python实现百度语音识别功能
-
OpenAI Whisper 语音识别 API 模型使用 | python 语音识别
OpenAI 除了 ChatGPT 的 GPT3.5 API 更新之外,又推出了一个 Whisper 的语音识别模型。支持96种语言。 Python 安装 openai 库后,把需要翻译的音频目录放进去,运行程序即可生成音频对应的文字。 以上。
-
Java与智能语音识别:实现准确的语音识别与转换
Java与智能语音识别是指利用Java编程语言和智能语音处理技术实现准确的语音识别和转换。下面是一个详细的教程,介绍了如何使用Java构建智能语音识别系统: 1. 音频数据采集: - 使用Java提供的音频采集库(如Java Sound API)获取音频数据流。 - 连接麦克风设备或读取
-
UE4_UE5结合offline voice recognition插件做语音识别功能
市面上主流的语音识别大多是用科大讯飞的SDK,但是那个也不是完全免费使用的,于是我选择使用offline voice recognition的语音识别,购买插件终生使用。 offline voice recognition插件在UE官方商城卖200多元。 我将它需要的资源都打包成一个rar,分享给有需要的人。 其中
-

【花雕动手做】ASRPRO-Plus语音识别(03)---板载硬件模块和12项综合应用功能
ASRPRO-Plus 开发板:是一款全功能带语音识别的物联网开发板,它可以方便的进行系统学习和各种项目实验。板载 RS485、433M 无线收发、红外收发、ESP32-C3(2.4GHz Wi-Fi 和 Bluetooth 5LE)、SPI 彩屏、数码管、RGB 灯、光敏传感器、DHT11 温湿度传感器、1 路继电器输出模块等。 硬件功能分
-

python 语音识别
在python中训练一个语音识别系统主要需要以下几个步骤: - 语料库准备 - 数据预处理 - 特征提取 - 训练模型 第一部分:语料库的准备 什么是语料库?语料库长什么样? 语料库由两部分组成,第一部分是语音,第二部分是玉莹的标注,通常为字符形式。本次项目中
-

python语音识别whisper
一、背景 最近想提取一些视频的字幕,语音文案,研究了一波 二、whisper语音识别 Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 stable-ts在 OpenAI 的 Whisper 之上修改并添加
-

