torch.backends.cudnn.determine
-
cgo踩坑:交叉编译过程出现的问题could not determine kind of name for C.XXX
尝试了网上的几种解决方法,都不行,现总结起来: 确认 不要有空行 确认你引用的头文件存在(stdio.h这种编译器自带的不需要你确认) 如果引用了多个包,必须将c和go的包分开引用: 比如
-
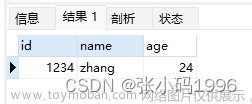
Mybaits:数据库查询类型不匹配,java.sql.SQLDataException: Cannot determine value type from string
目录 一.问题描述 二.源码分析 三.总结 事情的起因是用MybaitsPlus查询数据库过程中,查询结果与要封装的实体类字段类型对应不上,类似这样: 数据库查询结果: java实体类: 字段名字和实体类的名字类型都能对应上,但最后的查询结果却会报错java.sql.SQLDataException: Cannot d
-
vcs import src < ros2.repos 显示 Could not determine ref type of version
根据ROS2的官方编译教程步骤下载ROS包时,到vcs import src ros2.repos 或 vcs import --input ros2.repos src这一步就会报错或者下载速度极慢。一开始是会显示Could not determine ref type of version: fatal: unable to access ‘https://github.com/ros-visualization/rqt_graph.git/’: Failed to connect to github.com port 443: Conn
-

已解决ValueError: Excel file format cannot be determined, you must specify an engine manually.
已解决ValueError: Excel file format cannot be determined, you must specify an engine manually. 粉丝群里面的一个小伙伴遇到问题跑来私信我,想用Pandas读取Excel,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个
-

Stable Diffusion本地部署报错解决:RuntimeError: Couldn‘t determine Stable Diffusion‘s hash: xxxxxxx
升级git版本等都没有解决的话,看这里! 找到stable-diffusion-webuimoduleslaunch_utils.py,打开,搜索 current_hash (当前是第151行): 原内容: 改成: 如果有用记得赞赏一下哟~
-
报错解决ValueError: did not find a match in any of xarray‘s currently installed IO backends
最近在服务器上配置环境遇到了xarray读取nc数据的相关问题,折腾了一下午终于解决了,记录下来,希望帮助后来人。具体报错如下 想要解决该问题只需要 两步: 【1】下载相关依赖包 可以发现已经明显提示了 缺少IO backends ,可到给出的网址中寻求解答。
-
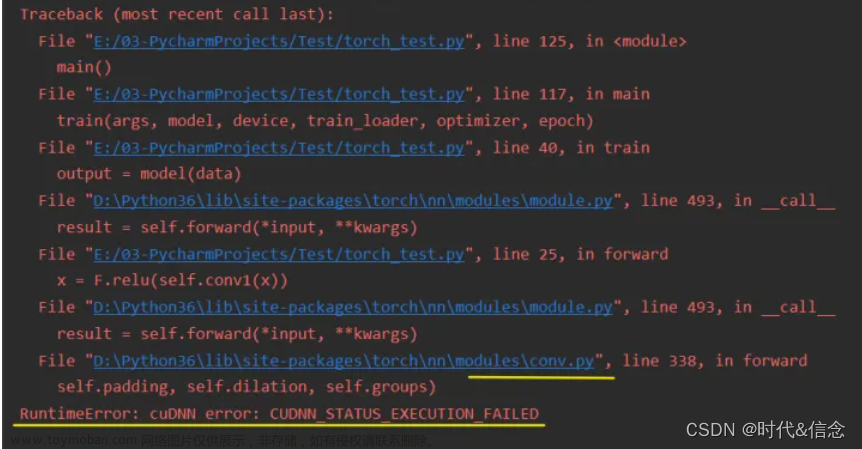
RuntimeError:cuDNN error:CUDNN_STATUS_EXECUTION_FAILED
最近在服务器上跑Deeplabv3进行语义分割时,需要使用GPU版的pytorch。 我在Anaconda下配置了适配服务器CUDA的pytorch,但是报错如下,(下图无限接近于我的错误,但是我忘记截图我的报错了,所以用了下面这张网图) 可以看到每次报错都在 conv.py 这个文件,就是在做 CNN 运算时出
-

解决:Python通过pip安装库时报错:ERROR: Cannot unpack file ...; ERROR: Cannot determine archive format of ...
在使用之前的代码时,报错: ERROR: Cannot unpack file C:UsersMatchaAppDataLocalTemppip-unpack-qdrm7q1esimple.htm (downloaded from C:UsersMatchaAppDataLocalTemppip-req-build-xkgrt0zv, content-type: text/html); cannot detect archive format ERROR: Cannot determine archive format of C:UsersMatchaAppDataLocalTemppip-req-build-xkgrt0
-
NVIDIA显卡BUG解决 Unable to determine the device handle for GPU 0000:02:00.0: Unknown Error
实验室去年到今年断了几次电,然后服务器上的2080Ti一直就感觉有点小毛病。属于是被折磨了几个月了。 然后前两周断电后,显卡就基本上完全用不了了,经常服务器开机都会失败。并且 就算服务器开机成功过后,没有几分钟显卡就会自己关掉 刚刚开机一切都很正常 但是没
-
使用skvideo.io.vread读取avi视频,报错“No way to determine width or height from video...”
问题描述: 一开始安装sk-video,在使用skvideo.io.vread读取avi视频,报错“No way to determine width or height from video. Need `-s` in `inputdict`. Consult documentation on I/O.” 解决方案: 1. 卸载sk-video 2. 安装skicit-video 3. 安装ffmpeg 4. 查看ffmpeg存储路径 5. 测试是否安装成功 成功!!!正确输出avi视
-

