秩和比综合评价法(rsr
-
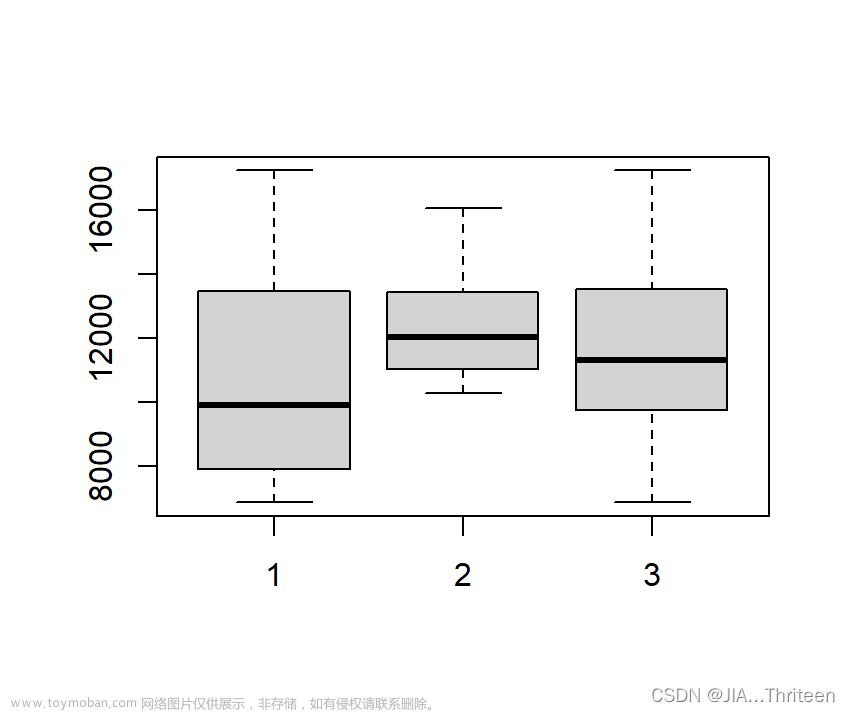
非参数统计:两样本和多样本的Brown-Mood中位数检验;Wilcoxon(Mann-Whitney)秩和检验及有关置信区间;Kruskal-Wallis秩和检验
目录 两样本和多样本的Brown-Mood中位数检验 例3.1我国两个地区一些(分别为17个和15个)城镇职工的工资(元): Wilcoxon(Mann-Whitney)秩和检验及有关置信区间 例3.1我国两个地区一些(分别为17个和15个)城镇职工的工资(元): Kruskal-Wallis秩和检验 例4.1在一项健康实验中,三人组
-
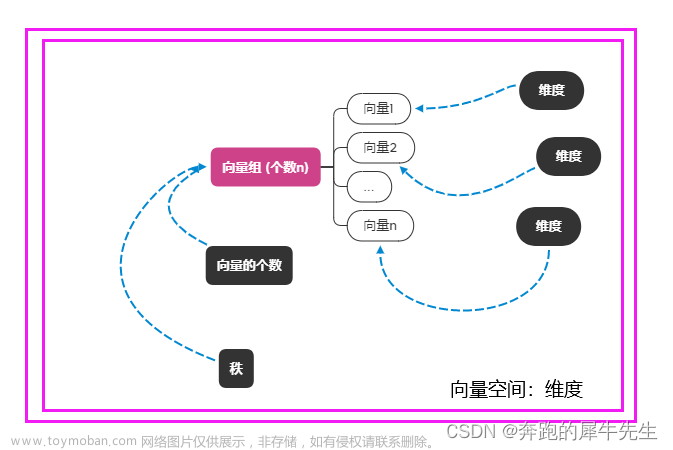
线性代数的学习和整理18:矩阵的秩的各种定理, 秩和维度(未完成)
目录 0 问题引出:什么是秩? 概念备注: 1 先厘清:什么是维数? 1.1 真实世界的维度数 1.2 向量空间的维数 1.2.1 向量空间,就是一组最大线性无关的向量组/基张成的空间 1.3 向量α的维数 1.3.1 向量的维数=分量(数字/标量)个数 1.4 向量组/矩阵 A 的维数 1.4.1 什么是向量组的维
-

简述矩阵的秩和向量组的秩的定义 从定义出发分析两者之间的相互关系
(1)简述矩阵的秩和向量组的秩的定义;(2)从定义出发分析两者之间的相互关系。 (1)简述矩阵的秩和向量组的秩的定义: 矩阵的秩的定义:设在矩阵A中有一个不为0的r阶子式D,且所有的r+1阶子式(若存在)全为0,则D称为矩阵A的最高阶非零子式,它的阶数r称为矩阵
-

