其中的一台broker,所有broker都有可能成为controller
当前controller宕机后,其他就会参与竞争,选出新的controller,保持集群对外的高可用
5.2.1 节点选举
1)查找controller,找到它所在的broker
1)查找controller,找到它所在的broker
#查找docker进程,找到zookeeper的容器
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker ps --format "table{{.ID}}\t{{.Names}}\t{{.Ports}}"
CONTAINER ID NAMES PORTS
75318748caab kafka-3 0.0.0.0:10905->9092/tcp
4807d188a180 kafka_km_1 0.0.0.0:10906->9000/tcp
4453eb0b2a36 kafka-2 0.0.0.0:10904->9092/tcp
d6fd814a0851 kafka-1 0.0.0.0:10903->9092/tcp
8c1fc2cc6e9a kafka_zookeeper_1 2181/tcp, 2888/tcp, 3888/tcp
#进入容器,连上zk
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker exec -it kafka_zookeeper_1 sh
/zookeeper-3.4.13 #
/zookeeper-3.4.13 # zkCli.sh
Connecting to localhost:2181
#查询当前controller是哪个节点,发现是2号机器(有可能是其他节点,找到这个brokerid,下面要用!)
[zk: localhost:2181(CONNECTED) 6] get /controller
{"version":1,"brokerid":2,"timestamp":"1610500701187"}
#controller变更的次数
[zk: localhost:2181(CONNECTED) 7] get /controller_epoch
1
2)docker-compose停掉它!
#docker pause 暂停容器的服务,注意是上面找到的那台broker
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker pause kafka-2
kafka-2
#查看状态,发现(Paused)
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker ps | grep kafka-2
4453eb0b2a36 wurstmeister/kafka:2.12-2.2.2 "start-kafka.sh" 2 days ago Up 2 days (Paused) 0.0.0.0:10904->9092/tcp kafka-2
#再次按 1)的步骤进入zk容器,查看当前controller,已经变为3号
[zk: localhost:2181(CONNECTED) 0] get /controller
{"version":1,"brokerid":3,"timestamp":"1610679583216"}
#变更次数加了1
[zk: localhost:2181(CONNECTED) 1] get /controller_epoch
25.2.2 原理剖析
当控制器被关闭或者与Zookeeper系统断开连接时,Zookeeper系统上的/controller临时节点就会被清除。
Kafka集群中的监听器会接收到变更通知,各个代理节点会尝试到Zookeeper系统中创建它。
第一个成功在Zookeeper系统中创建的代理节点,将会成为新的控制器。
每个新选举出来的控制器,会在Zookeeper系统中递增controller_epoch的值。
附:详细流程图文章来源:https://www.toymoban.com/news/detail-861620.html
 文章来源地址https://www.toymoban.com/news/detail-861620.html
文章来源地址https://www.toymoban.com/news/detail-861620.html
到了这里,关于架构师系列- 消息中间件(13)-kafka深入应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!