一、Dropout
1. 概念
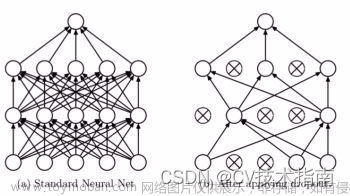
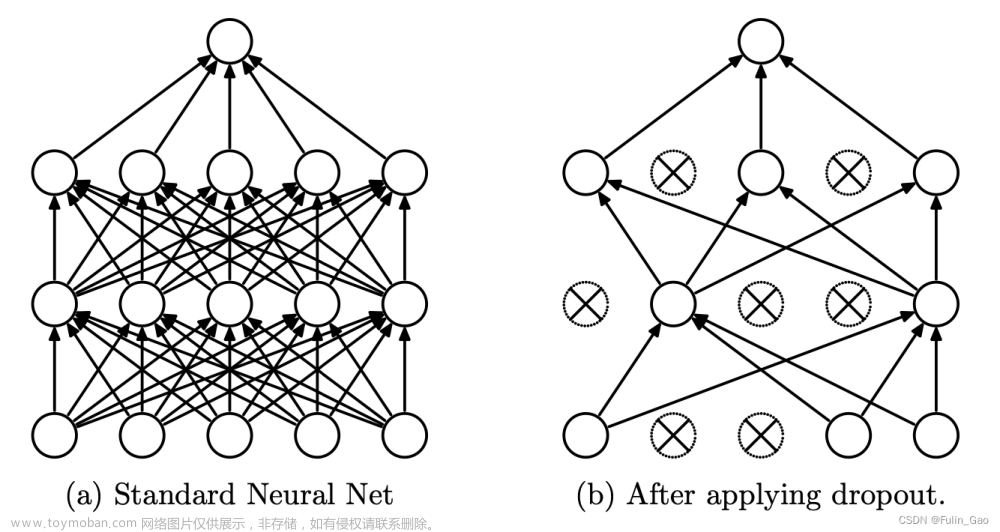
Dropout 在训练阶段会让当前层每个神经元以drop_prob( 0 ≤ drop_prob ≤ 1 0\leq\text{drop\_prob}\leq1 0≤drop_prob≤1)的概率失活并停止工作,效果如下图。
在测试阶段不会进行Dropout。由于不同批次、不同样本的神经元失活情况不同,测试时枚举所有情况进行推理是不现实的,所以原文使用一种均值近似的方法进行逼近。详情如下图:
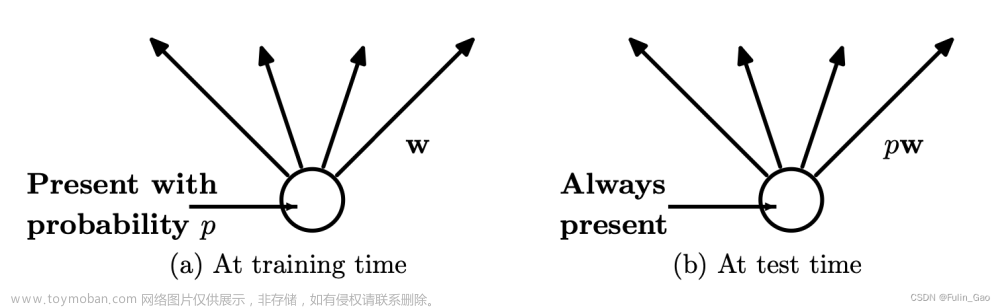
如图, w \bold{w} w为一个神经元后的权重。假设该神经元的输出均值为 μ \mu μ,若训练阶段该神经元的存活概率为 p p p,则Dropout使其输出均值变为 p × μ p\times\mu p×μ,为使测试时该神经元输出逼近训练输出,测试阶段该神经元输出会被乘上 p p p以使测试与训练输出均值相同。
简单来说,训练时Dropout按照概率drop_prob使神经元停止工作,测试时所有神经元正常工作,但其输出值要乘上1-drop_prob( p = 1 − drop_prob p=1-\text{drop\_prob} p=1−drop_prob)。
不过,我们希望测试代码执行效率尽可能高,即便仅增加一个概率计算也不是我们希望的。所以实际计算时,会在训练阶段给神经元乘上一个缩放因子 1 p \frac{1}{p} p1。这样,训练输出的均值仍为 μ \mu μ,测试则不进行Dropout也不再乘上 p p p而是原样输出。
2. 功能
优势:
Dropout能够提高网络的泛化能力,防止过拟合。解释如下:
(1) 训练阶段每个神经元是相互独立的,仅drop_prob相同,即使是同一批次不同样本失活的神经元也是不同的。所以原文作者将Dropout的操作视为多种模型结构下结果的集成,由于集成方法能够避免过拟合,因此Dropout也能达到同样的效果。
(2) 减少神经元之间的协同性。有些神经元可能会建立与其它节点的固定联系,通过Dropout强迫神经元和随机挑选出来的其它神经元共同工作,减弱了神经元节点间的联合适应性,增强了泛化能力。
劣势:
(1) Dropout减缓了收敛的速度。训练时需要通过伯努利分布生成是否drop每一个神经元的情况,额外的乘法和缩放运算也会增加时间。
(2) Dropout一般用于全连接层,卷积层一般使用BatchNorm来防止过拟合。Dropout与BatchNorm不易兼容,Dropout导致训练过程中每一层输出的方差发生偏移,使得BatchNorm层统计的方差不准确,影响BatchNorm的正常使用。
3. 实现
import torch.nn as nn
import torch
class dropout(nn.Module):
def __init__(self, drop_prob):
super(dropout, self).__init__()
assert 0 <= drop_prob <= 1, 'drop_prob should be [0, 1]'
self.drop_prob = drop_prob
def forward(self, x):
if self.training:
keep_prob = 1 - self.drop_prob
mask = keep_prob + torch.rand(x.shape)
mask.floor_()
return x.div(keep_prob) * mask
else:
return x
if __name__ == '__main__':
