前言
🏷️🏷️本章开始学习有关决策树的相关知识,决策树是一种树形模型,也是一种常用的分类和回归方法。本章我们首先介绍第一种决策树的构造原理
学习目标
- 了解决策树算法的基本思想
- 掌握 ID3 决策树的构建原理
1.决策树介绍
1.1案例引入
有的同学可能在大学学习过一门课程叫《数据结构》,里面有一个重要的结构就是“树”,和现实生活中的树一样,树的主要由四部分树根、树干、树枝、树叶组成,今天的决策树也是一种树结构,大家学习的时候可以想象现实生活中的树来来理解。
决策树算法是一种监督学习算法,英文是Decision tree。
决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的then就是一种选择或决策。程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
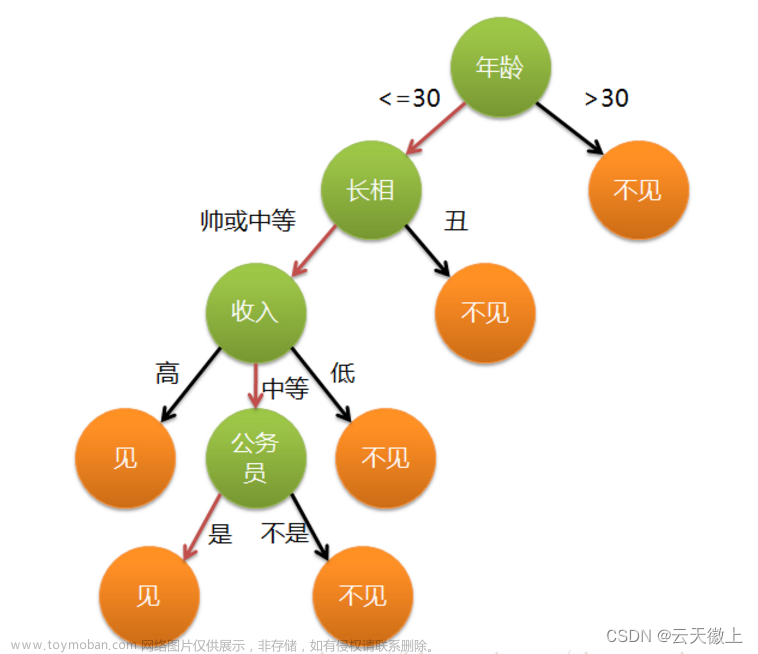
比如:你母亲要给你介绍男朋友,是这么来对话的:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
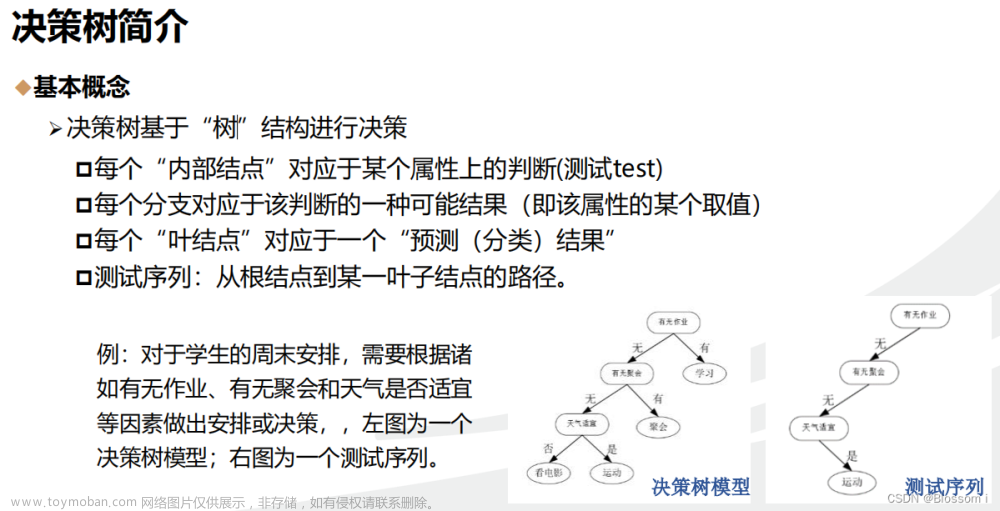
于是你在脑袋里面就有了下面这张图
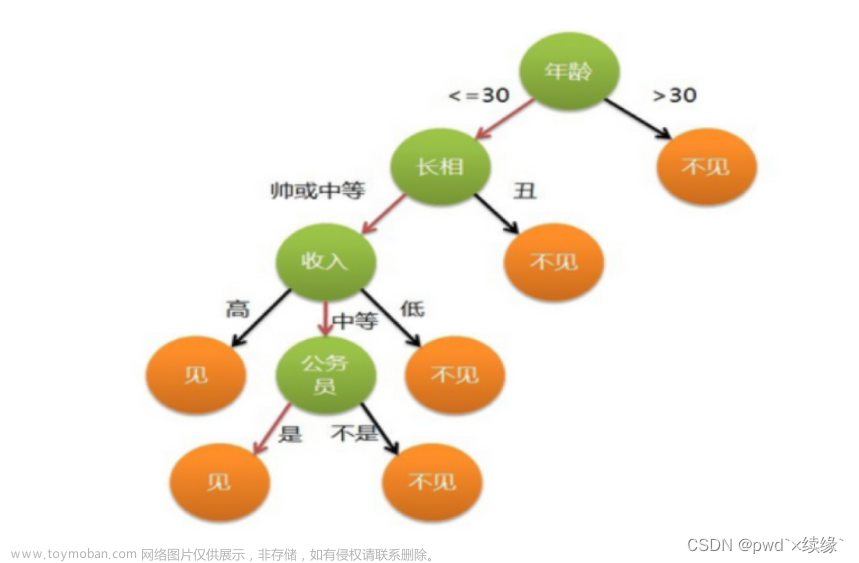
作为女孩的你在决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。
1.2构建决策树的三个步骤
- 特征选择:选取有较强分类能力的特征(定性分析问题还是定量分析问题等等)
- 决策树生成
- 决策树剪枝(让决策树更加简洁高效,对于一些特征不重要,或根据权值大小,对决策树的分类进行筛选)
决策树API:
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.tree import plot_tree
2.ID3决策树
- 掌握信息熵的概念
- 掌握条件熵的概念
- 掌握ID3决策树构建过程
2.1信息熵
ID3 树是基于信息增益构建的决策树.
