越界by几京
-
Kotlin委托Delegate托管by
property=\\\'user\\\' setValue - fly property=\\\'user\\\' getValue fly 0 - 2023 2023 - 2024 Delegates.observable追踪观察可变数据更新,Kotlin_zhangphil的博客-CSDN博客 **Java观察者模式的场景:一个女孩洗澡,被很多男孩偷看。女孩洞察后,搜索坏男孩,然后继续洗澡。*//*男孩Boy.java*/import java.util.Observable;不定长
-

web组态(BY组态)接入流程
数据流向 嵌入原理 后台websocket向客户端监控画面推送数据时,格式为json格式,json中的键为 绑定设备时的设备编号。 注意 :json中的键不能以数字开头,否则无法解析为正确的json对象。 用于支持组态的场景画面数据,及模板数据,上传图片数据的存储,这些表的字段我们只
-

ES: update by query
es 版本为7.9.3 1、修改一个字段的值 给es里某个字段增加一个子类型,要求之前的数据也能被查询到 修改mapping,添加一个子字段 插入一条新的数据 查询 李四,王五,发现查不到李四 因为李四是 更改mapping之前插入,新增字段没有在老数据上生效,导致查询不出 为了之前的数
-
MySQL Group by 优化查询
使用的是临时表,加文件排序(数据量小用内存排序) 注意:这里加的索引一般不会仅仅是group by后面的字段索引(大多数多少条件是一个以 该字段开头联合索引 ,方便使用覆盖索引或者索引下推)。如果该字段是一个varchar类型, 最好 加个int冗余字段,建立索引的字段,
-

Mysql group by使用示例
总数据: 索引情况:
-
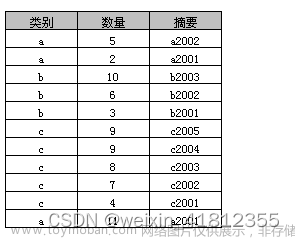
sql中group by 的使用
1、概述 Group By 从字面意义上理解就是根据By指定的规则对数据进行分组,所谓的分组就是将一个数据集划分为若干个小区域,然后针对若干个小区域进行数据处理 2、原始表 3、简单的Group By 示例1 select 类别,数量 as 数量之和 from A group by 类别 返回结果如下表,实际上就是
-
探究下Clickhouse中的order by
在 ClickHouse 中,排序操作通常需要进行数据重新排列,以使得符合排序条件的数据可以连续存储。这个过程可能需要消耗较大的时间和空间。因此,如果数据量较大,排序操作的性能会受到较大的影响。 在第一种情况中,按照唯一的 id 进行排序,可能需要将所有数据都加载
-
【sqlsever】具体案例理解PARTITION BY
当使用 PARTITION BY 时,它通常是与窗口函数一同使用的。下面将提供一个简单的例子,使用一个包含以下列的表: 现在,我们想要计算每个 column1 的每一行的 column3 列的累积总和。我们可以使用 PARTITION BY 来实现这个目标: 这将生成以下结果: 在这个例子中, PARTITION BY col
-
MySQL 中 Group By 的用法
Group By 是一种 SQL 查询语句,常用于根据一个或多个列对查询结果进行分组。在 Group By 子句中指定的列将成为分组依据,而在 Select 子句中指定的列必须是聚合函数(例如 SUM、AVG、COUNT 等)或分组列。 Group By 的语法如下: SELECT column_name(s) FROM table_name WHERE condition GROUP BY co
-
group by进行分组时查询数据
group by进行分组时查询数据需要注意: select后的字段: 要么就要包含在Group By语句的后面,作为分组的依据; 要么就要被包含在聚合函数中。 错误: SELECT name, salary FROM student GROUP BY name select 后的字段 salary 不在 group by 后面,所以salary无法显示全部值。 正确
-