6.利用matlab完成 符号矩阵的秩和 符号方阵的逆矩阵和行列式 (matlab程序)
1. 简述 利用 M 文件建立矩阵 对于比较大且比较复杂的矩阵,可以为它专门建立一个 M 文件。下面通过一个简单例子来说明如何利用 M 文件创建矩阵。 例 2-2 利用 M 文件建立 MYMAT 矩阵。 (1) 启动有关编辑程序或 MATLAB 文本编辑器,并输入待建矩阵: (
-
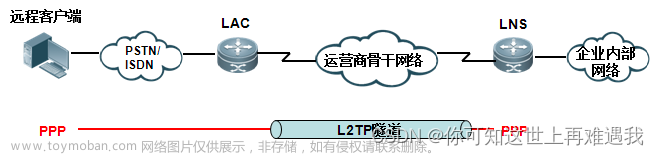
锐捷RSR系列路由器——VPN功能——L2TP_VPDN1.0——L2TP 服务器典型配置
目录 01 L2TP 强制隧道模式——用户本地认证 02 L2TP 强制隧道模式——AAA本地认证 03 VPDN 1.0域剥离认证——本地认证 04 VPDN 1.0域剥离认证——AAA认证 功能介绍 L2TP强制隧道模式: 在强制隧道模式下,LAC端终结来自远程接入客户的呼叫,然后通过中间网络以隧道方式将PPP会
-

19种工程问题,智能优化算法常用指标一键导出为EXCEL,最优值,平均值,标准差,最差值,中位数,秩和检验,箱线图...
常见的智能算法对比方法除了使用经典的CEC函数外, 工程优化问题 也是比较常用的方法。 本期实现在19种工程优化问题上对智能算法的指标进行一键统计! 使你的论文更具说服力! 19种工程优化问题包含如下: 关于上述工程问题的相关介绍,网络上有很多,这里就不再详细
-
MATLAB中对方阵行列式的求解、矩阵的累加和与累乘积进行求解、矩阵的排序、矩阵的秩和迹、以及矩阵的特征值和特征向量的求解
目录 1、方阵的行列式计算 2、累加和与累乘积 (1)累加和 (2)累乘积 3、对于数据进行排序 4、求矩阵的秩 5、矩阵的迹 6、计算矩阵的特征值和特征向量 在线性代数中,对于一个方阵进行求值运算需要先将其转换为行列式,MATLAB中提供过了det函数用于对于方阵的行列式进
-

机器学习回归任务指标评价及Sklearn神经网络模型评价实践
机器学习回归模型评价是指对回归模型的性能进行评估,以便选择最佳的回归模型。其中,MAE、MSE、RMSE 用于衡量模型预测值与真实值之间的误差大小,R² 用于衡量模型对数据的拟合程度。在实际应用中,我们可以使用这些指标来评估回归模型的性能,并对模型进行优化。
-
数据治理:数据质量评价体系
数据质量人人有责,这不仅仅只是一句口号,更是数据工作者的生命线。数据质量的好坏直接决定着数据价值高低。 数据质量管理是指在数据创建、加工、使用和迁移等过程中,通过开展数据质量定义、过程控制、监测、问题分析和整改、评估与考核等一系列管理活动,提高
-
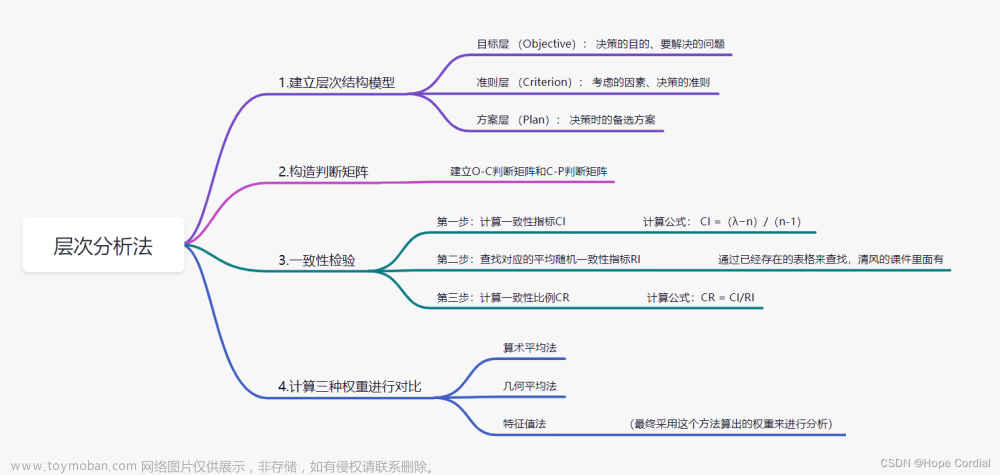
数学建模 —— 评价模型
对于评价类模型,最好还是使用 Topsis法,主成分分析主观因素太大,灰色关联分析因为这个灰色理论近几年才在国内出现,使用范围较小,可能评委老师了解不多。模糊综合评价的话也可以使用,但是能用 Topsis法最好还用 Topsis法。 评价类模型主要研究的是多个指标中各个指
-
评价指标BLUE了解
BLEU (Bilingual Evaluation Understudy,双语评估基准)是一组度量机器翻译和自然语言生成模型性能的评估指标。BLEU指标是由IBM公司提出的一种模型评估方法,以便在机器翻译领域中开发更好的翻译模型。BLEU指标根据生成的句子与人工参考句子之间的词、短语和n-gram匹配来计算模型的
-