定义
- 熵在信息论中代表随机变量不确定度的度量
- 熵越大,数据的不确定性度越高
- 熵越小,数据的不确定性越低
公式:
公式的转换,当数据类别只有两类的情况下,公式可以做如下转换:

代码角度理解信息熵的概念
import numpy as np
import matplotlib.pyplot as plt
def entropy(p):
return -p*np.log(p)-(1-p)*np.log(1-p)
x = np.linspace(0.01,0.99,200)
plt.plot(x,entropy(x))
plt.show()
✒️观察上图可以得出,当我们的系统每一个类别是等概率的时候,系统的信息熵最高,当系统偏向于某一列,相当于系统有了一定程度的确定性,直到系统整体百分之百的都到某一类中,此时信息熵就达到了最低值,即为0。上述结论也可以拓展到多类别的情况。
2.2 信息增益
💡💡上文我们也讲到,决策树构建第一步即特征选择是尤为重要的,每一种特征的重要性怎样体现呢,那就是信息增益。
2.2.1定义
特征对训练数据集D的信息增益,定义为集合的经验熵与特征A给定条件下D的经验熵之差。即
根据信息增益选择特征方法是:对训练数据集D,计算其每个特征的信息增益,并比较它们的大小,并选择信息增益最大的特征进行划分。表示由于特征$A$而使得对数据D的分类不确定性减少的程度。
2.2.2算法
设训练数据集为D,表示其样本个数。设有个类,,为属于类的样本个数,。设特征A有个不同取值,根据特征A的取值将D划分为个子集,为样本个数,。子集中属于类的样本集合为,即,为的样本个数。信息增益算法如下:
-
输入:训练数据集D和特征A;
-
输出:特征A对训练数据集D的信息增益
(1) 计算数据集D的经验熵
(2) 计算特征A对数据集D的经验条件熵
(3) 计算信息增益
💡💡只看公式可能觉得很复杂,下面我们带入一个例子来更好的理解
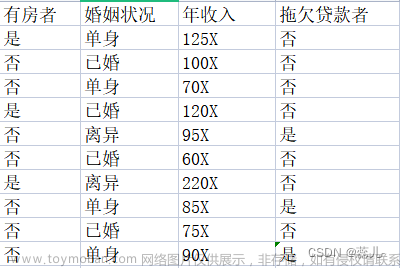