MySQL——GROUP BY详解与优化
在 MySQL 中,GROUP BY用于将具有指定列中相同值的行分组在一起。这是在处理大量数据时非常有用的功能,允许对数据进行分类和聚合。 以下是GROUP BY子句的基本语法: \\\"\\\"\\\" \\\"\\\"\\\" 其中,col1, col2, ...是要分组的列名,aggregate_function是用于聚合数据的函数,如SUM, AVG, MAX, MIN等。table_
-
hive order by length() 报错
hql 如下 select length(tag) from table1 order by length(tag) limit 20; 报错FAILED: SemanticException [Error 10004]: Line…Invalid table alias or column reference ‘tag’: (possible column names are: _c0) FAILED: SemanticException [Error 10004]: Line…Invalid table alias or column reference ‘tag’: (possible column names are: _c0) 修改 用别名替
-

ES多个字段group by操作
以下操作基于es6.8 这种方式查询出来的数据不是扁平化的,而是一层套一层的,比如字段一套字段二。 结果,one下面的buckets里面是two,每个two下面有自己的bukets,就是two的值和count。 封装一个通用的聚合查询并映射到java类中 这种方式查出来的数据更扁平化,容易被接受
-
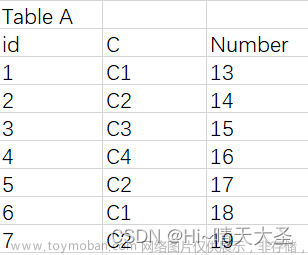
GROUP BY和HAVING用法介绍
一、group by用法 “group by”就是对数据进行分组,然后针对分组后的数据进行处理。 如: 返回结果实际上就是根据C进行分类汇总。 二、group by 和 having 1、having必须和group by一起用,且在group by后面,但是group可以单独用来分组 2、group by、having、order by的使用顺序:group by 、
-
Code generated by OCR 01
* OCR 01: Code generated by OCR 01 * OCR 01: * OCR 01: Prepare text model * OCR 01: create_text_model_reader (\\\'manual\\\', [], TextModel) set_text_model_param (TextModel, \\\'is_dotprint\\\', \\\'true\\\') set_text_model_param (TextModel, \\\'char_width\\\', 41) set_text_model_param (TextModel, \\\'char_height\\\', 140) set_text_model_param (TextModel, \\\'stroke_width\\\', 9.9) set_tex
-

SQL优化(3):order by优化
MySQL的排序,有两种方式: Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。 Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using
-
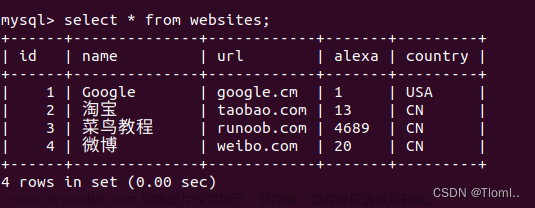
SQL ORDER BY 关键字
ORDER BY 用于对结果集进行排序。 ORDER BY 用于对结果集按照一个列或者多个列进行排序。 ORDER BY 默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 。 ORDER BY 子句后面的列名指示按哪些列进行排序。如果您指定多个列
-

mysql8之前如何实现row_number() over(partition by xxx order by xxx asc/desc)
最近笔者在进行对广告业务的数据统计时遇到这种情况,业务方嫌弃离线数仓太慢,又无需太高的实时性本该使用即席查询的OLAP去做,但是当前公司调研的OLAP还没有推到广告业务侧,无奈只得使用mysql暂时顶一下。我们当前使用的是mysql5.7。 一充用户 :当日只有一次充值的
-
[SQL挖掘机] - GROUP BY语句
group by 是 sql 中用于对结果集进行分组的。通过使用 group by,可以根据一个或多个列的值将结果集中的行分组,并对每个分组应用某种聚合函数(如 count、sum、avg 等)以生成汇总信息。这样可以方便地对数据进行分类、统计和分析。 group by 语句通常与 select 语句结合使
-

MySQL查询分组Group By原理分析
日常开发中,我们经常会使用到group by: 你是否知道group by的工作原理呢? group by和having有什么区别呢? group by的优化思路是怎样的呢? 使用group by有哪些需要注意的问题呢? 使用group by的简单例子 group by 工作原理 group by + where 和 having的区别 group by 优化思路 group by 使用注意