前言
2023-9-4 09:20:52
以下内容源自《【Java】》
仅供学习交流使用
版权
禁止其他平台发布时删除以下此话
本文首次发布于CSDN平台
作者是CSDN@日星月云
博客主页是https://blog.csdn.net/qq_51625007
禁止其他平台发布时删除以上此话
推荐
【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)
kafka学习笔记
链接: https://pan.baidu.com/s/19Bcvf1oUwQP1UIJMlEg5Xw
提取码: wkb4
Kafka
第1章 Kafka概述【Kafka】
第2章 Kafka快速入门【Kafka】
第3章 Kafka生产者【Kafka】
第4章 Kafka Broker【Kafka】
第5章 Kafka消费者【Kafka】
第6章 Kafka-Eagle监控【Kafka】
第7章 Kafka-Kraft模式【Kafka】
随堂笔记
一、概述
1、定义
1)传统定义
分布式 发布订阅 消息队列
发布订阅:分为多种类型 订阅者根据需求 选择性订阅
2)最新定义
流平台(存储、计算)
2、消息队列应用场景
1)缓存消峰
2)解耦
3)异步通信
3、两种模式
1)点对点
(1)一个生产者 一个消费者 一个topic 会删除数据 不多
2)发布订阅
(1)多个生产者 消费者多个 而且相互独立 多个topic 不会删除数据
4、架构
1)生产者
100T数据
2)broker
(1)broker 服务器 hadoop102 103 104
(2)topic 主题 对数据分类
(3)分区
(4)可靠性 副本
(5)leader follower
(6)生产者和消费者 只针对leader操作
3)消费者
(1)消费者和消费者相互独立
(2)消费者组 (某个分区 只能由一个消费者消费)
4)zookeeper
(1)broker.ids 0 1 2
(2)leader
二、入门
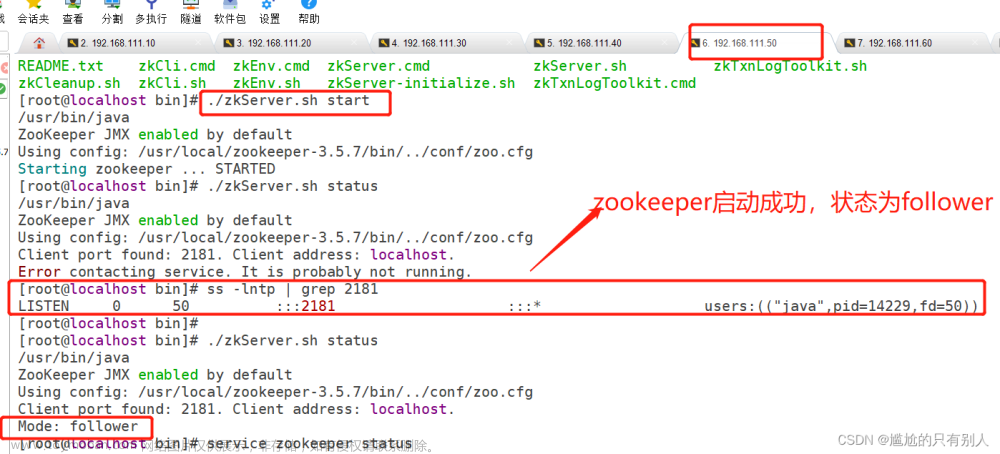
1、安装
1)broker.id 必须全局唯一
2)broker.id、log.dirs zk/kafka
3)启动停止 先停止kafka 再停zk
4)脚本
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
ssh $i "绝对路径"
done
;;
"stop")
;;
esac
2、常用命令行
1)主题 kafka-topic.sh
(1)--bootstrap-server hadoop102:9092,hadoop103:9092
(2)--topic first
(3)--create
(4)--delete
(5)--alter
(6)--list
(7)--describe
(8)--partitions
(9)--replication-factor
2)生产者 kafka-console-producer.sh
(1)--bootstrap-server hadoop102:9092,hadoop103:9092
(2)--topic first
3)消费者 kafka-console-consumer.sh
(1)--bootstrap-server hadoop102:9092,hadoop103:9092
(2)--topic first
三、生产者
1、原理
2、异步发送API
0)配置
(1)连接 bootstrap-server
(2)key value序列化
1)创建生产者
KafkaProducer<String,String>()
2)发送数据
send() send(,new Callback)
3)关闭资源
3、同步发送
。。。
send() send(,new Callback).get()
。。。
4、分区
1)好处
存储
计算
2)默认分区规则
(1)指定分区 按分区走
(2)key key的hashcode值%分区数
(3)没有指定key 没有指定分区 粘性
第一随机
3)自定义分区
定义类 实现partitioner接口
5、吞吐量提高
1)批次大小 16k 32k
2)linger.ms 0 => 5-100ms
3)压缩
4)缓存大小 32m => 64m
6、可靠性
acks
0 丢失数据
1 也可能会丢 传输普通日志
-1 完全可靠 + 副本大于等于2 isr >=2 => 数据重复
7、数据重复
1)幂等性
<pid, 分区号,序列号>
默认打开
2)事务
底层基于幂等性
(1)初始化
(2)启动
(3)消费者offset
(4)提交
(5)终止
8、数据有序
单分区内有序(有条件)
多分区有序怎么办?