下面以常用的贷款申请样本数据表为样本集,通过数学计算来介绍信息增益计算过程。
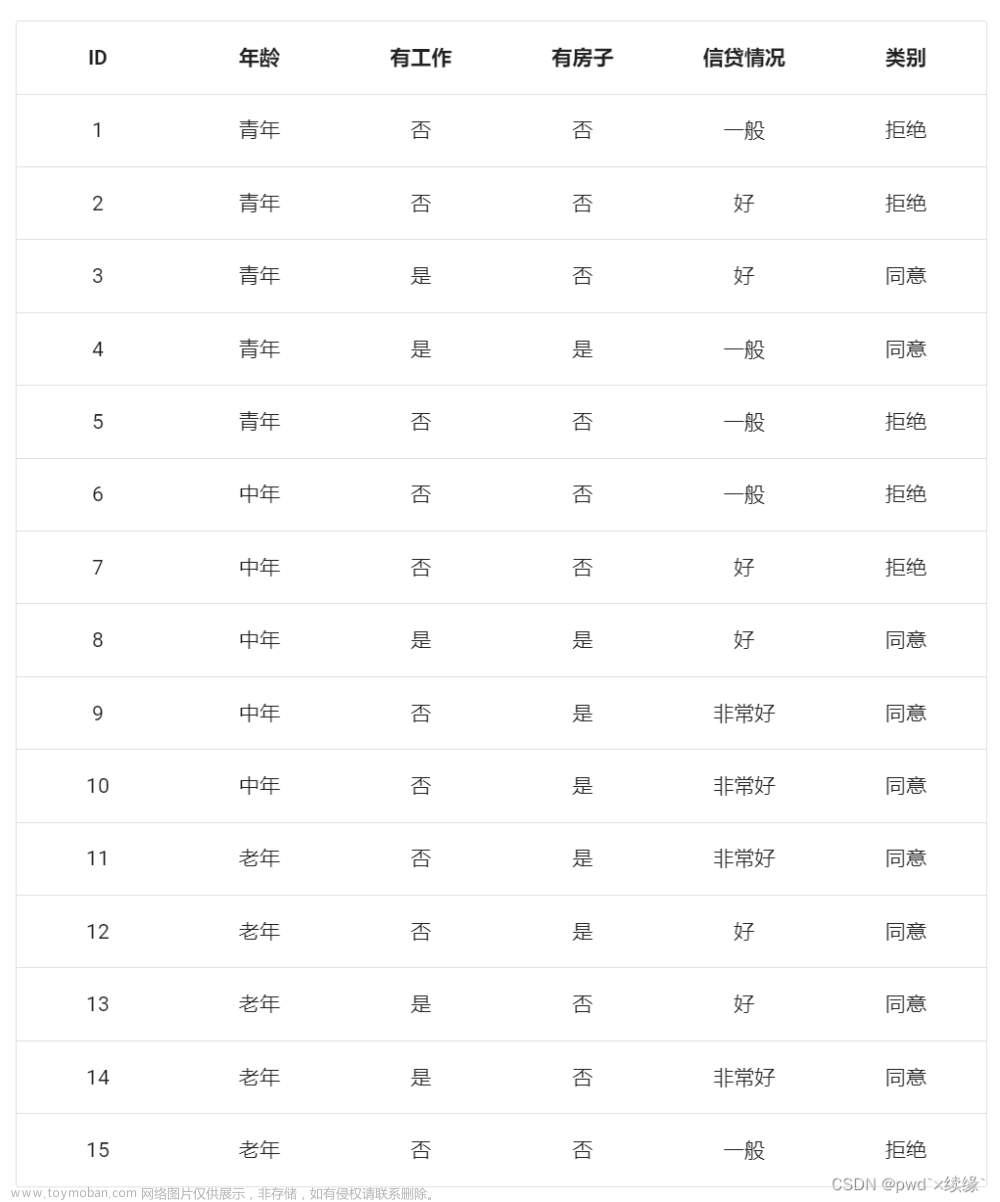
Step1 计算经验熵
类别一共是两个拒绝/同意,数量分别是6和9,根据熵定义可得:
Step2 各特征的条件熵
将各特征分别记为 ,分别代表年龄、有无工作、有无房子和信贷情况,那么

Step3 计算增益

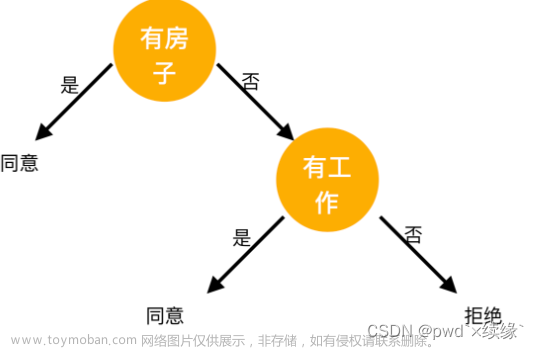
根据计算所得的信息增益,选取最大的 作为根节点的特征。它将训练集 划分为两个子集(取值为“是”)和(取值为“否”)。由于只有同一类的样本点,所以成为一个叶节点,节点标记为“是”。
对于需从特征中选择新的特征。计算各个特征的信息增益
选择信息增益最大的特征作为节点的特征。由于有两个可能取值,一个是“是”的子节点,有三个样本,且为同一类,所以是一个叶节点,类标记为“是”;另一个是“否”的子节点,包含6个样本,也属同一类,所以也是一个叶节点,类别标记为“否”。
最终构建的决策树如下:
3.ID3的算法步骤
-
计算每个特征的信息增益
-
使用信息增益最大的特征将数据集 S 拆分为子集
-
使用该特征(信息增益最大的特征)作为决策树的一个节点
-
使用剩余特征对子集重复上述(1,2,3)过程
4.小结
-
信息熵是一个变量(特征)包含信息多少的度量方式。信息熵的值大,则认为该变量包含的信息量就大
-
条件熵用于衡量以某个特征作为条件,对目标值纯度的提升程度
-
信息增益用于衡量那个特征更加适合优先分裂文章来源:https://www.toymoban.com/news/detail-861817.html
-
使用信息增益构建的决策树成为 ID3 决策树文章来源地址https://www.toymoban.com/news/detail-861817.html
到了这里,关于ID决策树的构造原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!