python实现语音识别对错了
-

python_视频中语音识别转出文本
注意:没有“stepladder”的同学建议不要看啦 目录 1. 安装需要的包 2. 视频转音频 3. 对音频进行切割 4. 对视频进行切割 5. 从音频中识别出文本 5.1 使用离线方法 5.2 使用在线方法 5.3 两种方法比较 6. 用到的包下载 1.1 安装SpeechRecognition包 pip install SpeechRecognition 1.2 安装 PockSphin
-
ESP32 Tensorflow 实现语音识别
教程介绍 如何 通过外部麦克风 I2S 将 Tensorflow 微语音与 ESP32 结合使用。换句话说,我们想要定制 Tensorflow 微语音示例,以便它在使用 I2S 协议连接到外部麦克风的 ESP32 上运行。在本例中,我们将使用连接到 ESP32 的 INMP441 来捕获音频。虽然 ESP32-EYE 具有内置麦克风,但如果我
-

深入探究语音识别技术:原理、应用与实现
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博相关......)👈 (封面图由文心一格生成) 随着人工智能的快速发展,语音识别技术得到了
-

C#使用WhisperNet实现语音识别功能
C#使用WhisperNet实现语音识别功能 最近想做一下本地音频语音识别工具,在网上找了一些本地音频语音识别方面的资料。 Whisper 是 OpenAI 的一种自动最先进的语音识别系统,它已经接受了 680000 小时 从网络收集的多语言和多任务监督数据的训练。这个庞大而多样化的数据集提高
-

FreeSWITCH对接vosk实现实时语音识别
环境:CentOS 7.6_x64 FreeSWITCH版本 :1.10.9 Python版本:3.9.2 vosk是一个开源语音识别工具,可识别中文,之前介绍过python使用vosk进行中文语音识别,今天记录下FreeSWITCH对接vosk实现实时语音识别。 vosk离线语音识别可参考我之前写的文章: python使用vosk进行中文语音识别 可直接使用
-

实现语音识别系统:手把手教你使用STM32C8T6和LD3320(SPI通信版)实现语音识别
本文实际是对LD3320(SPI通信版)的个人理解,如果单论代码和开发板的资料而言,其实当你购买LD3320的时候,卖家已然提供了很多资料。我在大学期间曾经多次使用LD3320芯片的开发板用于设计系统,我在我的毕业设计作品中也有添加这个系统功能,用于添加整个系
-
MATLAB在语音合成与语音识别中的应用方法与算法实现
近年来,随着人工智能技术的迅猛发展,语音合成与语音识别技术逐渐成为热门研究领域。而MATLAB作为一款专业且强大的科学计算软件,在语音合成与语音识别的应用中发挥着重要的作用。本文将介绍MATLAB在语音合成与语音识别中的应用方法与算法实现,并探讨其
-
vue项目,实现语音识别文字,前后端交互
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 最近实现一个录音上传功能,并且识别语音转为汉字。 js-audio-recorder是基于第三方的vue插件,实现录音,播放等功能。 代码如下(示例): 代码如下(示例): 该处使用的url网络请求的数据。 前端调
-

Python吴恩达深度学习作业24 -- 语音识别关键字
在本周的视频中,你学习了如何将深度学习应用于语音识别。在此作业中,你将构建语音数据集并实现用于检测(有时也称为唤醒词或触发词检测)的算法。识别是一项技术,可让诸如Amazon Alexa,Google Home,Apple Siri和Baidu DuerOS之类的设备在听到某个特定单词时回
-
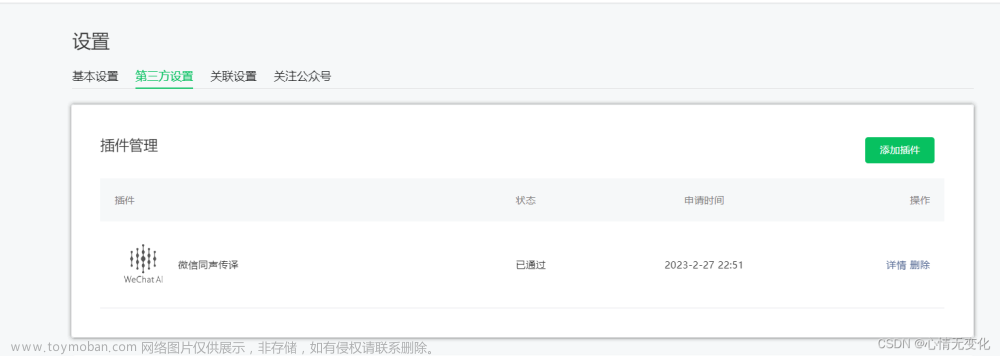
小程序中使用微信同声传译插件实现语音识别、语音合成、文本翻译功能----语音合成(二)
官方文档链接:https://mp.weixin.qq.com/wxopen/plugindevdoc?appid=wx069ba97219f66d99token=370941954lang=zh_CN#- 要使用插件需要先在小程序管理后台的 设置-第三方设置-插件管理 中添加插件,目前该插件仅认证后的小程序。 语音合成支持的语言有 zh_CN(中国大陆),en_US(英文)。 参数说明: 1、
-

springboot整合vosk实现简单的语音识别功能
Vosk是开源的语音识别工具包。Vosk支持的事情包括: 支持十九种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语。 移动设备上脱机工作
-