【语音识别】落地实现--离线智能语音助手
参考:基于python和深度学习(语音识别、NLP)实现本地离线智能语音控制终端(带聊天功能和家居控制功能) 基于V3S的语音助手(三)移植pocketsphnix唤醒 基于V3S的语音助手(二)移植pyaudio到开发板 基于V3S的语音助手(一)python3的编译和安装(该版本解决zlib readline可
-
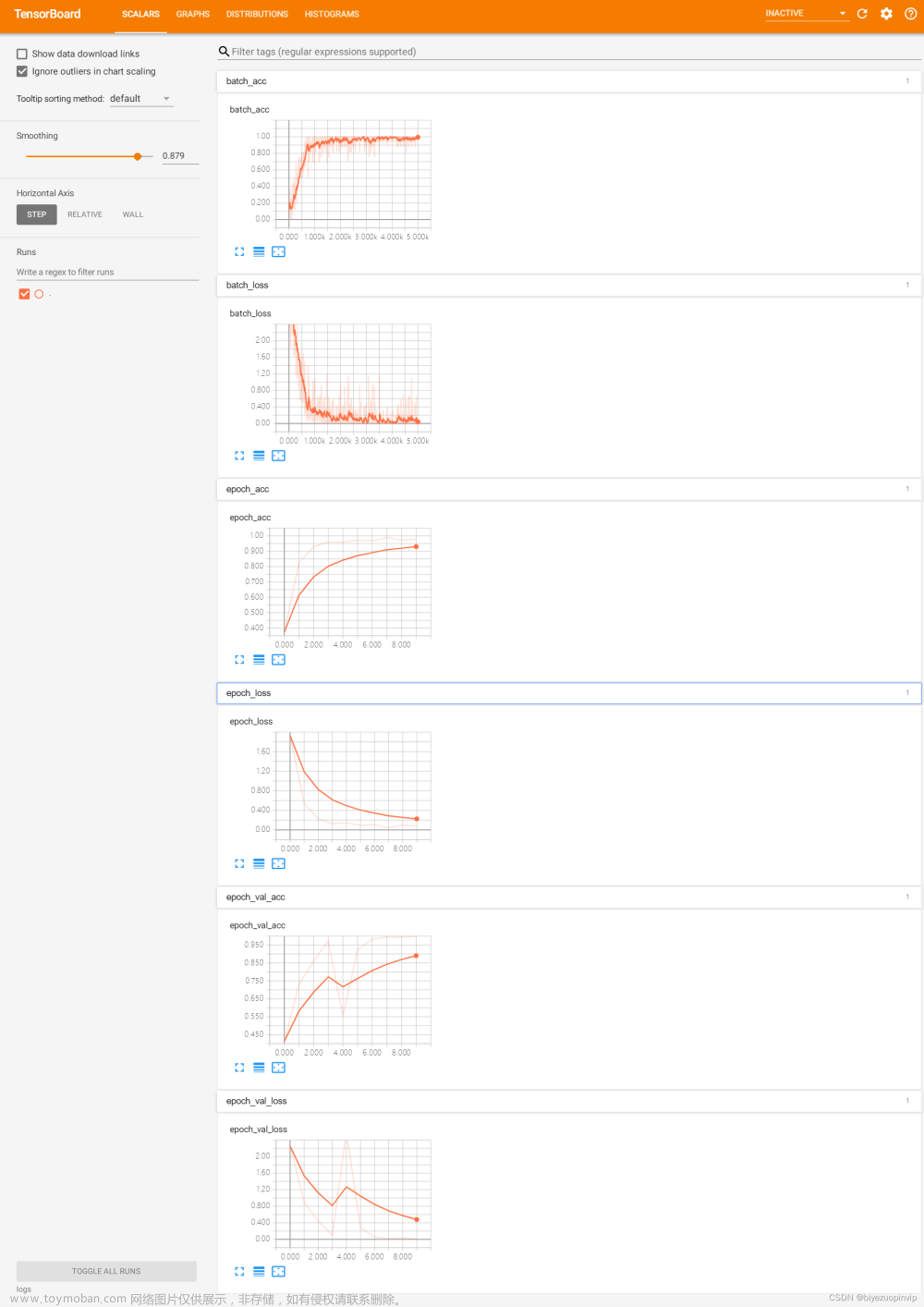
基于Python的语音识别系统
基于Python的语音识别系统的设计与实现 摘 要 随着互联网的发展,语音文件成为了人们接触得越来越多文件。如何高效的从一段录音中提取出关键信息,提取出其中人们感兴趣的内容,直观的呈现给人门。本文以DFSMN作为声学模型,引入TensorFlowr模型,将语音识别转化为翻译任
-
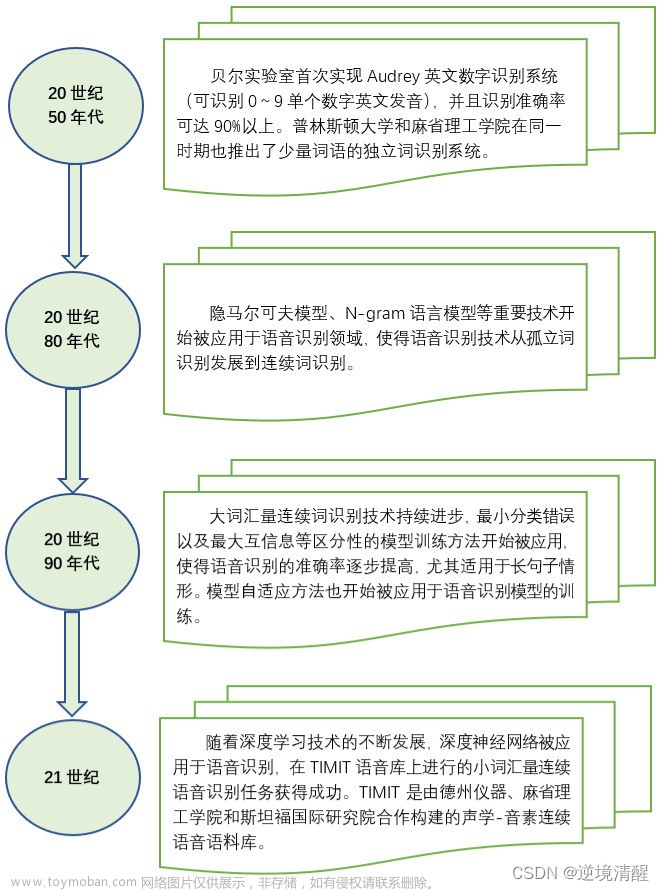
语音识别实战(python代码)(一)
(python :pyttsx、SAPI、SpeechLib实例代码)(一) 本文目录: 一、语音识别的基本原理 (1)、语音识别的起源与发展 (2)、语音识别的基本原理 (3)、语音识别过程 (4)、语音识别的近期发展 二、Python 语音识别 (1)、文本转换为语音 (2)、文本转存为语音文件wav 三、总结
-
使用Python进行自动语音识别
自动语音识别(ASR)是将口头语言转换为书面文本的过程。 ASR技术已经存在多年,但随着机器学习和深度神经网络的进步,它变得更加准确可靠。在本文中,我们将探讨如何使用Python和Hugging Face Transformers库执行ASR,同时利用PySide6设计了一个简单的GUI界面,演示如下所示:
-