Codewhisperer 使用评价
最近亚⻢逊推出了一款基于机器学习的 AI 编程助手 Amazon CodeWhisperer,可以实时提供代码建议。在编写代码时,它会自动根据现有的代码和注释给出建议。 Amazon CodeWhisperer 与GitHub Copilot类似,主要的功能有: 代码补全 注释和文档补全 代码安全问题的辅助定位 亚马逊云科技开发
-

uniapp 小程序 查看评价
查看评价效果图: 评分组件在上一篇文章!!!!!!!
-

分类任务评价指标
分类任务中,有以下几个常用指标: 混淆矩阵 准确率(Accuracy) 精确率(查准率,Precision) 召回率(查全率,Recall) F-score PR曲线 ROC曲线 真实1 真实0 预测1 TP FP 预测0 FN TN 从 预测 的角度看: TP: True Positive。预测为1,实际为1,预测正确。 FP: False Positive。预测为1,实际为
-
模型评价指标—F1值
最近空余时间在参加数字中国创新大赛,比赛规则是根据模型的F1值对参赛者进行排名。为了更深刻地理解这个指标,我最近对它做了一些梳理,现在把它分享给更多有需要的人图片。最近在参赛时也发现了一个问题,就是算法在训练集上完全拟合(KS=1),但是到测试集上衰退
-

代码质量评价及设计原则
可维护性强的代码指的是: 在不去破坏原有的代码设计以及不引入新的BUG的前提下,能够快速的修改或者新增代码. 不易维护的代码指的是: 在添加或者修改一些功能逻辑的时候,存在极大的引入新的BUG的风险,并且需要花费的时间也很长. 代码可维护性的评判标准比较模糊, 因为
-

目标检测评价指标
IoU(交并比) 1、IOU的全称为交并比(Intersection over Union), 是目标检测中使用的一个概念,IoU计算的是“预测的边框”和“真实的边框”的交叠率,即它们的交集和并集的比值 。 2、IoU等于“预测的边框”和“真实的边框”之间交集和并集的比值。 IoU计算如下图,B1为真实
-
如何评价论文的创新
摘要 : 创新性是论文的核心. 本贴描述论文创新的几种评价视角, 并举例说明. 这是最常见的视角. 在某些领域, 能想到的方法几乎都想到了, 所以人们写论文的时候, 会写成如下形式: 例 1 . GoogleNet在基于示功图故障诊断中的应用——以大庆油田为例. 这里的方法是GoogleNet, 问题是
-

如何评价模型的好坏?
回归: MSE(均方误差)—— 判定方法:值越小越好(真实值-预测值,平方之后求和平均) RMSE(均根方误差)—— 判定方法:值越小越好(MSE开根号) R squared/拟合优度 —— 判定方法:值越接近1模型表现越好 分类: ROC —— 判定方法:ROC曲线应尽量偏离参考线(越远
-

【分类】分类性能评价
属于各类的样本的并不是均一分布,甚至其出现概率相差很多个数量级,这种分类问题称为不平衡类问题。在不平衡类问题中,准确率并没有多大意义,我们需要一些别的指标。 通常在不平衡类问题中,我们使用F-度量来作为评价模型的指标。以 二元不平衡分类问题