【Python】Pandas Excel file format cannot be determined, you must specify an engine manually.报错【已解决】
根据Python官网,Python3.7还支持WIN7。 项目对应的requirements.txt为: 项目对应的nuitka命令为: 报错主要是PySide6与matplotlib之间接口兼容性的问题。报错位置代码 根据gpt, 根据matplotlib官方issues,解决方案是, mpl 升级到 =3.6.2 或将 pyside 降级到 6.4.0 Python3.7下matplotlib,最高支持3.5,
-

改变hive的端口8020到9000。(SemanticException Unable to determine if hdfs://node1:8020/user/hive/warehouse)
本人的情况是把Hadoop的hdfs的端口号改为9000,后原本的能用的hive出现这个错 Hive在执行某个操作(可能是在查询、加载数据或者写入数据到表中)时,试图连接到HDFS Namenode服务(位于node1:8020)。 所以我们要改一下hive的这个端口号,把他也改变成9000。同时因为原来是的数据都
-
backend.js:748 An error occurred in hook ‘getInspectorState‘ registered by plugin ‘org.vuejs.vue2-in
问题 vue项目控制台操报错 backend.js:748 An error occurred in hook \\\'getInspectorState\\\' registered by plugin \\\'org.vuejs.vue2-internal\\\' with payload: 出现这个问题是你的Vue.js devtools版本搞错了 解决 重新下载插件 旧版本下载 确保禁用任何其他版本的 Vue 开发工具。一次只能启用一个版本。
-

NVIDIA-SMI报错:Unable to determine the device handle for GPU 0000:XX:00.0: Unknown Error
1、首先使用nvidia-smi监管显卡信息: 具体关于nvidia-smi的介绍和使用请参照: nvidia-smi 命令详解_蒙娜丽莎的Java的博客-CSDN博客 nvidia-smi - NVIDIA System Management Interface programnvidia smi(也称为NVSMI)为来自 Fermi 和更高体系结构系列的 nvidia Tesla、Quadro、GRID 和 GeForce 设备提供监控和管
-

解决AH00558: httpd: Could not reliably determine the server‘s fully qualified domain name, using local
一、启动apache遇到这种警告: httpd: Could not reliably determine the server’s fully qualified domain name 二·、修改配置 [root@localhost conf.d]# vim /etc/httpd/conf/httpd.conf #ServerName www.example.com:80 //找到ServerName这一行 改成:ServerName localhost:80 或者去掉“#” 二·、重启httpd服务:#systemctl rest
-

【】解决minio启动报ERROR Unable to use the drive ** found backend type fs, expected xl or xl-single
由于minio报了一个安全漏洞(MinIO verify 接口敏感信息泄露漏洞分析(CVE-2023-28432)_minio 漏洞_超酸柠檬的博客-CSDN博客),以至于公司需要升级minio版本,但是我发现使用最新版本的minio后minio无法正常启动了。由于之前就是单机部署,因此这次还是单机部署,结果却启动不起来了
-
go mod init 在初始化时出现 cannot determine module path for source directory (outside GOPATH,module path)
新创建的golang项目,使用 go mod init 命令时出现 cannot determine module path for source directory xxxxxxx (outside GOPATH, module path must be specified) 这是因为go mod init 初始化项目时,需要定义一个 module ,当打开一个 go.mod 文件,就会发现第一行就有 因此,在执行 go mod init 时需要定义 module,如:
-
【TensorRT】TensorRT was linked against cudnn 8.6.0 but loaded cudnn 8.3.2
文章指引:Win10 安装 Tensorrt和torch2trt教程 系统 :Win10 显卡 :NVIDIA GeForce RTX 3090 cuda版本 :CUDA 11.6.2 python版本 :3.9 TensorRT安装版本 :8.5.1.7 在使用TensorRT-8.5.1.7,发布模型和推理发布的trt模型时出现警告,TensorRT was linked against cudnn 8.6.0 but loaded cudnn 8.3.2 (类似问题见文章 [1] )
-
【Pytorch报错】RuntimeError:cuDNN error:CUDNN_STATUS_INTERNAL_ERROR 高效理解记录及解决!
明明跑了一段时间?跑过一次完整的?怎么就出现这个报错呢?代码也未改动?而这就是现实! 观察显卡使用情况,多人共用同一服务器,项目各自运行,会抢占显存,进而报错! 多个项目运行,占用增加,导致内存用完报错,还是很真实的! 文件是否设置了CUDA_VISIBLE_DE
-
cuDNN安装方法
• 1、下载cuDNN • 2、安装cuDNN • 3、检查当前cuDNN 1、下载cuDNN 链接https://developer.nvidia.com/cudnn-download-survey 选择版本时,需要根据操作系统选择和cuda版本匹配的cuDNN 2、安装cuDNN 解压下载好的cuDNN tar -xvf cudnn-11.2-linux-x64-v8.1.0.77.tgz 拷贝文件到对应的目录 cp include/cudnn.h /usr/local/