语音识别与Python编程实践
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。 专栏简介: 本专栏主要研究
-
[python]基于faster whisper实时语音识别语音转文本
语音识别转文本相信很多人都用过,不管是手机自带,还是腾讯视频都附带有此功能,今天简单说下: faster whisper地址: https://github.com/SYSTRAN/faster-whisper https://link.zhihu.com/?target=https%3A//github.com/SYSTRAN/faster-whisper 实现功能: 从麦克风获取声音进行实时语音识别转文本 代码仅仅
-

语音识别(利用python将语音转化为文字)(升级版)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 基于语音识别(1)进行的完善,修改了60秒断触的问题,另外可以更加方便的调用,语音识别1的链接如下: https://blog.csdn.net/m0_46657126/article/details/124531081 https://www.xfyun.cn/ ps:注册账户是完全免费的,因
-

Java 离线语音识别实现语音转文字
model下载 我们需要实现离线语音识别,那么就得将模型下载到本地电脑。下载地址为官网的 Models 模块: https://alphacephei.com/vosk/models 我们直接找到 Chinese 分类,这里有 2 个模型 将下载的语言模型包,在下面代码中引入 代码 CommonUtils 注意:以上代码只支持.wav格式的音频文件
-
实时语音识别(Python+HTML实战)
项目下载地址:FunASR 项目提示所需要下载的库文件:pip install -U funasr 和 pip install modelscope 运行过程中,我发现还需要下载以下库文件才能正常运行: 下载:pip install websockets,pip install ffmpeg 运行 FunASR-main/runtime/python/websocket/funasr_wss_server.py 文件,加载模型 注:如果提示缺少
