前言
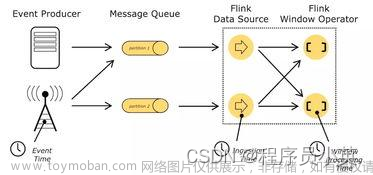
使用Flink处理数据时,可以基于Flink提供的批式处理(Batch Processing)和流式处理(Streaming Processing)API来实现,分别能够满足不同场景下应用数据的处理。这两种模式下,输入处理都被抽象为Source Operator,包含对应输入数据的处理逻辑;输出处理都被抽象为Sink Operator,包含了对应输出数据的处理逻辑。这里,我们只关注输出的Sink Operator实现。
Flink批式处理模式,运行Flink Batch Job时作用在有界的输入数据集上,所以Job运行的时间是有时限的,一旦Job运行完成,对应的整个数据处理应用就已经结束,比如,输入是一个数据文件,或者一个Hive SQL查询对应的结果集,等等。在批式处理模式下处理数据的输出时,主要需要实现一个自定义的OutputFormat,然后基于该OutputFormat来构建一个Sink,下面看下OutputFormat接口的定义,如下所示:

上面,configure()方法用来配置一个OutputFormat的一些输出参数;open()方法用来实现与外部存储系统建立连接;writeRecord()方法用来实现对Flink Batch Job处理后,将数据记录输出到外部存储系统。开发Batch Job时,通过调用DataSet的output()方法,参数值使用一个OutputFormat的具体实现即可。后面,我们会基于Elasticsearch来实现上面接口中的各个方法。

Flink流式处理模式,运行Flink Streaming Job时一般输入的数据集为流数据集,也就是说输入数据元素会持续不断地进入到Streaming Job的处理过程中,但你仍然可以使用一个HDFS数据文件作为Streaming Job的输入,即使这样,一个Flink Streaming Job启动运行后便会永远运行下去,除非有意外故障或有计划地操作使其终止。在流式处理模式下处理数据的输出时,我们需要是实现一个SinkFunction,它指定了如下将流数据处理后的结果,输出到指定的外部存储系统中,下面看下SinkFunction的接口定义,如下所示:

通过上面接口可以看到,需要实现一个invoke()方法,实现该方法来将一个输入的IN value输出到外部存储系统中。一般情况下,对一些主流的外部存储系统,Flink实现了一下内置(社区贡献)的SinkFunction,我们只需要配置一下就可以直接使用。而且,对于Streaming Job来说,实现的SinkFunction比较丰富一些,可以减少自己开发的工作量。开发Streaming Job时,通过调用DataStream的addSink()方法,参数是一个SinkFlink的具体实现。下面,我们分别基于批式处理模式和批式处理模式,分别使用或实现对应组件将Streaming Job和Batch Job的处理结果输出到Elasticsearch中:
基于Flink DataSteam API实现
在开发基于Flink的应用程序过程中,发现Flink Streaming API对Elasticsearch的支持还是比较好的,比如,如果想要从Kafka消费事件记录,经过处理最终将数据记录索引到Elasticsearch 5.x,可以直接在Maven的POM文件中添加如下依赖即可:

我们使用Flink Streaming API来实现将流式数据处理后,写入到Elasticsearch中。其中,输入数据源是Kafka中的某个Topic;输出处理结果到lasticsearch中,我们使用使用Transport API的方式来连接Elasticsearch,需要指定Transport地址和端口。具体实现,对应的Scala代码,如下所示:


上面有关数据索引到Elasticsearch的处理中, 最核心的就是创建一个ElasticsearchSink,然后通过DataStream的API调用addSink()添加一个Sink,实际是一个SinkFunction的实现,可以参考Flink对应DataStream类的addSink()方法代码,如下所示:
def addSink(sinkFunction: SinkFunction[T]): DataStreamSink[T] =
stream.addSink(sinkFunction)基于Flink DataSet API实现
目前,Flink还没有在Batch处理模式下实现对应Elasticsearch对应的Connector,需要自己根据需要实现,所以我们基于Flink已经存在的Streaming处理模式下已经实现的Elasticsearch Connector对应的代码,经过部分修改,可以直接拿来在Batch处理模式下,将数据记录批量索引到Elasticsearch中。我们基于Flink 1.6.1版本,以及Elasticsearch 6.3.2版本,并且使用Elasticsearch推荐的High Level REST API来实现(为了复用Flink 1.6.1中对应的Streaming处理模式下的Elasticsearch 6 Connector实现代码,我们选择使用该REST Client),需要在Maven的POM文件中添加如下依赖:

我们实现的各个类的类图及其关系,如下图所示:

如果熟悉Flink Streaming处理模式下Elasticsearch对应的Connector实现,可以看到上面的很多类都在
org.apache.flink.streaming.connectors.elasticsearch包里面存在,其中包括批量向Elasticsearch中索引数据(内部实现了使用BulkProcessor)。上图中引入的ElasticsearchApiCallBridge,目的是能够实现对Elasticsearch不同版本的支持,只需要根据Elasticsearch不同版本中不同Client实现,进行一些适配,上层抽象保持不变。
如果需要在Batch处理模式下批量索引数据到Elasticsearch,可以直接使用ElasticsearchOutputFormat即可实现。但是创建ElasticsearchOutputFormat,需要几个参数:
private ElasticsearchOutputFormat(
Map<String, String> bulkRequestsConfig,
List<HttpHost> httpHosts,
ElasticsearchSinkFunction<T> elasticsearchSinkFunction,
DocWriteRequestFailureHandler failureHandler,
RestClientFactory restClientFactory) {
super(new Elasticsearch6ApiCallBridge(httpHosts, restClientFactory),
bulkRequestsConfig, elasticsearchSinkFunction, failureHandler);
}当然,我们可以通过代码中提供的Builder来非常方便的创建一个ElasticsearchOutputFormat。下面,我们看下我们Flink Batch Job实现逻辑。
- 实现ElasticsearchSinkFunction
我们需要实现ElasticsearchSinkFunction接口,实现一个能够索引数据到Elasticsearch中的功能,代码如下所示:
final ElasticsearchSinkFunction<String> elasticsearchSinkFunction = new ElasticsearchSinkFunction<String>() {
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer)
{
indexer.add(createIndexRequest(element, parameterTool));
}
private IndexRequest createIndexRequest(String element, ParameterTool parameterTool) {
LOG.info("Create index req: " + element);
JSONObject o = JSONObject.parseObject(element);
return Requests.indexRequest()
.index(parameterTool.getRequired("es-index"))
.type(parameterTool.getRequired("es-type"))
.source(o);
}
};上面代码,主要是把一个将要输出的数据记录,通过RequestIndexer来实现索引到Elasticsearch中。
- 读取Elasticsearch配置参数
配置连接Elasticsearch的参数。从程序输入的ParameterTool中读取Elasticsearch相关的配置:

- 创建ElasticsearchOutputFormat
创建一个我们实现的ElasticsearchOutputFormat,代码片段如下所示:

上面很多配置项指定了向Elasticsearch中进行批量写入的行为,在ElasticsearchOutputFormat内部会进行设置并创建
Elasticsearch6BulkProcessorIndexer,优化索引数据处理的性能。
- 实现Batch Job主控制流程
最后我们就可以构建我们的Flink Batch应用程序了,代码如下所示:

我们输入的HDFS文件中,是一些已经加工好的JSON格式记录行,这里为了简单,直接将原始JSON字符串索引到Elasticsearch中,而没有进行更多其他的处理操作。文章来源:https://www.toymoban.com/news/detail-861700.html
 文章来源地址https://www.toymoban.com/news/detail-861700.html
文章来源地址https://www.toymoban.com/news/detail-861700.html
到了这里,关于10年大数据专家,使用Flink实现索引数据到Elasticsearch,快来学的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!