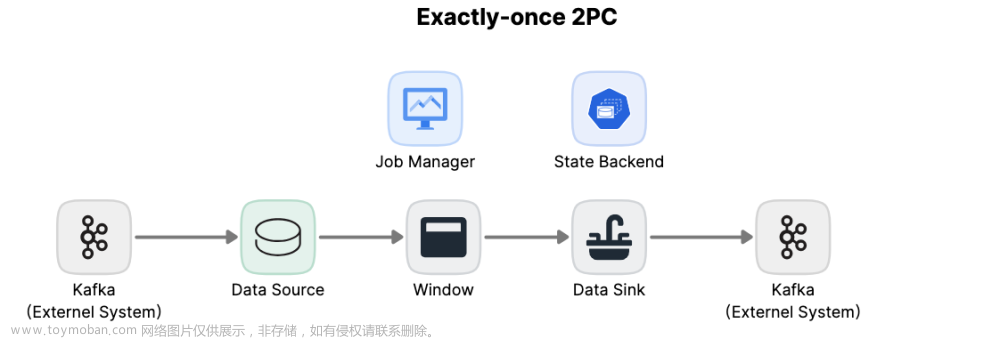
在 Apache Flink 中,checkpoint 机制是实现容错和状态一致性的关键组件。其中,精确一次(Exactly-Once)处理模式通过两阶段提交协议来确保每个事件只被处理一次,即使在发生故障时也能保持状态的一致性。下面我将对 Flink 的 checkpoint 两阶段提交协议进行详细解释,并通过一个例子来加深理解。
一:两阶段提交协议详解
两阶段提交协议是一个经典的分布式事务处理协议,用于确保在多个参与者之间协调一致地执行事务。在 Flink 的 context 中,这个协议用于 checkpoint 的精确一次处理。
1.1 流程
第一阶段:预提交(Pre-Commit)
- 协调者发起请求:Flink 的协调者(通常是 JobManager)向所有参与 checkpoint 的任务(通常是 TaskManagers)发送一个预提交请求。
- 参与者响应:每个任务接收到请求后,会将其内部状态(例如算子状态)写入外部存储(如 HDFS)。这些状态数据是恢复时所需要的。一旦状态数据被成功写入,任务会向协调者发送一个确认消息。
- 故障处理:如果某个任务在写入状态数据时遇到故障,它会向协调者发送一个失败消息。在这种情况下,协调者会触发回滚,即放弃当前的 checkpoint,并回滚到上一个成功的 checkpoint。
第二阶段:提交(Commit)
- 协调者决策:当协调者收到所有任务的确认消息后,它会决定提交这个 checkpoint。然后,协调者会向所有任务发送一个提交消息。
- 参与者提交:任务在收到提交消息后,会正式地提交它们之前写入的状态数据。这意味着这些状态数据现在对外部世界是可见的,可以用于恢复操作。
- 完成通知:一旦所有任务都完成了提交操作,协调者会收到一个通知,并标记这个 checkpoint 为已完成。此时,即使系统发生故障,Flink 也可以从这个 checkpoint 恢复,确保每个事件只被处理一次。
1.2 举例
假设我们有一个简单的 Flink 作业,该作业读取 Kafka 中的数据,进行一些转换,并将结果写入另一个 Kafka 主题。这个作业配置了精确一次处理模式,并使用了两阶段提交协议进行 checkpoint。
-
正常流程:
- 当触发 checkpoint 时,JobManager 向所有 TaskManagers 发送预提交请求。
- TaskManagers 将状态数据(如 Kafka 的 offset 和内部算子状态)写入 HDFS。
- 一旦所有数据都被成功写入,TaskManagers 向 JobManager 发送确认消息。
- JobManager 收到所有确认后,发送提交消息给 TaskManagers。
- TaskManagers 提交状态数据,并通知 JobManager。
- JobManager 标记 checkpoint 为完成。
-
故障处理:
- 如果在预提交阶段,某个 TaskManager 写入状态数据失败(例如网络问题或磁盘故障),它会向 JobManager 发送失败消息。
- JobManager 收到失败消息后,会触发回滚操作,放弃当前的 checkpoint,并回滚到上一个成功的 checkpoint。
- 如果在提交阶段发生故障(例如 JobManager 崩溃),Flink 会在恢复时检查外部存储中的状态数据。由于预提交阶段已经成功写入数据,Flink 可以从这个状态恢复,并继续处理数据。
通过这个例子,我们可以看到两阶段提交协议如何确保 Flink 在分布式环境中实现精确一次处理。即使在发生故障时,Flink 也能通过回滚和恢复机制来保持数据的一致性。
二:Flink的checkpoint精确一次(Exactly-Once)处理模式并不能保证在所有情况下都绝对不会出现数据不一致的问题。
尽管Flink通过一系列机制(如两阶段提交协议、状态快照等)努力确保数据的一致性,但在分布式系统中,尤其是在处理大量数据和高并发场景下,仍然可能会遇到一些极端情况或故障,导致数据不一致。
例如,在网络分区、节点故障或长时间GC停顿等情况下,可能会导致消息丢失、重复处理或状态更新不一致。此外,如果Flink程序的配置不当或存在bug,也可能影响到数据的一致性。
因此,虽然Flink的checkpoint精确一次处理模式提供了很高的数据一致性保证,但在实际应用中,我们仍然需要谨慎处理可能出现的异常情况,并结合具体的业务场景和需求来设计和实现数据一致性保障机制。同时,定期检查和验证数据的准确性也是非常重要的。