-
矩阵分析与语音识别:实现高效准确的识别
语音识别技术是人工智能领域的一个重要分支,它涉及到语音信号的采集、处理、特征提取和模式识别等多个环节。在过去的几十年里,语音识别技术已经发展得相当成熟,但是在实际应用中仍然存在一些挑战,如高效准确率、语音数据量大、多语言支持等。因此,在这篇文
-
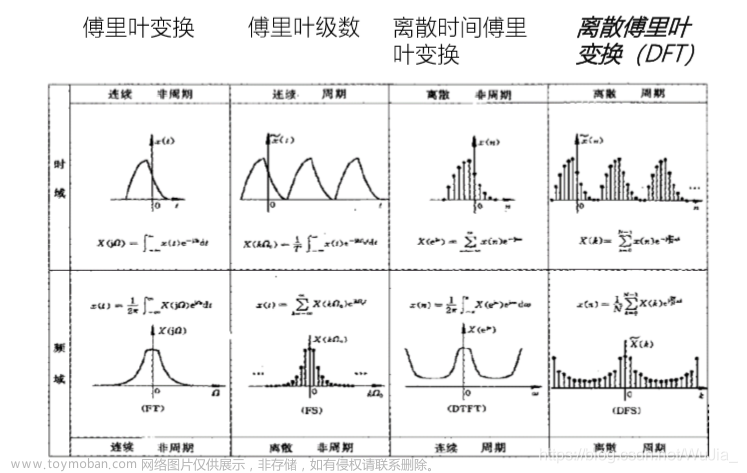
【语音识别入门】特征提取(Python完整代码)
1.1数字信号处理基础 在科学和工程中遇到的大多数信号都是连续模拟信号,例如电压随着时间变化,一天中温度的变化等等,而计算机智能处理离散的信号,因此必须对这些连续的模拟信号进行转化。通过 采样–量化 来转换成数字信号。 以 正弦波 为例: x ( t ) = s i n ( 2 Π
-
Pytorch 实现语音识别系统
作者:禅与计算机程序设计艺术 近年来,随着科技的飞速发展,人工智能(AI)领域也逐渐进入高速发展的时代。随着深度学习的火热,机器学习模型已经不再局限于图像分类、文本分类等简单任务,而是应用到各种各样的领域。因此,语音识别(ASR)系统成为了未来人工智
-
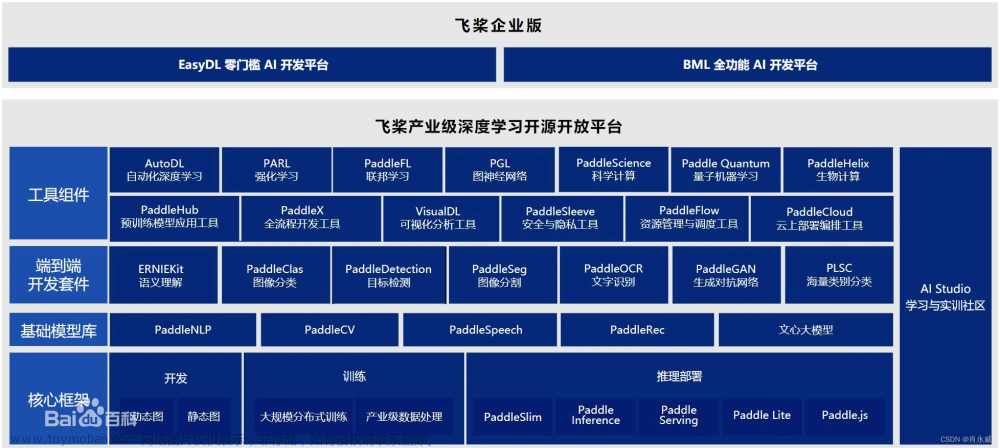
百度飞浆OCR识别表格入门python实践
百度飞桨(PaddlePaddle)是百度推出的一款深度学习平台,旨在为开发者提供强大的深度学习框架和工具。飞桨提供了包括OCR(光学字符识别)在内的多种功能,可以帮助开发者在各种应用中实现高效的文本识别。官网链接:https://www.paddlepaddle.org.cn/。 初次使用,安装: pip i
-
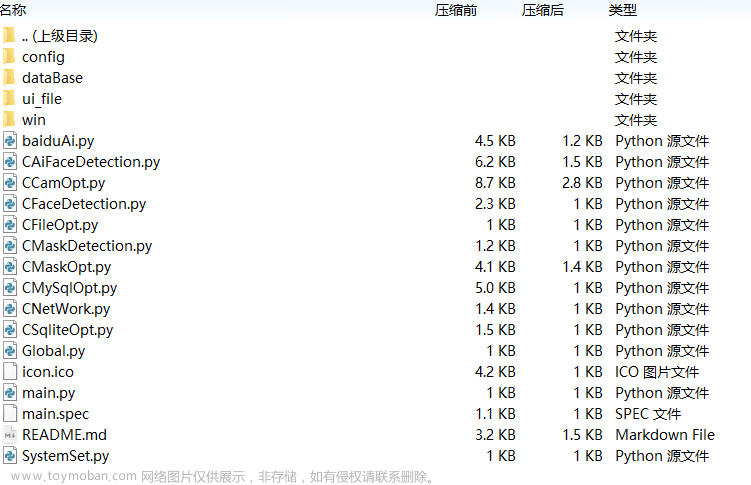
基于Qt、PYTHON智能校园防御系统应用程序,实现了摄像头数据采集、人脸识别、口罩识别、 数据统计等功能
完整项目地址:https://download.csdn.net/download/lijunhcn/88453470 项目结构 环境选型 语言:Python 操作系统:Windows 数据库:MySQL 窗口界面:PyQT API接口:百度AI接口,用以实现人脸登陆与注册 远程MySQL表结构 远程表结构sql脚本 项目背景 智能校园防御软件是实现了一款基于摄像头数据