基于深度学习的语音识别算法的设计与实现
收藏和点赞,您的关注是我创作的动力 语音识别(Speech Recognition)是一种让机器通过识别音频把语音信号转变为相 应的文本或命令的技术语音识别技术主要有模式匹配识别法,声学特征提取,声学模型 建模 ,语言模型建模等技术组成。借助机器学习领域中的深度学习的
-

基于TensorFlow实现的自动语音识别(附项目资源)
目录 0 概要 1 自动语音识别 1.1 简介 1.2 技术原理 1.3 数据集 2 实现 2.1 导入依赖库 2.2 加载数据集 2.2.1 加载文本标注路径并查看 2.2.2 提取文本标注和语音文件路径,保留中文并去掉空格 2.3 音频数据的加载、处理和可视化 2.4 建立字典 2.5 划分数据集 2.5.1 划分训练数据和测试
-

Unity+chatgpt+webgl实现声音录制+语音识别
AI二次元女友这个项目持续更新,在window端的语音识别和语音合成的功能,在上一篇博文里已经详细说明了微软Azure语音服务的代码实现。也是为了实现一次代码,多端复用这样的诉求,所以全部的代码实现都改成了web api的方式。然而在实测发布到webgl的时候,就发现
-
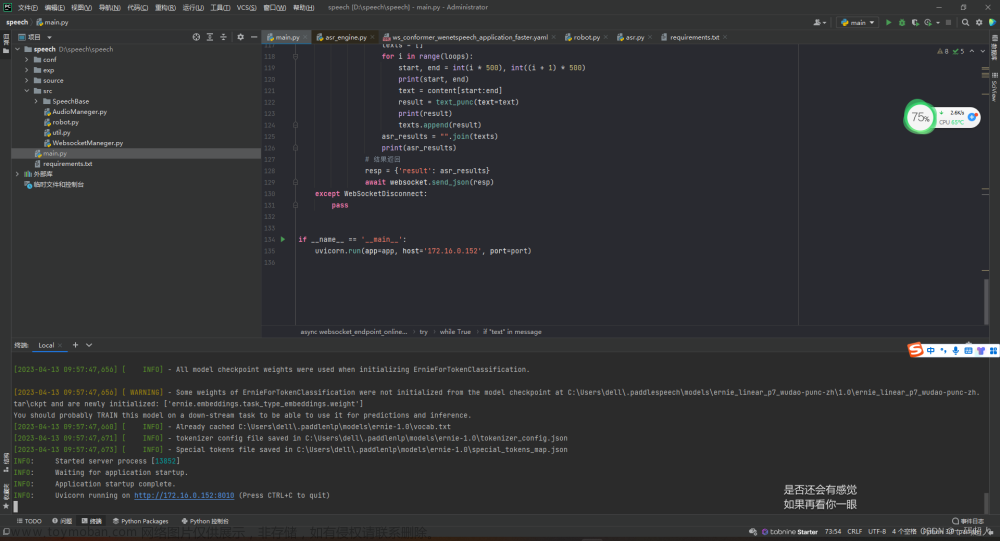
百度飞桨paddlespeech实现小程序实时语音流识别
前言: 哈哈,这是我2023年4月份的公司作业。如果仅仅是简单的语音识别倒也没什么难度,wav文件直接走模型输出结果的事。可是注意标题,流式识别、实时! 那么不得不说一下流式的优点了。 1、解决内存溢出的烦恼。 2、打算做成无文件生成,接收语音流直接走模型,减
-
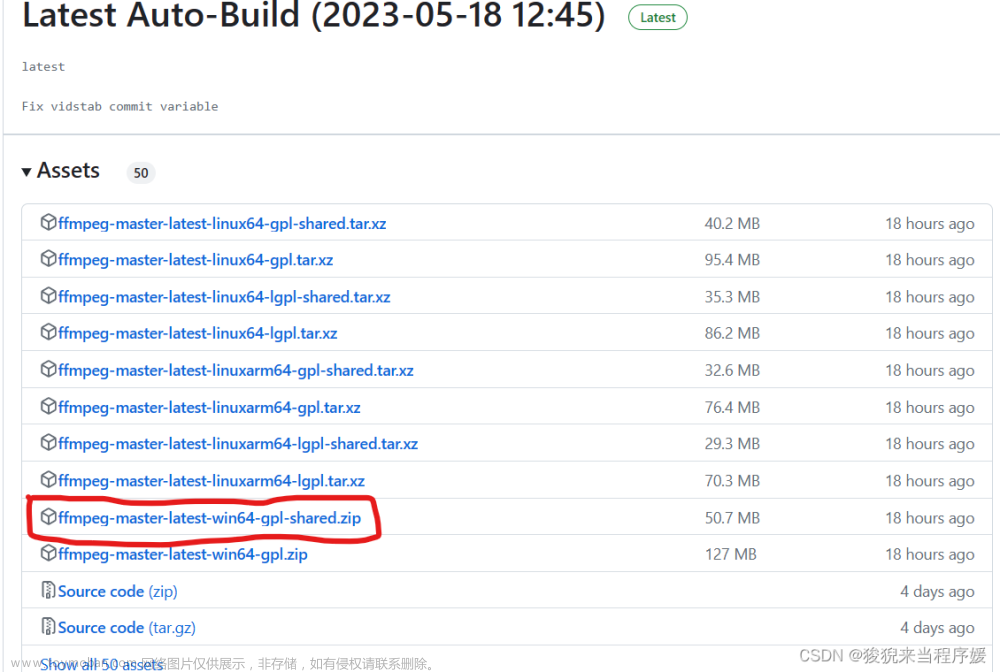
OpenAI开源!!Whisper语音识别实战!!【环境配置+代码实现】
目录 环境配置 代码实现 ****** 实现 .mp4转换为 .wav文件,识别后进行匹配并输出出现的次数 ****** 完整代码实现请私信 安装 ffmpeg 打开网址 https://github.com/BtbN/FFmpeg-Builds/releases 下载如下图所示的文件 下载后解压 我的路径是G:ffmpeg-master-latest-win64-gpl-shared
-

