eeprom怎么读取数据
-
Unity 数据读取|(二)多种方式读取文本文件
在Unity3D中,我们经常会需要在本地或者服务器上读取游戏数据,Unity中读取文件的方式有很多种,写下此文章以做总结。 TextAsset是Unity 提供的一个文本对象,它可以通过 Resources.Load 或者 AssetBundle 来读取数据。 它支持读取的文本格式包括 . txt .html .htm .bytes .json .csv .yaml .fnt 。
-

IC设计-存储器分类汇总(区别RAM、ROM、SRAM、 DDR、EEPROM、FLASH)
1、存储器分类图 2、用分类对比的方法介绍不同的存储器特点 2.1 存储器按照用途分类 : 可以分为 主存储器(内部存储)和辅助存储器(外部存储) 。主存储器是指CPU能直接访问的,有内存、一级/二级缓存等,一般采用半导体存储器;辅助存储器包括软盘、硬盘
-
MicroBlaze系列教程(6):AXI_IIC的使用(24C04 EEPROM)
本文是Xilinx MicroBlaze系列教程的第6篇文章。 AXI_IIC简介 一般情况下,使用FPGA实现I2C协议主要有两种方式:一种是基于Verilog实现起始位、停止位、ACK产生和判断、数据的发送和接收,通常SDA设计成双向端口,配合I2C模型对设计的模块进行仿真验证。还有一种是基于软核处理器
-

Modbus Poll读取plc数据(TCP/IP读取),并查看指定地址指定数据
1.首先连接,点击Connection-connect,选择Modbus TCP/IP,输入IP和端口号(Server Port) 2.连接后,Tx=0下没有红色错误提示则表示连接成功,右键数据界面选择Read/write Definition 3. Address:表示开始读取的地址数,比如plc地址为D801,那么在此文本框内输入800,就可以从 800开始显示数据
-
EEPROM,NOR Flash,NAND Flash,eMMC,UFS,SSD分别和主要参数及特性
EEPROM、NOR Flash、NAND Flash、eMMC、UFS、SSD都是非易失性存储器,但它们在架构、存储容量、读写速度、功耗、价格等方面存在不同,具体如下: EEPROM:EEPROM(Electrically Erasable Programmable Read-Only Memory)是一种用于存储非易失性数据的闪存存储器。它比 NOR Flash和 NAND Flash容量小、价
-
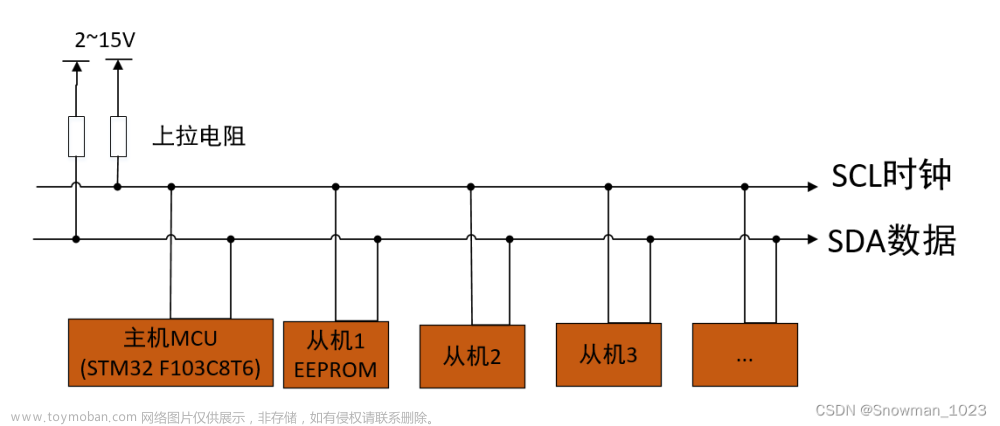
第五章 stm32 cubemx 软件I2C实验以及EEPROM的使用理论及实验过程
本章将讲解stm32通讯协议中的IIC协议,利用cubeMX完成软件和硬件IIC的实现,并结合实验数据,给人更为深刻的体验。 我们结合IIC的具体协议和逻辑分析仪得到的具体实验数据理解IIC协议。 I2C通讯协议是由Phiilps公司开发的,由于它引脚少,硬件实现简单,可扩展性强,不需要
-

Python:实现文件读取与输入,数据存储与读取的常用命令
文本文件可用于存储大量的数据,里面的数据对于用户而言十分重要,因此,本文就如何利用Python实现文本内容的读取与输入,数据存储与读取进行介绍。 一、读取文件中的数据: 首先需要找到所需文件的路径:例如我在桌面创建了一个文本文件,它的路径为 利用函数 op
-

使用STM32CubeProgrammer工具读取单片机Flash数据读取
本文主要介绍,如何使用STM32CubeProgrammer工具读取和写入单片机Flash内部的数据,方便调试使用。 2.1 连接Stlink和单片机,点击“connect”进行连接 2.2 读取固定长度的数据 根据程序的大小,设置需要读取的字节数,如下图所示。点击“read”将单片机Flash中的数据读取到STM32Cube
-

大数据的金融数据读取及分析(一)
由于考虑商业数据问题,我们用开源数据做演示 一.tushare开源数据 Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,在数据获取方面极大地
-

大数据的金融数据读取及分析(二)
一、注册和获取token 参考大数据的金融数据读取及分析(一)大数据的金融数据读取及分析(-)_石工记的博客-CSDN博客 二、获取股市信息 需注意的是,利用tushare接口获取部分信息时对积分有不同的要求,积分不足会造成访问权限受限的情况 ps:高校学生可联系站方申请访问
-