x = torch.randn((8, 768)) # [batch_size, feat_dim],dropout常在全连接层之后,所以我们以一维数据为例
drop = dropout(0.1)
my_o = drop(x)
二、DropPath
1. 概念
DropPath 在训练阶段将深度学习网络中的多分支结构随机删除,效果如下图:
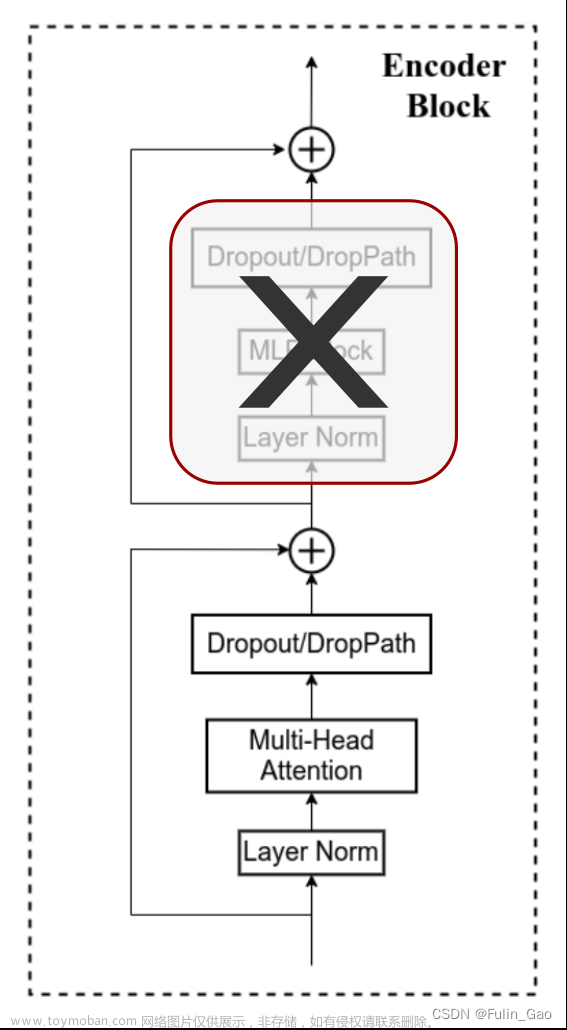
上图是ViT中的一个模块,多分支体现在ResNet结构的引入。可以看出,DropPath在多分支中起作用对位置有明确的要求,需要放在分支合并之前。此外,DropPath也需要对训练输出进行缩放(乘 1 1 − drop_prob \frac{1}{1-\text{drop\_prob}} 1−drop_prob1)以确保测试输出结果的有效性和计算的高效性,这样在测试阶段就不会进行DropPath。
事实上,DropPath功能的实现是按照drop_prob概率将该分支的当前输出全部置0。具体来说,对于某个含有DropPath的分支,该分支输出的一个批次的每个样本都独立的按照drop_prob概率被完全置0或完整保留。
2. 功能
一般可以作为正则化手段加入网络防止过拟合,但会增加网络训练的难度。如果设置的drop_prob过高,模型甚至有可能不收敛。文章来源:https://www.toymoban.com/news/detail-861680.html
3. 实现
import torch
import torch.nn as nn
class DropPath(nn.Module):
"""
随机丢弃该分支上的每个样本
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
if self.drop_prob == 0. or not self.training:
return x
keep_prob = 1 - self.drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # (batch_size, 1, 1, 1)维数与输入保持一致,仅需要batch_size个值
mask = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
mask.floor_() # 二值化,向下取整用于确定保存哪些样本
output = x.div(keep_prob) * mask
return output
if __name__ == "__main__":
x = torch.randn((8, 197, 768)) # [batch_size, num_token, token_dim]
drop_path = DropPath(drop_prob=0.5)
my_o = drop_path(x)
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
【个人理解向】Dropout和Droppath原理及源码讲解
nn.Dropout、DropPath的理解与pytorch代码
Drop系列正则化文章来源地址https://www.toymoban.com/news/detail-861680.html
到了这里,关于【深度学习】Dropout、DropPath的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![计算机视觉与深度学习-全连接神经网络-训练过程-欠拟合、过拟合和Dropout- [北邮鲁鹏]](https://imgs.yssmx.com/Uploads/2024/02/732361-1.png)