总的来说,Flink的checkpoint精确一次处理模式可以大大提高数据一致性的保障程度,但并不能完全消除数据不一致的风险。在使用时,我们需要结合实际情况进行综合考虑和配置。
三:Flink的checkpoint精确一次和最少一次区别
在 Flink 的容错机制中,checkpoint 扮演了至关重要的角色。它允许 Flink 在故障发生时从上一个成功的检查点恢复状态,从而确保数据处理的连续性和准确性。其中,精确一次(Exactly-Once)和最少一次(At-least-Once)是两种不同的语义保证,它们在数据处理的可靠性和一致性方面存在显著的区别。
精确一次(Exactly-Once):
精确一次语义是 Flink 追求的最高级别的容错保证。在精确一次模式下,Flink 确保每条数据从源端(Source)到目标端(Sink)的处理过程中只被精确处理一次,既不多也不少。这通常通过两阶段提交协议(Two-Phase Commit Protocol)实现,确保在事务提交之前,所有的状态变更都是预备性的,只有在所有参与者都确认能够成功提交后,事务才会被正式提交。这种机制确保了即使在故障发生时,已经处理的数据不会丢失,而未处理的数据也不会被重复处理,从而保证了数据的一致性。
最少一次(At-least-Once):
相比之下,最少一次语义提供了较低的容错保证。在最少一次模式下,Flink 至少会确保每条数据从源端到目标端的处理过程中至少被处理一次。这意味着在故障发生时,已经处理的数据可能会被重复处理,但绝对不会被忽略。这种语义通常不采用两阶段提交协议,而是依赖于简单的重试机制。当某个任务失败时,Flink 会简单地重试该任务,直到成功为止。这种策略虽然简单,但可能会导致数据的重复处理,特别是在频繁发生故障的情况下。
总结:
精确一次和最少一次的主要区别在于对数据处理的一致性和可靠性的保证程度。精确一次通过复杂的两阶段提交协议确保每条数据只被处理一次,提供了最高的数据一致性保证;而最少一次则通过简单的重试机制确保数据至少被处理一次,但可能会引入数据的重复处理。在实际应用中,需要根据具体的业务需求和场景来选择适合的语义保证。对于需要严格保证数据一致性的场景(如金融交易),通常会选择精确一次语义;而对于一些对数据处理速度有较高要求且可以容忍一定程度数据重复的场景(如日志收集),则可能会选择最少一次语义。
四:扩展之网络分区问题普及
二阶段提交协议(2PC)在分布式系统中用于确保事务的原子性,但网络分区问题可能会对这一协议的执行造成严重影响。网络分区指的是分布式系统中的节点因网络故障或其他原因而无法互相通信的状态。当这种情况发生时,原本应协同工作的节点被分割成相互隔离的子集,导致数据一致性和服务可用性的问题。
假设有一个分布式数据库系统,包含多个数据库节点,它们通过二阶段提交协议来确保事务的一致性。这些节点中的一部分位于一个子网A,另一部分位于另一个子网B。现在,由于网络故障,子网A和子网B之间的通信被切断,形成了网络分区。
-
事务发起:客户端发起一个跨多个节点的事务请求。
-
阶段一:预提交:
- 协调者节点向所有参与者节点发送“预提交”请求。
- 位于子网A的参与者节点正常接收并响应“预提交”请求,锁定资源并准备提交。
- 由于网络分区,位于子网B的参与者节点无法接收到“预提交”请求。
-
协调者等待响应:协调者等待所有参与者节点的响应。由于子网B的节点无响应,协调者可能进入等待状态或超时。
-
阶段二:提交或回滚:
- 如果协调者因等待子网B的响应而超时,它可能无法确定如何继续,因为它不知道子网B中的节点状态。
- 如果协调者基于子网A的响应决定提交事务,那么子网A中的节点会提交事务,但子网B中的节点因未收到指令而保持原状态,导致数据不一致。
- 如果协调者决定回滚事务,子网A中的节点会回滚,但子网B中的节点依然未知状态。
-
数据不一致:当网络恢复后,子网A和子网B的节点数据可能不一致,因为它们在网络分区期间没有协同完成事务。文章来源:https://www.toymoban.com/news/detail-861696.html
为了解决这个问题,可以采取一些策略,如引入超时机制来处理通信中断的情况,使用心跳机制检测节点的存活状态,以及在网络恢复后进行数据补偿来恢复数据一致性。然而,这些策略并不能完全消除网络分区带来的风险,因此在设计分布式系统时,需要综合考虑网络分区的可能性和其对二阶段提交协议的影响。文章来源地址https://www.toymoban.com/news/detail-861696.html
到了这里,关于flink checkpoint 两阶段提交协议详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!