9、乱序
1)inflight =1
2)没有幂等性 inflight =1
3)有幂等性
四、broker
1、zk存储了哪些信息
(1)broker.ids
(2)leader
(3)辅助选举 controller
2、工作流程
3、服役
1)准备一台干净服务器 hadoop100
2)对哪个主题操作
3)形成计划
4)执行计划
5)验证计划
4、退役
1)要退役的节点不让存储数据
2)退出节点
5、副本
1)副本的好处 提高可靠性
2)生产环境中通常2个 默认1个
3)有leader follower leader
4)isr
5)controller isr[0 2 3 ] 存活 ar [0 1 2 3]
6)Leader 挂了
7)follower 挂了
8)副本分配 默认
9)手动副本分配 制定计划 执行计划 验证计划
10)leader partition的负载均衡 10%
11)手动增加副本因子
6、存储机制
broker topic partition log segment 1g 稀疏索引 4kb
7、删除数据
默认7天 3天 7小时
两种 删除 压缩
删除:
压缩:
8、高效读写
1)集群 采用分区
2)稀疏索引
3)顺序读写
4)零拷贝 和页缓存
五、消费者
1、总体流程
2、消费者组
3、按照主题消费
0)配置信息
连接
反序列化
组id
1)创建消费者
2)订阅主题
3)消费数据
4、按照分区
5、消费者组案例
组id
6、分区分配策略 再平衡
7个分区 3个消费者
range
0 1 2 x
3 4
5 6
roundrobin
轮询
0 3 6
1 4
2 5
粘性 2 2 3
0 3 4
2 6
1 5
7、offset
1)默认存储在系统主题
2)自动提交 5s 默认
3)手动提交 同步 异步
4)指定offset消费 seek ()
5)按照时间消费
6)漏消费 重复消费
8、事务
生产端 =》 集群
集群 =》 消费者
消费者 =》 框架
9、数据积压
1、增加分区 增加消费者个数
2、生产 =》 集群 4个参数
3、消费端 两个参数 50m 500条
六、生产调优 硬件选择
1、100万日活 * 没人每天产生日志100条 = 1亿条 (中型公司)
处理日志速度 1亿条 / (24 * 3600s ) = 1150条/s
1条日志 (0.5k - 2k 1k)
1150条 * 1k /s = 1m/s
高峰值 (中午小高峰 8 -12 ): 1m/s * 20倍 = 20m/s -40m/s
2、购买多少台服务器
服务器台数= 2 * (生产者峰值生产速率 * 副本数 / 100) + 1
= 2 * (20m/s * 2 /100) + 1
= 3 台
3、磁盘选择
kafka 按照顺序读写 机械硬盘和固态硬盘 顺序读写速度差不多
1亿条 * 1k = 100g
100g * 2个副本 * 3天 / 0.7 = 1t
建议三台服务器总的磁盘大小 大于1t
4、内存选择
kafka 内存 = 堆内存(kafka 内部配置) + 页缓存(服务器内存)
1)堆内存 10 -15g
2)页缓存 segment (1g ) (分区数Leader(10) * 1g * 25%)/ 3 = 1g
一台服务器 10g + 1g
5、CPU选择
32cpu
6、网络选择
测试:
1、batch.size=16384 linger.ms=0 9.76 MB/sec
2、batch.size=32768 linger.ms=0 9.76 MB/sec
3、batch.size=4096 linger.ms=0 3.81 MB/sec
4、batch.size=4096 linger.ms=50 3.83 MB/sec
5、batch.size=4096 linger.ms=50 compression.type=snappy 3.77 MB/sec