鸿蒙应用开发-录音并使用WebSocket实现实时语音识别
功能介绍: 录音并实时获取RAW的音频格式数据,利用WebSocket上传数据到服务器,并实时获取语音识别结果,参考文档使用AudioCapturer开发音频录制功能(ArkTS),更详细接口信息请查看接口文档:AudioCapturer8+和@ohos.net.webSocket (WebSocket连接)。 知识点: 熟悉使用AudioCapturer录音并实时
-
AI智能机器人的语音识别是如何实现的 ?
什么是智能语音识别系统?语音识别实际就是将人类说话的内容和意思转化为计算机可读的输入,例如按键、二进制编码或者字符序列等。与说话人的识别不同,后者主要是识别和确认发出语音的人并非其中所包含的内容。语音识别的目的就是让机器人听懂人类所说的语言,
-
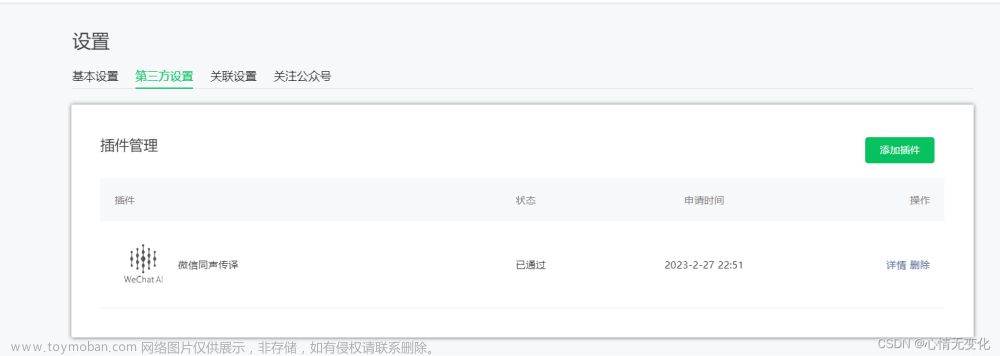
小程序中使用微信同声传译插件实现语音识别、语音合成、文本翻译功能----文本翻译(三)
官方文档链接:https://mp.weixin.qq.com/wxopen/plugindevdoc?appid=wx069ba97219f66d99token=370941954lang=zh_CN#- 要使用插件需要先在小程序管理后台的 设置-第三方设置-插件管理 中添加插件,目前该插件仅认证后的小程序。 文本翻译目前支持的语言有 zh_CN(中国大陆) en_US(英语)。 参数说明:
-

Whisper对于中文语音识别与转写中文文本优化的实践(Python3.10)
阿里的FunAsr对Whisper中文领域的转写能力造成了一定的挑战,但实际上,Whisper的使用者完全可以针对中文的语音做一些优化的措施,换句话说,Whisper的“默认”形态可能在中文领域斗不过FunAsr,但是经过中文特殊优化的Whisper就未必了。 Whisper经常被人诟病的一点是对中文语音