EEPROM芯片(24c02)使用详解(I2C通信时序分析、操作源码分析、原理图分析)
(1)本文主要是通过24c02芯片来讲解I2C接口的EEPROM操作方法,包含底层时序和读写的代码; (2)大部分代码是EEPROM芯片通用的,但是其中关于某些时间的要求,是和具体芯片相关的,和主控芯片和外设芯片都有关系,需要具体分析,但是逻辑顺序是不变的; (1)在嵌入式开发中,
-
spark读取数据写入hive数据表
目录 spark 读取数据 spark从某hive表选取数据写入另一个表的一个模板 概述: create_tabel建表函数,定义日期分区 删除原有分区drop_partition函数 generate_data 数据处理函数,将相关数据写入定义的表中 注: 关于 insert overwrite/into 中partition时容易出的分区报错问题: 添加分区函数
-

Flash读取数据库中的数据
Flash读取数据库中的数据 要读取数据库的记录,首先需要建立一个数据库,并输入一些数据。数据库建立完毕后,由Flash向ASP提交请求,ASP根据请求对数据库进行操作后将结果返回给Flash,Flash以某种方式把结果显示出来。 1.启动Access2003,新建一名为“userInfo.mdb”的数据库,
-
Spark 数据读取保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统: 文件格式: Text 文件、 Json 文件、 csv 文件、 Sequence 文件以及 Object 文件 文件系统:本地文件系统、 HDFS、Hbase 以及数据库 text/hdfs 类型的文件读都可以用 textFile(path) ,保存使用 saveAsTextFile(path)
-
MATLAB——Excel数据读取
数据修改后要保存,不然读取的数据一直是未修改的 http://t.csdn.cn/3Ijkh http://t.csdn.cn/VDOkL
-
geotools读取shp数据
pom依赖 读取shp将几何要素转换为wkt
-

微信小程序-读取数据
在开发微信小程序的时候,我们经常都会用到一些配置数据,或者当做“单向数据库(只读)”使用。 我们新建一个新的项目工程,JS版本就可以。 免于麻烦,我们新建一个page(showdata)来显示数据。 为了方便管理,我们在项目工程新建一个目录(data),用于存数据。另外
-

MATLAB从文件读取数据
语法:t=readtable(filename) 支持的扩展名:.txt、.csv、.xls、.xlsm、.xlsx、.xlsm、.xltm、.xltx 结果: 语法:table2array(表格名称) 结果: 结果: 结果: 语法:sheetnames(filename) 结果: 语法:length(filename) 结果: 若想使用table2array函数将表格转换为矩阵,则要保证table中各个变
-
Request Body数据读取
拦截器要读取request body数据的话需要注意一个问题,一旦拦截器把数据流从request读取出来后,后区的接口层就拿不到数据了,因为流是一次性的,那么要解决这个问题,我们就需要在拦截器取出流拿到数据后重新将数据放回流,这样后面的接口层就能正常获取到数据了 下面
-
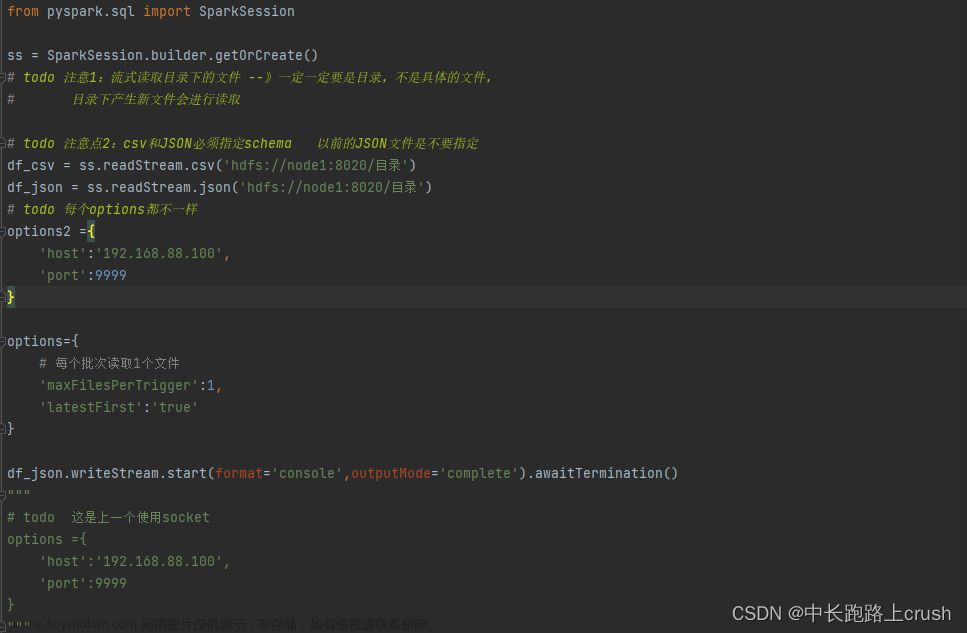
Spark流式读取文件数据
流式读取文件数据 from pyspark.sql import SparkSession ss = SparkSession.builder.getOrCreate() df_csv = ss.readStream.csv(‘hdfs://node1:8020/目录’) df_json = ss.readStream.json(‘hdfs://node1:8020/目录’) options2 ={ ‘host’:‘192.168.88.100’, ‘port’:9999 } options={ # 每个批次读取1个文件 ‘maxFilesPerTrigger’:1, ‘lat