6、batch.size=4096 linger.ms=50 compression.type=zstd 5.68 MB/sec
7、batch.size=4096 linger.ms=50 compression.type=gzip 5.90 MB/sec
8、batch.size=4096 linger.ms=50 compression.type=lz4 3.72 MB/sec
9、batch.size=4096 linger.ms=50 buffer.memory=67108864 3.76 MB/sec
消费者 一次处理500条 81.2066m/s
消费者 一次处理2000条 138.0992m/s
消费者 一次处理2000条 fetch.max.bytes=104857600 145.2033m/s
第三章 生产者
3.4生产者分区
3.4.1.分区好处
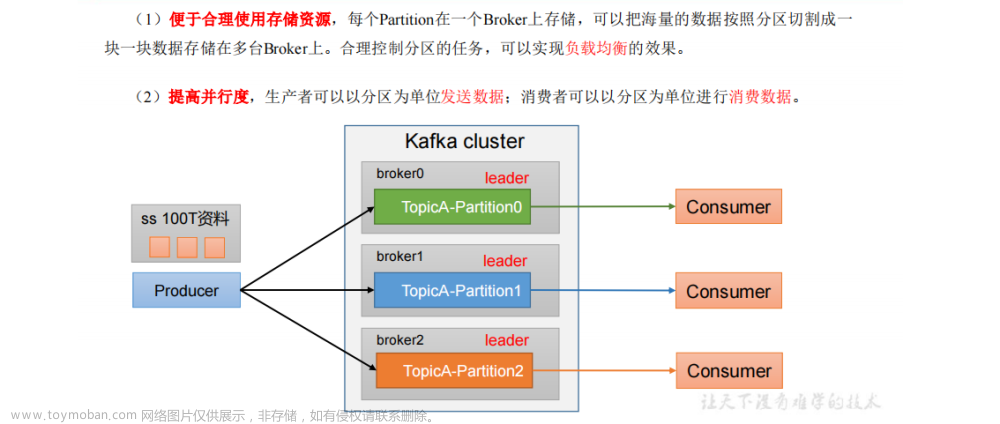
3.4.2 生产者发送消息的分区策略
3.4.3 自定义分区器
3.5 生产经验——生产者如何提高吞吐量
可以修改以下4个参数:
-
batch.size:批次大小,默认16k(也就是一个batch满了16kb就发送出去).如果 batch 太小,会导致频繁网络请求,吞吐量下降;
如果batch太大,会导致一条消息需要等待很久才能被发送出去,而且会让内存缓冲区有很大压力,过多数据缓冲在内存里.一般在实际生产环境,这个batch的值可以增大一些来提升吞吐量。 -
linger.ms:等待时间,默认值是0ms(意思就是消息立即被发送,不延迟,来一条发送一条),但是这是不对的。可以将其修改为5-100ms.假如linger.ms设置为为50ms,消息被发送出去后会进入一个batch,如果50ms内,这个batch满了16kb就会被发送出去。但是如果50ms时间到,batch没满,那么也必须把消息发送出去了,不能让消息的发送延迟时间太长,也避免给内存造成过大的一个压力。 -
compression.type:默认是none,不压缩,可以使用lz4,snappy等压缩,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的cpu开销。 -
RecordAccumulator(buffer.memory):设置发送消息的缓冲区,默认值是33554432(32MB).如果发送消息出去的速度小于写入消息进去的速度,就会导致缓冲区写满,此时生产消息就会阻塞住,所以说这里就应该多做一些压测,尽可能保证说这块缓冲区不会被写满导致生产行为被阻塞住.缓冲区大小,可以将其修改为64m.
3.6 生产经验——数据可靠性
1.ack 应答原理
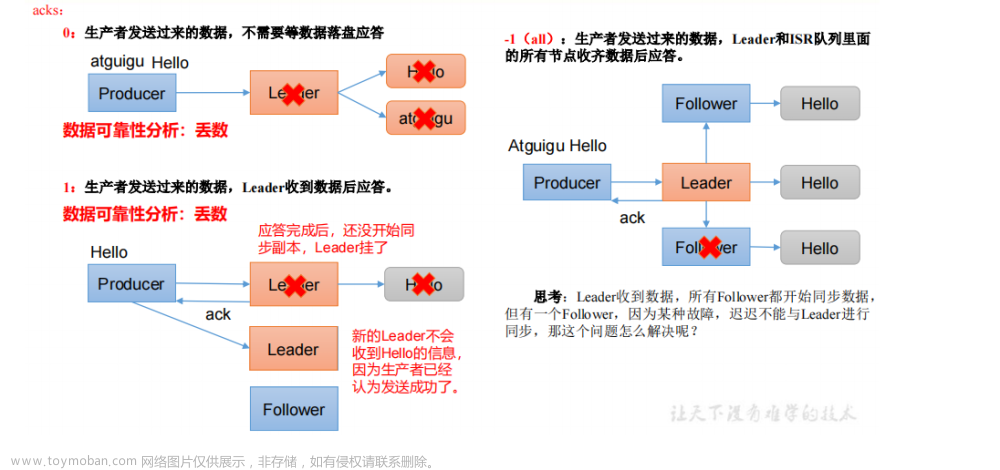
思考:Leader收到数据,所有Follower都开始同步数据,但有一个Follower,因为某种故障,迟迟不能与Leader进行同步,那这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set(ISR),意为和Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,(leader:0, isr:0,1)。这样就不用等长期联系不上或者已经故障的节点。
数据可靠性分析(以下2种情况和ack=1的效果是一样的,仍然有丢数的风险(leader:0,isr:0)):
分区副本设置为1个
ISR里应答的最小副本数量(min.insync.replicas,默认为1)设置为1.设置acks=all,且副本数为3,极端情况下,如果ISR中只有leader一个副本时,此时producer发送的数据只要leader同步成功就会返回响应.
因此:
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
可靠性总结:
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
3.7 生产经验——数据去重
3.7.1 数据传递语义
数据传递语义:
至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
最多一次(At Most Once)= ACK级别设置为0
总结:
- At Least Once可以保证数据不丢失,但是不能保证数据不重复;
- At Most Once可以保证数据不重复,但是不能保证数据不丢失。
- 精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
3.7.2 幂等性
1)幂等性原理
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once)=幂等性+至少一次( ack=-1+分区副本数>=2+ISR最小副本数量>=2)。
重复数据的判断标准:具有<PID, Partition,SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是Kafka每次重启都会分配一个新的;Partition表示分区号;Sequence Number是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。
2) 如何使用幂等性
开启参数 enable.idempotence 默认为 true,false 关闭。
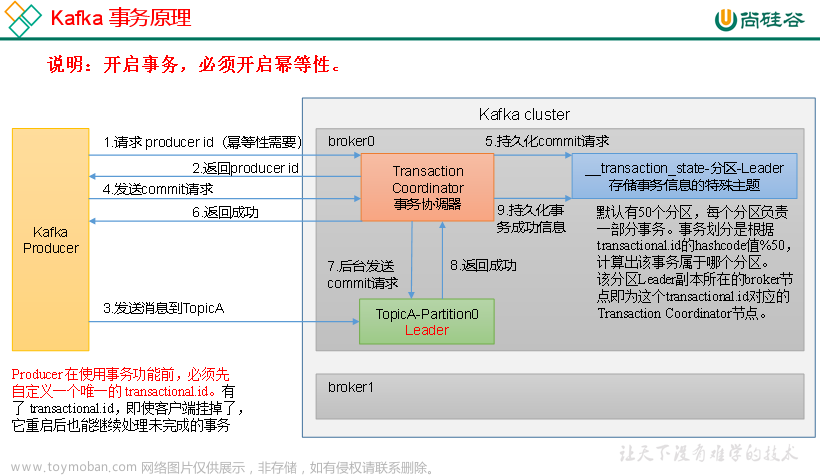
3.7.3生产者事务
1)Kafka 事务原理
生产经验——数据有序
生产经验——数据乱序
生产经验——分区的分配以及再平衡
Range 以及再平衡
RoundRobin 以及再平衡
Sticky 以及再平衡
Kafka总体
如何提升吞吐量
如何提升吞吐量?
- 提升生产吞吐量
(1)buffer.memory:发送消息的缓冲区大小,默认值是32m,可以增加到64m。
(2)batch.size:默认是16k。如果batch设置太小,会导致频繁网络请求,吞吐量下降;如果batch太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
(3)linger.ms,这个值默认是0,意思就是消息必须立即被发送。一般设置一个5-100毫秒。如果linger.ms设置的太小,会导致频繁网络请求,吞吐量下降;如果linger.ms太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
(4)compression.type:默认是none,不压缩,但是也可以使用lz4压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的CPU开销。 - 增加分区
- 消费者提高吞吐量
(1)调整fetch.max.bytes大小,默认是50m。
(2)调整max.poll.records大小,默认是500条。 - 增加下游消费者处理能力
数据精准一次
- 生产者角度
(1) acks设置为-1 (acks=-1)。
(2)幂等性(enable.idempotence = true) + 事务 。 - broker服务端角度
(1)分区副本大于等于2 (–replication-factor 2)。
(2) ISR里应答的最小副本数量大于等于2 (min.insync.replicas = 2)。 - 消费者
(1) 事务 + 手动提交offset (enable.auto.commit = false)。
(2) 消费者输出的目的地必须支持事务(MySQL、Kafka)。
最后
2023-9-7 18:06:13
我们都有光明的未来文章来源:https://www.toymoban.com/news/detail-861699.html
祝大家考研上岸
祝大家工作顺利
祝大家得偿所愿
祝大家如愿以偿
点赞收藏关注哦文章来源地址https://www.toymoban.com/news/detail-861699.html
到了这里,关于Kafka导航【Kafka】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!